ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: Heckling LAG errors
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yea this one has me on a hook.
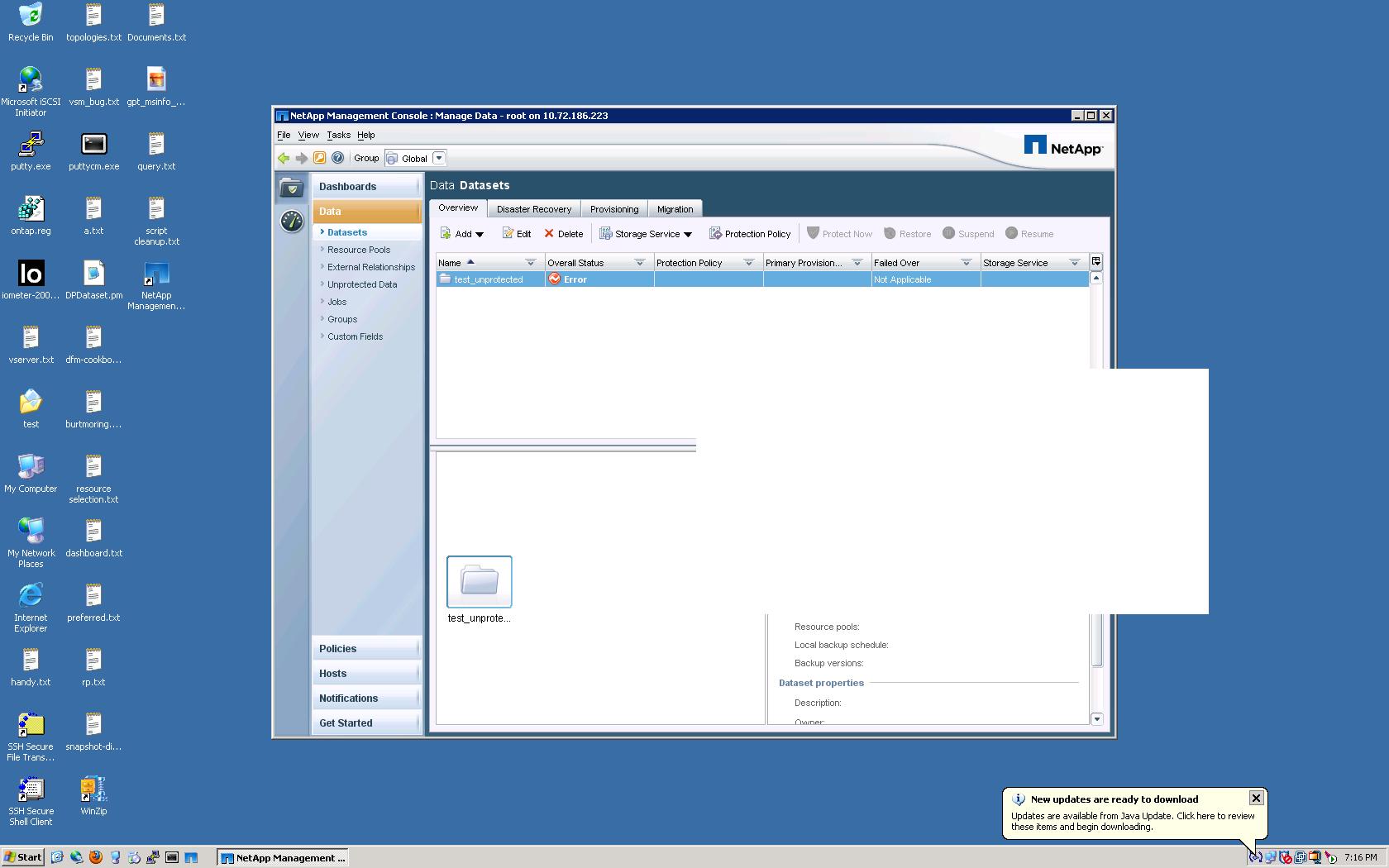
Using OM 4.0, I am creating a basic backup relationship between two controllers using mirco sized volumes and aggregates ( frugal here - 1GB volumes ). When I attach a protection policy to a dataset and watch the conformance kick in, right away I get hit with the red LAG error.
If i understand it right; the lag warnings only kick in if the "BASE" snapshot on the source is 1.5 days ahead the last replicated snapshot on the destination ( which means a replicated updated has not gone over to the destination )
Looking at the controller command line snap lists below; i am not 1.5 days behind so my curiosity is why is my lag alarm going off?
Destination:
Volume ntfa_data_backup
working...
%/used %/total date name
---------- ---------- ------------ --------
19% (19%) 0% ( 0%) Apr 07 23:31 2010-04-08 06:31:19 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
35% (24%) 0% ( 0%) Apr 07 23:31 topgun1(0101174782)_ntfa_data_backup-base.1 (busy,snapvault)
50% (32%) 0% ( 0%) Apr 06 23:31 2010-04-07 06:31:20 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
59% (32%) 0% ( 0%) Apr 05 23:31 2010-04-06 06:31:22 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
69% (42%) 0% ( 0%) Apr 04 23:31 2010-04-05 06:31:17 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
75% (42%) 0% ( 0%) Apr 03 23:31 2010-04-04 06:31:19 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
79% (42%) 0% ( 0%) Apr 02 23:31 2010-04-03 06:31:18 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
81% (42%) 0% ( 0%) Apr 01 23:31 2010-04-02 06:31:17 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
84% (42%) 0% ( 0%) Mar 31 23:31 2010-04-01 06:31:21 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
85% (42%) 0% ( 0%) Mar 30 23:31 2010-03-31 06:31:21 daily_topgun1_ntfa_data_backup.-.ntfa_data_zork_source_ntfs_data01
Source:
Volume source_ntfs_data01
working...
%/used %/total date name
---------- ---------- ------------ --------
24% (24%) 0% ( 0%) Apr 08 00:00 nightly.0
42% (30%) 0% ( 0%) Apr 07 23:30 dfpm_base(ntfa_data.1148)conn1.0 (snapvault,acs)
53% (28%) 0% ( 0%) Apr 07 18:00 hourly.0
60% (25%) 0% ( 0%) Apr 07 16:00 hourly.1
65% (28%) 0% ( 0%) Apr 07 14:00 hourly.2
69% (28%) 0% ( 0%) Apr 07 12:00 hourly.3
73% (28%) 0% ( 0%) Apr 07 10:00 hourly.4
75% (28%) 0% ( 0%) Apr 07 06:00 hourly.5
77% (25%) 0% ( 0%) Apr 07 00:00 nightly.1
79% (30%) 0% ( 0%) Apr 06 18:00 hourly.6
81% (25%) 0% ( 0%) Apr 06 16:00 hourly.7
82% (28%) 0% ( 0%) Apr 06 14:00 hourly.8
83% (28%) 0% ( 0%) Apr 06 12:00 hourly.9
84% (28%) 0% ( 0%) Apr 06 10:00 hourly.10
85% (25%) 0% ( 0%) Apr 06 06:00 hourly.11
86% (28%) 0% ( 0%) Apr 06 00:00 nightly.2
87% (30%) 0% ( 0%) Apr 05 00:00 nightly.3
87% (30%) 0% ( 0%) Apr 04 00:00 nightly.4
88% (30%) 0% ( 0%) Apr 03 00:00 nightly.5
89% (30%) 0% ( 0%) Apr 02 00:00 nightly.6
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Emanuel,
Can you get the screen shot of the pop window that is show when the ellipsis button against the protection status is pressed in the Dataset page for the dataset in question.
That will give all possible reasons why PM thinks its a Lag Error.Also can you get the output of the following command.
dfpm policy node get for the policy attached to the dataset ?
Regards
adai
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

Is the 253 a controller wide limitation here?
C:\Users\emanuel>dfpm policy node get NTFS_backups
Node Id: 1
Node Name: NTFS volume data filers only
Hourly Retention Count: 2
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 0
Weekly Retention Count: 1
Weekly Retention Duration: 0
Monthly Retention Count: 0
Monthly Retention Duration: 0
Backup Script Path:
Backup Script Run As:
Failover Script Path:
Failover Script Run As:
Snapshot Schedule Id: 0
Snapshot Schedule Name:
Warning Lag Enabled: Yes
Warning Lag Threshold: 259200
Error Lag Enabled: Yes
Error Lag Threshold: 300
Node Id: 2
Node Name: NTFS Backup Systems
Hourly Retention Count: 0
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 2592000
Weekly Retention Count: 2
Weekly Retention Duration: 0
Monthly Retention Count: 1
Monthly Retention Duration: 0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
emanuel wrote:
Is the 253 a controller wide limitation here?
C:\Users\emanuel>dfpm policy node get NTFS_backups
Node Id: 1
Node Name: NTFS volume data filers only
Hourly Retention Count: 2
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 0
Weekly Retention Count: 1
Weekly Retention Duration: 0
Monthly Retention Count: 0
Monthly Retention Duration: 0
Backup Script Path:
Backup Script Run As:
Failover Script Path:
Failover Script Run As:
Snapshot Schedule Id: 0
Snapshot Schedule Name:
Warning Lag Enabled: Yes
Warning Lag Threshold: 259200
Error Lag Enabled: Yes
Error Lag Threshold: 300<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<Here is the answer for your lag error/
Node Id: 2
Node Name: NTFS Backup Systems
Hourly Retention Count: 0
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 2592000
Weekly Retention Count: 2
Weekly Retention Duration: 0
Monthly Retention Count: 1
Monthly Retention Duration: 0

253 is not controller wide its the 255 snapshot limit per volume.
Your lag error is 300s or in other words 5mins as per the policy.
Its so evident from the pop up window and the policy lag error settings.
Regards
adai
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
how about that ....
Error Lag Threshold: 300<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<Here is the answer for your lag error/
as i configured the policy, i did not remember setting a value of 300 seconds ... is this some sort of default value i need to change elsewhere? The only thresholds i remember seeing was 1.5 and 3 days.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Emanuel,
By default lag warning is 1.5days and lag error is 2.0days.
Unless you have changed the values there is no chance that 300 seconds was there by default.
You can change the same through NMC-> Policy->Edit Nodes and connections and changing the value back.
Regards
adai
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Are the filers in the same timezone and do
the use the same time server ?
I've seen "lag error" cases where filers have different time zones
and where filers are in the same time zone, but their times different
by some number of minutes.
my_filer> options timed
timed.enable on
timed.log off
timed.max_skew 30m
timed.min_skew 0
timed.proto ntp
timed.sched 1h
timed.servers <servers>
timed.window 0s
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
both my controllers are locallized and on US/Pacific as is the OM server host.
I will double check when i can
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
okay, we are looking at the same thing but when i select 1.5 days or 3.0 days, how does that translate to 300 seconds on the output from eariler? I made some changes before did not notice any changes. I will try again shortly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think I found it ... it was in the source node section, your picture was the middle section where you assign the replication and throtle properities; I found on the local side of the policy the time setting was in "minutes" with a value of 5.
i know ran thepolicy command and i see the change. My specific test was based on remote snapshot/back up scheduled and i did not bother to look at the "local" settings. I made the change about 5 minutes ago so i am waiting for the error condition now to change.
C:\Users\emanuel>dfpm policy node get NTFS_backups
Node Id: 1
Node Name: NTFS volume data filers only
Hourly Retention Count: 2
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 0
Weekly Retention Count: 1
Weekly Retention Duration: 0
Monthly Retention Count: 0
Monthly Retention Duration: 0
Backup Script Path:
Backup Script Run As:
Failover Script Path:
Failover Script Run As:
Snapshot Schedule Id: 0
Snapshot Schedule Name:
Warning Lag Enabled: Yes
Warning Lag Threshold: 259200
Error Lag Enabled: Yes
Error Lag Threshold: 432000
Node Id: 2
Node Name: NTFS Backup Systems
Hourly Retention Count: 0
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 2592000
Weekly Retention Count: 2
Weekly Retention Duration: 0
Monthly Retention Count: 1
Monthly Retention Duration: 0
C:\Users\emanuel>
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just logged back into my PM client and I am still seeing the red lag error message but my policy seems to be okay; the backups are conformant so there does not seem to be any way to acknowledge the lag error.
C:\Users\emanuel>dfpm policy node get NTFS_backups
Node Id: 1
Node Name: NTFS volume data filers only
Hourly Retention Count: 2
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 0
Weekly Retention Count: 1
Weekly Retention Duration: 0
Monthly Retention Count: 0
Monthly Retention Duration: 0
Backup Script Path:
Backup Script Run As:
Failover Script Path:
Failover Script Run As:
Snapshot Schedule Id: 0
Snapshot Schedule Name:
Warning Lag Enabled: Yes
Warning Lag Threshold: 259200
Error Lag Enabled: Yes
Error Lag Threshold: 432000
Node Id: 2
Node Name: NTFS Backup Systems
Hourly Retention Count: 0
Hourly Retention Duration: 0
Daily Retention Count: 2
Daily Retention Duration: 2592000
Weekly Retention Count: 2
Weekly Retention Duration: 0
Monthly Retention Count: 1
Monthly Retention Duration: 0

{kind=link}
{kind=link}