Stay connected during the transition - Join our Discord community today.
VMware Solutions Discussions
- Home
- :
- Virtualization Environments
- :
- VMware Solutions Discussions
- :
- Re: vol0 with many write IOPS
VMware Solutions Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I assume that the peaks are write ops. If that is the case then I think this could be caused by ontap writing the hourly performance statistics to the /etc/log/cm_stats_hourly file. I see an hourly write peak on all the root volumes.
Still, 1500 ops is huge for just writing performance statistics data, but it is the only hourly action I can think of.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Dukers,
I thought like that, too. But, I did not imagined so many IOPS on a single file 16MB size.
Sometimes, these peaks are doing high latency in all volumes on storage. So, I'm trying to move some LUNs to another controller.
regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I currently have an open case on this. My 6240 controllers are seeing higher Read/Write/Other operations than the production VMware and Oracle volumes. We're looking at the ACP options and possibly disabling that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My open case has resulted in us checking into turning off the ACP (options acp.enabled off). I am going to do that later today on a 6280 cluster hosting my TSM db/logs/storage pools. I'll watch the IOPs via Performance Adviser and post my findings here.
My /vol0 is also just three disks.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
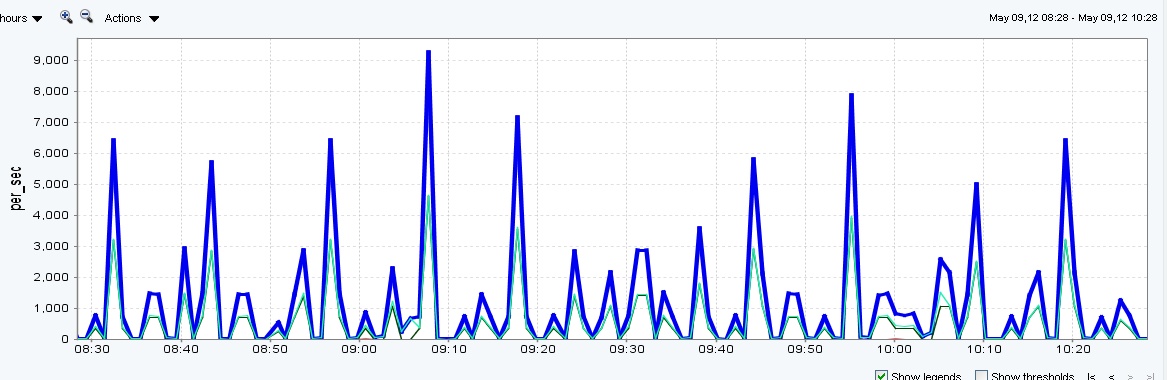
After disabling ACP on a 6280 /vol0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Cheers for posting.
Are Netapp saying its a bug? - are you going to leave it disabled?
Thanks
Col G
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Unknown at this time. Support hasn't said it is a Bug; disabling ACP was a test to see if the IO would in fact drop. Technically there shouldn't be any impact to leaving it disabled (that I have been able to find so far).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ive seen a few other reports of the same issue.
Does it have any further implications rather than just messing up performance graphs?
Personally im not too fussed about disabling it, but im not sure those above would see it the same way unless theres a specific bug attached to it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
After setting acp.enabled to "off" on three 6200 clusters I have recorded a significant drop in /vol0 IO across all six controllers. I have also noticed a "leveling" of the overall CPU. So far Support has not found any reason not to re-enable ACP (long term issues, etc.). I have had a 3160 running with no issues for almost 2 years without the ACP connected. I have one more system, primary VMware/NFS/iSCSI 6240 array which promoted my quest for a solution to the high IO, left to do (scheduled for Sunday morning).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the update... ill set the ball rolling on disabling ours then.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
NetApp has a bug that might be similar to your issue. Bug ID is 526941, but the url is http://support.netapp.com/NOW/cgi-bin/bol?Type=Detail&Display=526941.
Another option that might work is to disable the auto firmware update check. The command to do that is "options acp.fwAutoUpdateEnabled off" This gives you the benefit of having ACP, while potentially fixing this bug.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yep, my Support case just came back with that Bug. I'll try applying that to the machines where I have already disabled ACP, then re-enable ACP to see if it keeps the IO down.
Remove checksum firmware files from "/mroot/etc/acpp_fw". Specifically removing
following files will avoid this issue:
* ACP-IOM3.xxxx.AFW.FVF
* ACP-IOM6.xxxx.AFW.FVF
where; "xxxx" is the firmware file version.

{kind=link}
{kind=link}