This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
Active IQ Unified Manager Discussions
- Home
- :
- Active IQ and AutoSupport
- :
- Active IQ Unified Manager Discussions
- :
- Re: array_id documentation?
Active IQ Unified Manager Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
first of all, WFA 2.0 is really nice - great work on the improvements over the 1.x releases!
A quick question...am I missing the documentation on the array_id column that seems to be present in most of the cache tables? The dictionary entries do not list a column for the array_id value, yet it appears that it is magically there for many tables. I was really confused when looking at the example for a query user input when it referenced this array_id value that doesn't actually show up as a documented column in the tables. Am I missing this somewhere in the docs? I'd like to know where this column exists, or know if it exists in every cache table? Thanks!
Mike
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mike,
Let me rollback one of my statements and rephrase it:
ID is an internal use column. It's value should not be used as a user input or something of the sort.
However, the column itself is used for widely correlation purposes in filters and user input queries
1) A query to show all aggregates whos name is not "aggr0" - return their name and array that they are in
select aggr.name, array.ip
from storage.aggregate aggr, storage.array array
where
array.id = aggr.array_id <== This is the correlation
and
aggr.name <> 'aggr0'
2) A query to fetch all aggregates in a specific array whose name is given - return their name and array that they are in (A user input query)
select aggr.name, array.ip
from storage.aggregate aggr, storage.array array
where
array.id = aggr.array_id <== This is the correlation
and
array.name = '${Hostname}'
Both uses of the id column(s) are fine in this context.
Now, the relation between dictionary entries structure and the cache tables is not 1:1. Most columns are named the same way, but the object references ("array" in aggregate dictionary entry is an object reference not the array name or ip!)
are replaced by id columns.
The best and easiest way to see it is to look at the schema via the Read-only user that I shared in the previous message.
Hope that's less confusing now 🙂
Cheers,
Yaron
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Mike,
The screenshot seen below has the parameter that is mapped to array_id.
The array_id picked up from DFM through relevant query is translated to the id assigned in the WFA database.
This entry is seen in dictionary of objects refer the array; eg:volume,lun,igroup,etc
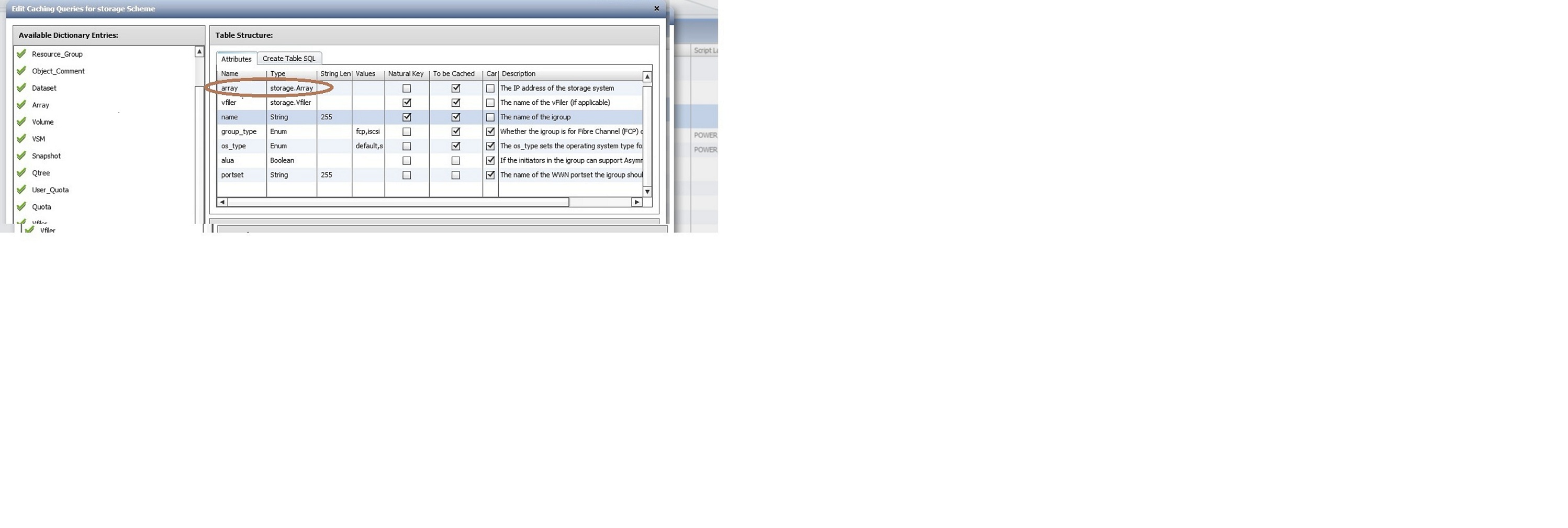
Hope this answers your question.
-Sharu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
HI Mike,
Very glad to hear that you are finding it nice..!
The array_id is nothing but reference to id column in Array table(foreign key). That you can find it in one of the cache table column like, in the aggregate cache table query ( Datasource Types->On Command UnifiedManager-> storage->Aggregate table-> "create table sql") as below
CREATE TABLE `storage`.`aggregate` (
`id` INT NOT NULL AUTO_INCREMENT ,
`name` VARCHAR(255) NOT NULL ,
`total_size_mb` BIGINT NOT NULL ,
`used_size_mb` BIGINT NOT NULL ,
`available_size_mb` BIGINT NOT NULL ,
`volume_count` INT NOT NULL ,
`status` VARCHAR(255) DEFAULT NULL ,
`array_id` INT NOT NULL , <<-----------------------------
`block_type` VARCHAR(255) COMMENT 'possible values are 32_bit,64_bit' DEFAULT NULL ,
PRIMARY KEY (`id`)
);
In Aggregate dictionary table, it will just listed as Array , not as array_id. You can find it as array_id only in the create cache table query.
In any dictionary table( which is cache-ble) where ever you have a reference that willl be represented as <reference_table_name>_id in the cache table.
BTW, what was the example for a query user input, you were looking..!
Warm Regards
Sivaprasad K
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK...then I'm just wondering why we don't show the array column as array_id in the dictionary since that is how we need to use it in a SQL query. I'm assuming that with 2.0, the dictionary is how we found out what the names of the columns are in various tables for our SQL queries, right? For example, here is the query I am using now to limit aggregate selection to those aggregates that belong to a controller that the user has selected in a previous query input:
SELECT aggregate.name
FROM storage.aggregate,storage.array
WHERE aggregate.array_id=array.id AND array.name='${controller1name}'
It was not immediately obvious to me that I need to use aggregate.array_id, since none of the columns listed in the aggregate dictionary entry are given as array_id. I actually tried using aggregate.array at first, since that is what the dictionary seems to indicate the column name should be, but that gave me an error. Thanks,
Mike
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Mike,
Thanks for the show of support and the kind words.
Every cache table has 1 or more ID columns, in either singular form ("id") or as a reference ("volume_id"). The values are assigned by WFA during the data acquisition process. The IDs are used to maintain the relationships between the various objects (For example, "volume_id" column in "qtree" table holds the "id" of a the volume object containing that qtree).
These IDs are considered for internal use only and are not to be used.
They do not appear in the dictionary entry as the dictionary objects are "identified" uniquely by their natural key. For example, Volume is uniquely identified by
its array IP and name, a Qtree is identified by the array IP it is in, the volume that contains it and its name.
The only usage of those columns should be in either the "Where" clause in a SQL statement or as part of a "Join" statement in a filter or a user-input query definition. Alternatively, the natural key of entries can be used for same correlation purposes.
Regardless, your comment is noted and we will open a case to improve the documentation in that aspect.
BTW - There's a Read-only user to the DB that allows you to test your queries on the schema and see it's contents.
Use "wfa/Wfa123" as username/password for access.
Hopes that helps clarifying this.
Cheers,
Yaron Haimsohn
WFA team
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Yaron.
There are two things that I find confusing about this:
-The array_id value is used as an example for a query input in WFA. It seems strange to use that as an example if it is supposed to be for internal use only.
-The column named “array” in the storage.aggregate dictionary entry doesn’t seem to work when used in a SQL query. I can run “select array_id from storage.aggregate”, but I get an error with “select array from storage.aggregate”. So, I’m not sure how I would correlate aggregates to their corresponding array, as I need to in the example SQL query that I give in this thread, without using array_id.
Thanks!
Mike
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mike,
Let me rollback one of my statements and rephrase it:
ID is an internal use column. It's value should not be used as a user input or something of the sort.
However, the column itself is used for widely correlation purposes in filters and user input queries
1) A query to show all aggregates whos name is not "aggr0" - return their name and array that they are in
select aggr.name, array.ip
from storage.aggregate aggr, storage.array array
where
array.id = aggr.array_id <== This is the correlation
and
aggr.name <> 'aggr0'
2) A query to fetch all aggregates in a specific array whose name is given - return their name and array that they are in (A user input query)
select aggr.name, array.ip
from storage.aggregate aggr, storage.array array
where
array.id = aggr.array_id <== This is the correlation
and
array.name = '${Hostname}'
Both uses of the id column(s) are fine in this context.
Now, the relation between dictionary entries structure and the cache tables is not 1:1. Most columns are named the same way, but the object references ("array" in aggregate dictionary entry is an object reference not the array name or ip!)
are replaced by id columns.
The best and easiest way to see it is to look at the schema via the Read-only user that I shared in the previous message.
Hope that's less confusing now 🙂
Cheers,
Yaron
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK, that helps, thanks Yaron.
Going back to the original reason why I was even looking at this, in the 1.x releases I used to look at the cache tables to determine what columns I could use when building my SQL statements for query inputs. In the 2.0 release, it seems that the dictionary is now where I get this info, which is fine...we just need to document the array_id column in the dictionary if we need to use it for SQL statements in query inputs. For example, it took me only a couple minutes to build almost all of a simple workflow with 2.0 (much easier that with 1.x!), but it took me quite a bit longer to figure out the usage of the array_id column for a query input since I didn't see it mentioned in the dictionary tables.
Thanks!
Mike
