This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
ONTAP Hardware
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Hardware
- :
- Re: CRC-Error Messages seen since Ontap Upgrade to 9.3P7
ONTAP Hardware
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Community,
since we have updated some of our systems (FAS82xx, AFF A300) to Ontap 9.3P7,
we see the following Errors in Messages for our (UTA2) 10GBit LAN-Ports, which have not been here before the update.
10/16/2018 11:04:14 <Filer>-<node> ALERT vifmgr.cluscheck.crcerrors: Port e0g on node <Filer>-<Node> is reporting a high number of observed hardware errors, possibly CRC errors.
ifstat shows TotalErrors (increasing) and Errors/Minute but no CRC-Errors
-- interface e0g (1 hour, 42 minutes, 32 seconds) --
RECEIVE
Total frames: 56798k | Frames/second: 9233 | Total bytes: 178g
Bytes/second: 28949k | Total errors: 1337 | Errors/minute: 13
Total discards: 2 | Discards/minute: 0 | Multi/broadcast: 31503
Non-primary u/c: 0 | CRC errors: 0 | Runt frames: 18
Fragment: 0 | Long frames: 1319 | Alignment errors: 0
No buffer: 2 | Pause: 0 | Jumbo: 0
Noproto: 105 | Bus overruns: 0 | LRO segments: 50798k
LRO bytes: 174g | LRO6 segments: 0 | LRO6 bytes: 0
Bad UDP cksum: 0 | Bad UDP6 cksum: 0 | Bad TCP cksum: 0
Bad TCP6 cksum: 0 | Mcast v6 solicit: 0
TRANSMIT
Total frames: 16298k | Frames/second: 2649 | Total bytes: 11749m
Bytes/second: 1909k | Total errors: 0 | Errors/minute: 0
Multi/broadcast: 605 | Pause: 0 | Jumbo: 6655k
Cfg Up to Downs: 0 | TSO non-TCP drop: 0 | Split hdr drop: 0
Timeout: 0 | TSO segments: 840k | TSO bytes: 9910m
TSO6 segments: 0 | TSO6 bytes: 0 | HW UDP cksums: 0
HW UDP6 cksums: 0 | HW TCP cksums: 0 | HW TCP6 cksums: 0
Mcast v6 solicit: 0
DEVICE
Mcast addresses: 4 | Rx MBuf Sz: 4096
LINK INFO
Speed: 10000m | Duplex: full | Flowcontrol: none
Media state: active | Up to downs: 2
From my feeling it looks like a BUG in Data Ontap 9.3P7 (Error in their Portstats, ...), as we dont find any matching Errors in our Network infrastructure. Also no impact seen to the systems.
I already opened a support Case, but uptonow they cannot match this to an existing BUG, as 9.3P7 should have fixed all issues regarding this problem.
So timeconsuming debugging on customer site must be done to find the root-cause 😞
So the Question to the community: Anybody seen this Errors on Ontap 9.3P7?
Best Regards,
Klaus
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
short update on this topic:
it seems like the issues are really related to the Case, that we receive Packets with MTU-Size >1500, while the Port is set to MTU1500.
Starting with Ontap 9.3 this issue gets reported als "long frames" an in the events and alerts.
Our solution for a permanent fix is,
to set the MTU to 9000 on LAN-Ports on the Filer which are connected to a Switch with Jumbo Frames enabled.
Thanks Gidi for your feedback which helped much to solve the issue.
Best Regards,
Klaus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
port set to switches 9000 and also port set netapp 9000.
thats example from customer;
switch;
TX
1916130391 unicast packets 2666708 multicast packets 20843127 broadcast packets
1939643557 output packets 136406204523 bytes
3331 jumbo packets
3331 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
netapp;
RECEIVE
Total frames: 551m | Frames/second: 197 | Total bytes: 36893m
Bytes/second: 13145 | Total errors: 3372 | Errors/minute: 0
Total discards: 0 | Discards/minute: 0 | Multi/broadcast: 23737k
Non-primary u/c: 0 | CRC errors: 3370 | Runt frames: 2
Long frames: 0 | Alignment errors: 0 | No buffer: 0
Pause: 0 | Jumbo: 42 | Noproto: 0
Bus overruns: 0 | LRO segments: 100 | LRO bytes: 11072
LRO6 segments: 0 | LRO6 bytes: 0 | Bad UDP cksum: 0
Bad UDP6 cksum: 0 | Bad TCP cksum: 0 | Bad TCP6 cksum: 0
Mcast v6 solicit: 0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We have same Error since 5 Month, NetApp does not find a solution.
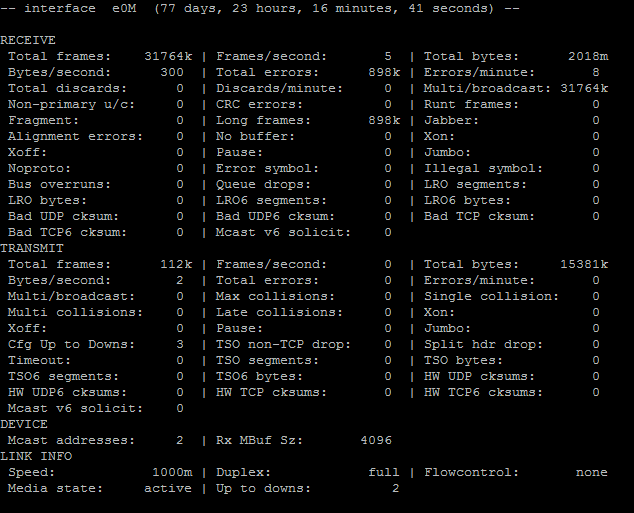
The port we have problems with, is e0M (Management).
e0M can not be higher than MTU 1500, Switch is configured too on MTU 1500 and with 1000 Mbps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
PKoza can you post your ifstat output for that port?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The long frames are non-zero.
https://library.netapp.com/ecmdocs/ECMP1368834/html/GUID-B7F1275B-6770-4447-ACD2-B66A7B9C407E.html
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm getting the same errors with long frames and length errors with our e0M ports and we upgraded to our ONTAP 9.7P10
Did you find any solution to this issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you follow the action plan in this KB? https://kb.netapp.com/Advice_and_Troubleshooting/Data_Storage_Software/ONTAP_OS/Ifstat_output_reports_long_frames
Your port is getting larger than configured MTU frames, and ONTAP is correctly discarding because it is invalid and possibly misconfigured.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I went over the ifcommands with support , also our networking team, confirm that the ports for the mgt ports e0M are set with MTU of 1500 on and also on the switches
network port show below that it is healthy ,but still getting those errors. We even replaced the network cables on all 4 E0m ports
Speed(Mbps) Health
Port IPspace Broadcast Domain Link MTU Admin/Oper Status
--------- ------------ ---------------- ---- ---- ----------- --------
e0M Default mgmt up 1500 auto/1000 healthy
e0M Default mgmt up 1500 auto/1000 healthy
e0M Default mgmt up 1500 auto/1000 healthy
e0M Default mgmt up 1500 auto/1000 healthy
Still trying thought

{kind=link}