About Zumasys
Zumasys is a NetApp reseller and cloud service provider that provides enterprise-class infrastructure technologies to businesses across North America. Founded in 2000, Zumasys specializes in IT solutions that reduce costs and boost productivity. The company achieves high customer satisfaction by listening to the needs of its customers, building strong relationships, and custom tailoring multivendor technology solutions that deliver results.
NetApp Insight: Mark Your Calendars
Insight 2014 is NetApp's annual conference devoted to technology-curious storage and data management professionals, including system engineers, professional services consultants, channel partners, and—for the first time ever—NetApp customers.
This year's events take place in Las Vegas, Nevada, on October 27–30 and in Berlin, Germany, on November 17–20. You can preregister here or get more details here.


NetApp has been making waves recently with its clustered Data ONTAP® operating system, which offers a long list of features and groundbreaking benefits such as nondisruptive operations, lower total cost of ownership, and seamless scalability.
However, there's been a lot of FUD out there about the complexity of clustered Data ONTAP. Most of those rumors come from people who don't know the product well or who don't have much hands-on experience. As one of the first 50 clustered Data ONTAP Partner Professional Services and Systems Engineering Specialists, I've spent a lot of time with both Data ONTAP 7-Mode and clustered Data ONTAP. I've done roughly 50 Data ONTAP installations since I joined Zumasys three years ago, with a significant increase in the number of clustered Data ONTAP installations in recent months. What this means to you is that—if you haven't already done so—it's time to get up to speed with this product.
Clustered Data ONTAP is different from 7-Mode, but added capabilities such as nondisruptive operations make it well worth using. In this article, I provide a few tips for familiarizing yourself with clustered Data ONTAP. I slant my discussion toward those who are already familiar with 7-Mode, but, even if you're new to Data ONTAP, you can still benefit.
Tip #1: Practice on the Clustered Data ONTAP Simulator

The NetApp® simulator—Simulate ONTAP 8—is by far the best tool you can use to hone your clustered Data ONTAP skills. The simulator will prepare you for all aspects of configuring and operating a cluster and will also help you understand best practices for AutoSupport™ settings, job scheduling, alerts, network failover groups, and more.
Practice makes perfect. The simulator lets you run through all aspects of a design and, when you're done, destroy your cluster and start over until you figure out how everything works and what will work best for your situation.
You can download Simulate ONTAP 8 from the NetApp Support site. (A NetApp login is required and available only for download by Data ONTAP customers and select partners.) To run the simulator, all you need is a dual-core laptop or desktop with at least 2GB of memory and 40GB of free disk space. Windows® systems require VMware® Workstation software and Mac® systems require VMware Fusion. (The latest version requirements are shown on the site.) Choose the version of the simulator that corresponds with the version of clustered Data ONTAP you will run.
Tip #2: Learn the New Command-Line Interface
One of the first things you may want to do with the simulator is learn the clustered Data ONTAP command-line interface (CLI). Clustered Data ONTAP includes graphical management tools that allow you to accomplish pretty much all configuration and management functions, but I still find there's no replacement for the command line when it comes to power and flexibility.
If you are a hard-core command-line junkie like I am, familiarize yourself with the new CLI hierarchy structure. One of my favorite new CLI features is tab completion. You'll find that you miss tab completion when you go back to 7-Mode.
The CLI is structured into a hierarchy of commands. No longer do you just type a question mark and see every command available to you. Commands are grouped together in a folderlike structure that includes networking, QoS, SnapMirror® technology, volumes, and so on. Once you enter into the first level of the hierarchy you can get more specific. For instance, if you go into "network" you have options such as ping, traceroute, port management, and interface management. Getting to know the structure may take a little learning, but if you know 7-Mode CLI and think about what you want to configure at the top level of the hierarchy you'll find yourself navigating quickly in no time.
My advice is to familiarize yourself with the new CLI on the simulator before you dive in on the real thing.
Tip #3: Make Full Use of Storage Virtual Machines
In clustered Data ONTAP, all data access goes through a logical construct called a storage virtual machine (SVM). (This was previously referred to as a Vserver, and you'll notice that the CLI still uses the older term.) As a result, the physical resources used by an SVM can change without necessitating any client-side or host-side changes or disruptions.
An SVM is a secure, virtualized storage container that includes its own administration security, IP addresses, and namespace. An SVM can include volumes residing on any node in the cluster, and you can have from one to hundreds of SVMs in a single cluster. Each SVM enables one or more SAN (FC, FCoE, iSCSI) and/or NAS (NFS, pNFS, CIFS) access protocols and contains at least one volume and at least one logical interface, or LIF. (See the following section for more on LIFs.)
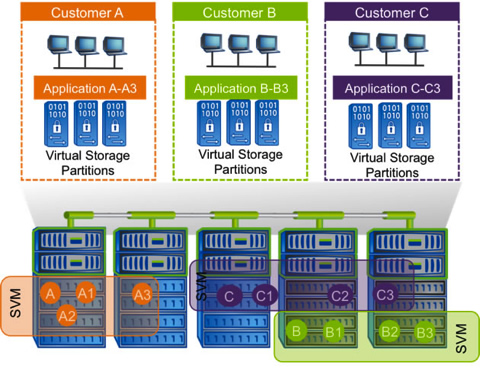
Figure 1) Clustered Data ONTAP uses storage virtual machines to separate logical entities from physical hardware and provide secure multi-tenancy.
You can have multiple SVMs within a cluster to serve different purposes. For instance, a service provider might use a separate SVM for each client on a cluster. SVMs are an import factor to consider when designing clustered Data ONTAP systems even if the environment they are going into isn't inherently multi-tenant.
For instance, I prefer to keep storage volumes used by servers on one SVM and user share volumes on a separate SVM. I usually create all of my iSCSI/FC LUNs and NFS datastores/mounts in one SVM. I create CIFS shares in a separate SVM. This provides extra flexibility in case of disaster, similar to what you may be used to with the vFiler® unit dr command in 7-Mode.
Here are some other considerations when setting up SVMs.
- QoS policies can be applied directly to an SVM. This can be extremely useful in service provider scenarios. However, be aware that you lose granularity in your QoS structure when you apply it at the SVM level. If you apply QoS to an SVM, you cannot apply a QoS policy on a particular volume within that SVM, so it may not be the best way to use QoS in every case.
- You can separate departments within a company, keeping data completely separate from other departments.
- Chargeback can be greatly simplified. You can easily tell how much each SVM utilizes.
- You can use separate SVMs for administrative purposes. You can give different groups or departments administrative rights to manage their own data without compromising other SVMs.
Tip #4: Understand Logical Interfaces
Logical interfaces (LIFs) may be the most important point to grasp for a full understanding of how clustered Data ONTAP works. This became apparent after I spent some time talking with other NetApp system engineers last October at NetApp Insight. (See the sidebar for information on this year's upcoming event.) LIFs are essential to nondisruptive operations within clustered Data ONTAP, so it's important to know what a LIF is, how LIFs work, and how to design systems using LIFs. If you can get this down, you will be way ahead of the people who just have a "good idea" of what a LIF is. Now brace yourselves, because here comes the technical introduction.
Similar to the way hypervisors abstract networking with virtual switches, NetApp LIFs abstract physical networking for your NetApp cluster. A LIF is a logical network interface that virtualizes your SAN and NAS network connections. This allows the cluster to expand, shrink, or even replace nodes without any network outages. LIFs are tied to an SVM and mapped to physical network ports, interface groups, or VLANs (when tagging is used) on the controller. Because LIFs are virtualized, a LIF address remains the same even when a LIF is migrated to another physical port on the same or a different node within the cluster. NAS LIFs automatically fail over if one of the cluster nodes goes down, working together with storage failover in the HA pair to preserve data access. You can also manually migrate a LIF to another port.
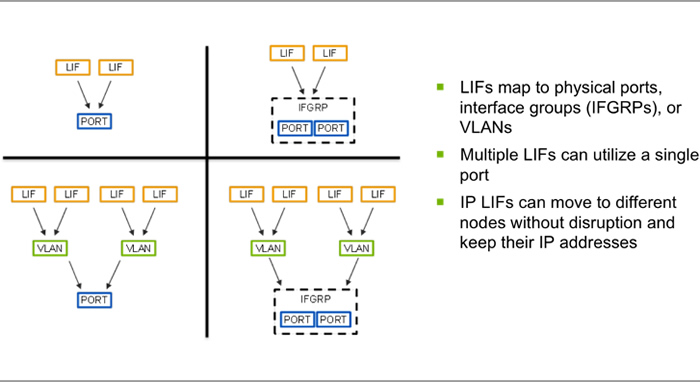
Figure 2) Clustered Data ONTAP uses logical interfaces (LIFs) to virtualize network connections. This is an important enabler of nondisruptive operations.
Each cluster node can support a maximum of 256 LIFs, 6 of which are reserved for management and cluster functions (leaving you with a usable maximum of 250). Data LIFs are used to serve data to clients or hosts and are designated as either SAN or NAS. IP-based LIFs (NAS or iSCSI) are assigned IP addresses and FC-based LIFs are assigned WWPNs. Each SVM requires at least one data LIF. In normal operation, you should limit the number of data LIFs per node to 125 or fewer. That way, if an HA failover occurs, the limit on the partner node won't be exceeded even if it takes over all LIFs from the failing node.
You can learn more about LIFs and LIF migrate in this Tech OnTap article on nondisruptive operations. To find out more about clustered Data ONTAP networking topics, including failover groups, load balancing, and more, check out TR-4182: Best Practices for Clustered Data ONTAP Network Configurations and the Clustered Data ONTAP 8.2: Network Management Guide. You should also check out the NetApp Support Site (login required) and NetApp University for the latest resources.
Tip #5: Be Prepared to Use More VLANs and IP Addresses
You almost certainly already know what VLANs are, but the thing you have to keep in mind is that a typical clustered Data ONTAP system uses more VLANs and IP addresses than 7-Mode. Where a 7-Mode storage system might have three VLANs (production, iSCSI, and NFS), a clustered Data ONTAP installation will have five VLANs (management, production, iSCSI, NFS, and SnapMirror). With clustered Data ONTAP, the management VLAN is required, and keeping your management on a separate VLAN helps you communicate with all cluster nodes in the event you have network problems.
Most network engineers agree that keeping broadcast domains to a minimum is ideal. By separating different traffic types into VLANs you keep down chatter to unintended recipients. It also helps keep your data secure from prying eyes. It is possible to create a CIDR 20 network and run NFS, iSCSI, and CIFS on the same subnet, but this is just asking for trouble. Most engineers, myself included, create different VLANs for each protocol to keep broadcast domains small and improve security.
Personally, keeping things consistent is very important to me. Using separate VLANs for different protocols also helps keep the IP address scheme easy to remember. For instance, when possible I like to have all IP addresses on the same node end in the same octet.
You'll use a lot more IP addresses with clustered Data ONTAP than with 7-Mode systems, so be prepared. Each SVM requires a management IP address as well as block (iSCSI) and/or file (CIFS, NFS) IP addresses. For example, a 7-Mode system with a service processor running CIFS, iSCSI, and NFS will have five IP addresses per controller. A similar setup requires about 14 IP addresses with clustered Data ONTAP. Making sure you have enough IP addresses in a block is extremely helpful during deployment.
Tip #6: Update Your Naming Conventions
With the new features of clustered Data ONTAP, having a well-thought-out naming convention is more important than ever. For example, a logical interface group (LIF) could be named n01_svm01_nfs. This allows you to quickly see that the LIF is on Node01, for SVM01, and is used for NFS. Additionally, a volume could be named svm01_ds01, denoting a volume that lives on SVM01 named ds01. It's less important what your naming convention is than that you have one. If a particular named object is tied to a node or an SVM, make note of it in the naming convention. On the flip side, if an object can float around it is probably best to remove the reference to the SVM or node. There is no perfect recipe, but consistency is the key. Do yourself a favor and create a naming convention before you do your first deployment—it will make your life much easier.
Tip #7: Create or Update Checklists
If you're a 7-Mode administrator or systems engineer, you may have checklists for installations and other procedures that you've developed and documented over the years. Creating or updating these checklists for clustered Data ONTAP may seem like an obvious step, but it's easily overlooked.
If you don't already have a checklist on paper, start by asking yourself how you would perform a given procedure such as setting up a 7-Mode system and use that as a starting point. Now take that checklist and perform the same process on clustered Data ONTAP using the simulator. You'll find that some of the steps for 7-Mode may be completely different to perform on clustered Data ONTAP, but the same general concepts still apply. Some steps are node specific while others are clusterwide. Once you complete this walk-through successfully, make yourself a new or updated checklist.