Active IQ Unified Manager Discussions
- Home
- :
- Active IQ and AutoSupport
- :
- Active IQ Unified Manager Discussions
- :
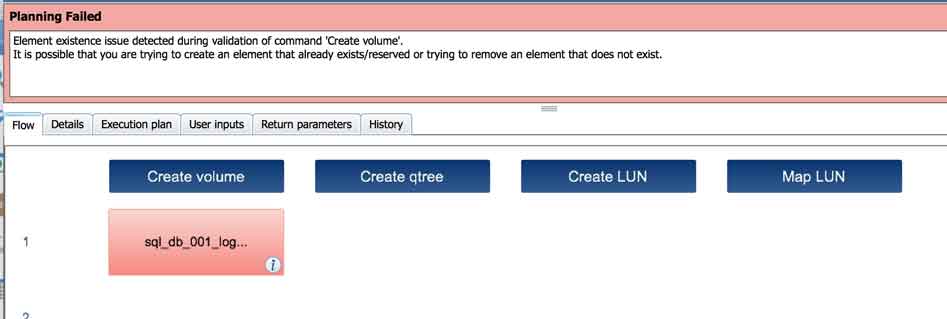
- Element existence issue detected during validation of command 'Create volume'.
Active IQ Unified Manager Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Element existence issue detected during validation of command 'Create volume'.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Debugging a new workflow that:
- creates volume
- creates qtree
- creates LUN
- maps LUN
First execute attempt failed on the map LUN cmd. I corrected that problem and also went to the array and offline/destroyed the volume that had been created (to prevent a duplicate volume name when running again). Then when attempting to re-Execute the workflow get this error (see attached) attempting to create the volume. Doesn't make sense since I've gotten rid of the volume created on 1st run. What am I missing?
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Korns,
you have a delay between NetApp Filer and DFM. Also between DFM and the WFA Database.
Please check the update interval from your DFM collection and your WFA->DFM collection.
The information stored in the mysql database of the WFA is not up to date yet.
Start a new collection from your DFM and the problem should be solved.
Cheers,
Chris
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Korns,
you have a delay between NetApp Filer and DFM. Also between DFM and the WFA Database.
Please check the update interval from your DFM collection and your WFA->DFM collection.
The information stored in the mysql database of the WFA is not up to date yet.
Start a new collection from your DFM and the problem should be solved.
Cheers,
Chris
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Korns,
To add to christian's answer, WFA has something called as "reservations".
When you created the volume, it got created on the filer and a reservation was made for that volume in the WFA DB. Which means, WFA now thinks that you have a volume by that name on the filer. It is unaware that you went directly to the filer CLI and destroyed the volume.
Therefore it says that the volume exists.
You can change the volume name and try again or do data acquisitions in DFM and in turn WFA as mentioned by christian. This will solve the issue.
-Anil
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
As I understand your workflow is using certified commands like "Create volume/qtree/LUN". All these commands have reservations enabled. This means that WFA reserves the changes the commands intends to do.
Using these reservation concept, WFA also pre-verifies during planning if an element that is being created/modified/deleted is actually already present or already deleted. This is the flag in Workflow Setup named "Enable element existence ..". This basically means that the planning will consider all reserved objects in the system along with the direct objects available in the cache for doing this check.
- When the first attempt to execute the workflow failed, the reservations were already stored.
- These will have to be explicitly deleted considering the fact that you went to ONTAP shell and fixed the issues that led to the failure.
- For a failed workflow execution, WFA does not automatically delete the reservation since we let the administrator understand the failure, do any
necessary clean-up on the storage systems and then explicitly indicate by cleaning the reservations.
- You can go to Execution -> Reservations window, see the failed job id and clean the reservations there.
- After that when you re-attempt to execute the workflow with the same volume
name it should be fine.
Please check it out and let us know.
Some other older helpful posts on similar topics:
https://communities.netapp.com/message/110637#110637
https://communities.netapp.com/message/102737#102737
Hope this helps.
Thanks,
Shailaja
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, that explains some other features I didn't fully understand.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Shailaja is 100% correct. This is not an issue with acquisition because of one thing. In your original post, you stated that you manually (this is important) deleted the volume after the workflow execution failed on the lun map command. As Shailaja pointed out, the reservations table comes into play here. The reason the DFM acquisition would not help is that the only place that the element exists is in the WFA reservation table (marked as a failed job). Since you deleted the volume manually, it will never be updated. The default time for a failed reservation being cleaned up is like 4hrs (I think).
Anyway, if you have a failure again. Either, use WFA to clean up or if you need to manually clean up then clear the reservations.
Jeremy Goodrum, NetApp
The Pirate
Twitter: @virtpirate
Blog: www.virtpirate.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks all. You are correct but it was harder to correct than just doing a simple WFA acquire. I suspect the polling/acquisition intervals of both OCUM and WFA come into play. I tried to force a OCUM polling update, paused, then did a WFA acquire but still got the error. I was able to re-Execute the workflow using different volume name(s) but it wasn't until the next morning that I could re-Execute using the same original volume name. I think I understand the nature of problem next time I encounter it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Korns,
The reason why just a update from OCUM to WFA as well didnot work is because the way OCUM take to refresh or remove deleted entries from controller to its db.
An object on the controller is discovered in OCUM, and when that gets deleted on the controllers, OCUM doesn't remove it from its database or mark it deleted until 1 hour or 4 cycle of discovery.
This should not be the case it OCUM 6.x, but I think in your case it was 7Mode. Correct me if I am wrong.
Regards
adai


{kind=link}
