ONTAP Hardware
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Hardware
- :
- Re: Netapp FAS vs EMC VNX
ONTAP Hardware
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi.
This year we have to decide if we should keep our IBM N-series 6040 (Netapp 3140) stretch metrocluster, upgrade to Netapp 3200 (or rather the IBM alternative) or move to another manufacturer.
And from what I can see, EMC VNX is one of the most serious alternatives. My boss agrees and so we have aranged meeting with EMC to hear about their storage solution including ATMOS.
So, I would like to hear from you other guys what I should be aware about if we decide to go EMC VNX instead of keeping the Netapp/IBM track.
It could be implementation wise or things like "hidden" costs, ie volume based licensing.
I'm having trouble finding EMC manuals to see what can be done and what can't.
Our CIO has set up one big goal for the future user/filestorage: The storage has to cost at most as much as it would if you go and buy a new Netgear/DLink NAS (with mirrored disk) a year.
This would mean that $/MB for the system has to be as close as possible to this goal. Today the cost is at least tenfold more.
Unless we come close to that, we have a hard time convincing the Professors with their own fundings to store their files in our storage instead of running to nearest HW-store and buy a small NAS (or two) for their research team.
It's called "academic freedom" working at a university...
Initial investment might be a little higher, but the storage volume cost has to be a low as possible.
Today we have basic NFS/CIFS volumes, SATA for file and FC for Vmware/MSSQL/Exchange 2007.
No addon licenses except DFM/MPIO/SnapDrive. Blame the resellers for not being able to convince us why we needed Snap support for MSSQL/Exchange.
We didn't even have Operations manager for more than two years and has yet to implement it as it was recently purchased.
The Tiering on Netapp is a story for itself.
Until a year ago our system was IOPS saturated during daytime on the SATA disks and I had to rechedule backups to less frequent full backups (TSM NDMP backup) to avoid having 100% diskload 24/7.
So the obvious solution would be PAM and statistics show that it (512GB) would catch 50-80% of the reads.
But our FAS is fully configured with FC and cluster interconnect cards so there is no expansion slot left for PAM.
So to install PAM we have to upgrade the filer, with all the costs associated BEFORE getting in the PAM.
So the combination of lack of tiering and huge upgrade steps makes this a very expensive story.
What realy buggs me is that we have a few TB fibrechannel storage available that could be used for tiering.
And a lot of the VM images data would be able to go down to SATA from FC.
EMC does it, HP (3Par) does it, Dell Compellent does it, Hitachi does it ...
But Netapp doesn't implement it. Despite having a excellent WAFL that with a "few" modifications it should be able to implement it even years ago.
Things we require are
* Quotas
* Active Directory security groups support (NTFS security style)
* Automatic failover to remote storage mirror, ie during unscheduled powerfailure (we seem to have at least one a year on average).
Things we are going to require soon due to amount of data
* Remote disaser recovery site, sync or async replication.
Things that would be very usefull
* Multi-domain support (multiple AD/Kerberos domains)
* deduplication
* compression
* tiering (of any kind)
So I've tried to set up a number of good/bad things I know and what I've seen so far.
What I like with Netapp/Ontap
* WALF with its possibilities and being very dynamic
* You can choose security style (UNIX/NTFS/Mixed) which is good as we are a mixed UNIX/Windows site.
Things I dislike with Netapp/Ontap/IBM
* No tiering (read my comment below)
* Large (read: expensive) upgrade steps for ie. memory or CPU upgrade in controllers
* Licenses bound to the controller-size and has essentialy to be repurchased during upgrade (this I'm told by the IBM reseller)
* You can't revert a disk-add operation to a aggregate
* I feel a great dicomfort when switching the cluster as you first shut down the service to TRY to bring it up on the other node, never being sure it will work.
* Crazy pricing policy by IBM (don't ask)
* A strong feeling of being a IBM N-series customer we are essentialy a second rate Netapp user.
Things I like so far with VNX from what I can see
* Does most, if not everything our that FAS does and more.
* Much better Vmware integration, compared to the Netapp Vmware plugin that I tried for a couple times and then droped it.
* FAST Tiering
* Much easier smaller upgrades of CPU/memory with Blades
I have no idea regarding negative sides, but being an EMC customer earlier I know they can be expensive, especially after 3 years.
That might counter our goal of keeping the storage costs down.
I essentialy like Netapp/Ontap/FAS, but there is a lot of things (in my view) talking against it right now with Ontap loosing its technological edge.
Yes, we are listening to EMC/HP/Dell and others to hear what they have to say.
I hope I didn't rant too much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If management cards are proprely configured, the takeover is automatic during MetroCluster rack power failure
As long as LAN switches do not suffer from the same power outage (e.g., do not located in the same rack )
Also, if network goes down at the same time, an UPS solution
Well, it is unrealistic to expect to protect against all possible permutaitons of component failures between two sites. It has to start with NetApp offering management port redundancy in the first place
Finally, if MetroCluster is used with "complicated" inter-links (like DWDM), a third referee could be used (like Tie Breaker) and NetApp provides some solutions like this.
MteroCluster TieBreaker solution is no more supported to the extent, that some user who posted here old TR referring to it was requested to remove it. It was replaced by Microsoft only SCOM plugin and now by MSCS plugin which is Microsoft only again. What can we offer to Unix only customer? And yes, I have Unix only customers and they would like to have automated failover (I will leave aside discussion whether automated failover in any long distance solution makes sense at all)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, D from NetApp here (www.recoverymonkey.org).
Autotiering is a really great concept - but also extremely new and unproven for the vast majority of workloads.
Look at any EMC benchmarks - you won't really find autotiering.
Nor will you find even FAST Cache numbers. All their recent benchmarks have been with boxes full of SSDs, no pools, old-school RAID groups etc.
Another way of putting it:
They don't show how any of the technologies they're selling you affect performance (whether the effect is positive or negative - I will not try to guess).
If you look at the best practices document for performance and availability (http://www.emc.com/collateral/hardware/white-papers/h5773-clariion-best-practices-performance-availability-wp.pdf) you will see:
- 10-12 drive RAID6 groups recommended instead of RAID5 for large pools and SATA especially
- Thin provisioning reduces performance
- Pools reduce performance vs normal RAID groups
- Pools don't stripe data like you'd expect (check here: http://virtualeverything.wordpress.com/2011/03/05/emc-storage-pool-deep-dive-design-considerations-caveats/)
- Single-controller ownership of drives recommended
- Can't mix RAID types within a pool
- Caveats when expanding pools - ideally, doubling the size is the optimal way to go
- No reallocate/rebalancing available with pools (with MetaLUNs you can restripe)
- Trespassing pool LUNs (switching them to the other controller - normal during controller failure but many other things can trigger it) can result in lower performance since both controllers will try to do I/O for that LUN - hence, pool LUNs need to stay put on the controller they started on, otherwise a migration is needed.
- Can't use thin LUNs for high-bandwidth workloads
- ... and many more, for more info read this: http://recoverymonkey.org/2011/01/13/questions-to-ask-emc-regarding-their-new-vnx-systems/
What I'm trying to convey is this simple fact:
The devil is in the details. Messaging is one thing ("it will autotier everything automagically and you don't have to worry about it"), reality is another.
For autotiering to work, a significant portion of your working set (the stuff you actively use) needs to fit on fast storage.
So, let's say you have a 50TB box.
Rule of thumb (that EMC engineers use): At least 5% of a customer's workload is really "hot". That goes on SSD (cache and tier). So you need 2.5TB usable of SSD, or about a shelf of 200GB SSDs, maybe more (depending on RAID levels).
Then the idea is you have another percentage of medium-speed disk to accommodate the medium-hot working set: 20%, or 10TB in this case.
The rest would be SATA.
The 10-million-dollar question is:
Is it more cost-effective to have the autotiering and caching software (it's not free) + 2.5TB of SSD, 10TB SAS and 37.5TB SATA or...
50TB SATA + NetApp Flash Cache?
Or maybe 50TB of larger-sized SAS + NetApp Flash Cache?
The 20-million-dollar question is:
Which of the 2 configurations will offer more predictable performance?
D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi D,
The devil is in the details. Messaging is one thing ("it will autotier everything automagically and you don't have to worry about it"), reality is another.
Couldn't agree more - with both sentences actually.
I was never impressed with EMC FAST - 1GB granularity really sucks in my opinion & it seems they have even more skeletons in their cupboard That said, e.g. Compellent autotiering always looked to me more, ehm, 'compelling' & mature. I agree it may be only a gimmick in many real-life scenarios (not all though), yet from my recent conversations with many customers I learned they are buying this messaging: "autotiering solves all your problems as the new, effortless ILM".
At the end of the day many deals are won (or lost) on the back of a simple hype...
Regards,
Radek
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Compellent is another interesting story.
Most people don't realize that compellent autotiers SNAPPED data, NOT production data!
So, the idea is you take a snap, the box divides your data up in pages (2MB default, can be less if you don't need the box to grow).
Then if a page is not "hit" hard, it can move to SATA, for instance.
What most people also don't know:
If you modify a page that has been tiered, here's what happens:
- The tiered page stays on SATA
- A new 2MB page gets created on Tier1 (usually mirrored), containing the original data plus the modification - even if only a single byte was changed
- Once the new page gets snapped again, it will be eventually moved to SATA
- End result: 4MB worth of tiered data to represent 2MB + a 1-byte change
Again, the devil is in the details. If you modify your data very randomly (doesn't have to be a lot of modifications), you may end up modifying a lot of the snapped pages and will end up with very inefficient space usage.
Which is why I urge all customers looking at Compellent to ask those questions and get a mathematical explanation from the engineers regarding how snap space is used.
On NetApp, we are extremely granular due to WAFL. The smallest snap size is very tiny indeed (pointers, some metadata plus whatever 4K blocks were modified).
Which is what allows some customers to have, say, over 100,000 snaps on a single system (large bank that everyone knows is doing that).
D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi D,
Most people don't realize that compellent autotiers SNAPPED data, NOT production data!
Yep, I wasn't aware of this either. If that's the case then why actually Dell bought them? Didn't they notice that?
So how about 3Par autotiering? Marketing-wise they are giving me hard time recently, so I would love to discover few skeletons in their cupboard too!
Kind regards,
Radek
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is the problem in the way they do it or the granularity of the block?
There is talk that Dell/Compellet will move to 64bit software soon, thus enabling them to have smaller blocks and then the granularity will problably not be a problem.
You could turn the argument around and say that Ontap never tiers down (transparently) snapshots to cheaper disk, no matter how seldom you access it.
So you will be wasting SSD/FC/SAS disk for data that you might, maybe, need once in a while.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well … I guess, NetApp answer to this would be snapvault,
For me one of main downsides of NetApp snapshots is inability to switch between them – volume restore wipes out everything after restore point; and file restore is unacceptable slow (which I still do not understand why) and not really viable for may files.
CLARiiON can switch between available snapshots without losing them. Not sure about Celerra, I do not have experience with their snapshot implementation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From what I'm told with snapvault the users loose the possibility of doing "previous versions" restore from snapvaulted snapshots of the files, right?
So the "transparently" thing is kicking in and a system administrator has to be involved, with all the extra work and time it takes to restore a file.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That’s true (except that previous versions does not work with block access anyway).
Does it (previous versions from snapshots) work with other vendors for SMB? Celerra in the first place (given we discuss VNX)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Most disk storage vendors have support through previous versions.
Saying SnapVault is the answer is like saying RAINfinity is auto-tiering. It's a seperate poorly integrated product/option/feature.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thats why netapp invented FlexClone, you do NOT need to completly whipe the source, you could clone the backup and split it if it fits your needs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dejan:
The granularity is part of the problem (performance is the other). Page size is 2MB now, if you move it to 512K the box can't grow.
With the 64-bit software they claim they might be able to go real small like 64K (unconfirmed) but here's the issue...
The way Compellent does RAID with pages is two-fold:
- If RAID-1, then a page needs to go to 2 drives at least (straightforward)
- If RAID-5/6, a page is then split evenly among the number of drives you've told it to use for the RAID group (say, 6). One or two of the pieces will be parity, the rest data.
It follows that for RAID-1 the 64K page could work (64K written per drive - reasonable), but for RAID-5 it will result in very small pieces going to the various drives, not the best recipe for performance.
At any rate, this is all conjecture since the details are not finalized but even at a hypothetical 64K if you have random modifications all over a LUN (not even that many) you will end up using a lot of snap space.
The more stuff you have, the more this all adds up.
My argument would be that by design, ONTAP does NOT want to move primary snap data around since that's a performance problem other vendors have that we try very, very hard to avoid. Creating deterministic performance is very difficult with autotiering - case in point, every single time I've displaced Compellent it wasn't because they don't have features. It was performance-related. Every time.
We went in, put in 1-2 kinds of disk + Flash Cache, problem solved (in most cases performance was 2-3x at least). It wasn't even more expensive. And THAT is the key.
Regarding Snapvault: it has its place, but I don't consider it a tiering mechanism at all.
I wish I could share more in this public forum but I can't. Suffice it to say, we do things differently and as long as we can solve your problems, don't expect us to necessarily use the same techniques other vendors use.
For example, most people want
- Cheap
- Easy
- Reliable
- Fast
If we can do all 4 for you, be happy but don't dictate HOW we do it
D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The 10-million-dollar question is:
Is it more cost-effective to have the autotiering and caching software (it's not free) + 2.5TB of SSD, 10TB SAS and 37.5TB SATA or...
50TB SATA + NetApp Flash Cache?
Or maybe 50TB of larger-sized SAS + NetApp Flash Cache?
This is all well and good in theory. But YMMV considerably.
I've just come from a rather large VM environment in the legal vertical... Incidentally also sold this same idea that a pair of PAM 512GB cards in front of oodles of SATA will save the day and drive down our TCO. That was a complete bust in this environment and if it weren't for a few available FC shelves, the 6080 HA cluster would have been ripped out by the roots overnight.
The thing about cache is its not just about quantity but also how advanced the algorithms are in the controllers. Something that neither the netapp nor vnx can compete with on arrays like the DMX or USP. Its down right amusing how much time our lead netapp engineer spent playing musical chairs with data on that HA 6080. NDMP copy, sVmotions, and metro cluster mirroring might have been 80% of his job. So much for the hands off PAM card tiering approach.
At the end of the day, both vendors offer a different solution for the same problem in a mid-tier/lower high-end enterprise space. What is better comes down to your requirements.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ggravesande,
You mentioned "Incidentally also sold this same idea that a pair of PAM 512GB cards in front of oodles of SATA will save the day and drive down our TCO. That was a complete bust in this environment and if it weren't for a few available FC shelves, the 6080 HA cluster would have been ripped out by the roots overnight."
Sounds like your environment wasn't sized right, please send the names of the VAR and NetApp personell involved to dimitri@netapp.com. Some "re-education" may be necessary

The solution always has to be sized right to begin with. All caching systems do is provide relief (sometimes very significant). But if it's not sized right to begin with, you could have 16TB of cache or 1000 FC disks and still not perform right (regardless of vendor). Or you may need more than 1 6080 or other high end box etc.
Take a look here: http://bit.ly/jheOg5
For many customers it is possible to run Oracle, VMware, SQL etc. with SATA + Cache, and for others it might not. Autotiering doesn't help in that case either, since many of those workloads have constantly shifting data, which confuse such systems.
Unless the sizing exercise is done properly or the system is intentionally overbuilt (or you just get lucky), it will usually end in tears regardless of vendor.
Oh, I hope that 6080 had the SATA in large aggregates and you weren't expecting high performance out of a single 16-drive pool. With ONTAP 8.1 the possible aggregate size gets pretty big on a 6080, 162TiB...
D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your completely correct about sizing. Which is why when Netapp pundits go around selling the one size fits all cache + sata architecture I cringe.
Netapp came in saying we would save money over the type of storage we typically bought (symmetrix, USP) but in the end we needed as many Netapp controllers to satisfy the requirements where cost is back in enterprise storage array territory.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
When trying to save money on storage, it's important to see where it's all going in the first place.
For example:
- People managing storage and how much time they spend
- People managing backups and how much time they spend
- Number of storage and backup products (correlating to people/time in addition to CapEx)
- How much storage is used to do certain things (backups, clones)
In the right environment, NetApp Unified can save companies a boatload of money.
In some other environments, it might be a wash.
In other environments still, going unified may be more expensive, and you may want to explore other options.
The problem with storage that has as much functionality as NetApp Unified, is that, in order to do a comprehensive ROI analysis, a LOT of information about how you spend money on storage is needed - often far beyond just storage.
For example, how much does it cost to do DR? And why?
How much time do developers spend waiting for copies to be generated in order for them to test something?
I've been able to reduce someone's VNX spend from 100TB to about 20TB. Yes - with 100TB the VNX could do everything the customer needed to do (many full clones of a DB environment plus local backups plus replication).
We were able to do it with 20TB and have space to spare.
The end result also depends on how much of the NetApp technology one is willing to use.
If you use our arrays like traditional boxes you get a storage system that's fast and resilient but it won't necessarily cost you any less...
D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dejan-Liuit,
You should check out Avere Systems (www.averesystems.com) or send me email at jtabor@averesystems.com. We are working with lots of NetApp customers. Rather than overhauling your entire environment to EMC, we can bring the benefits you need to your existing NetApp environment. Here are the benefits we offer.
1) We add tiering to existing NetApp systems.
2) Our tiering appliances cluster so you can easily scale the tiering layer as demand grows.
3) We let you use 100% SATA on the NetApp.
4) We support any storage that provides an NFS interface, which opens up some cost-effective SATA options for you.
5) We create a global namespace across all the NAS/SATA systems that we are connected to.
6) We tier over the WAN also to enable cloud infrastructure to be built.
Jeff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am currently evaluating options to replace our 7 year old EMC SAN/NAS. EMC quoted us a VNXe 3300 and a VNX 5300. We pretty much ruled out the VNXe because it doesn't have FC and we would either need that or 10 GB Ethernet. Our NetApp vendor quoted a FAS2040 and then compared it to a VNXe 3100, which doesn't instill me with a lot of confidence that it will meet our needs for the next 5 years like we are expecting out of the what we purchase. Noted the quote for the 2040 was significantly less than either of the VNX quotes so NetApp has some wiggle room on better models.
My question is am I wrong to think the 2040 probably won't cut it performance wise if we are pretty sure that the VNXe won't? Would a 2240 be a better option or would it be better to look at a 3210? We are a small to medium sized company with around 12 TB's in our current SAN, 10 physical servers, and 40 servers in VMware. We will be running 3 SQL servers, Exchange, SharePoint, Citrix, etc off of the SAN and we need to make sure that the users of our ERP system never know that anything changed unless the comment is "everything is really fast". IIRC from one of the environment checks that a vendor ran our current server environment is running at around 260 MBps. I've never worked with NetApp, but I've been a fan for a few years now. I just want to make sure I can compare apples to apples with the competition. Let me know if you have any questions and I'll do my best to answer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi and welcome to the Community!
It's a tough one - any solution should be sized against a particular requirement, so it is hard to say whether 2040 will suffice, or not. When comparing to EMC, it sits somewhere between VNXe 3100 and 3300.
Of course bigger (2240 or 3210) is better , but do you really need this?
How many (concurrent) users are we talking about? Did your reseller do any proper sizing against performance requirement, or was it a finger-in-the-air estimation?
Regards,
Radek
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Radek,
Thanks for your help. Our vendor did run EMC's check on our current SAN and sized the solution accordingly. We have 250 users. I'm not at all worried about the 2040 being good enough right now, it's just a few years down the road that I'm concerned with. I figure that we are getting a better discount now that we will when it comes time to replace the 2040 so it might be better to spend a little extra to buy a couple extra years before we need to look into replacing the controller unit.
Here is the IO and bandwidth info that our vendor pulled off of our current SAN, but that doesn't include email or Citrix since they are currently stand alone servers. Dell ran a similar report against our entire server environment and they had the 90th percentile for our bandwidth at 261 MB/s.
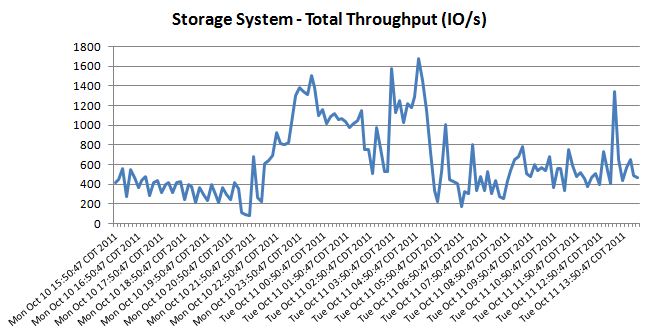
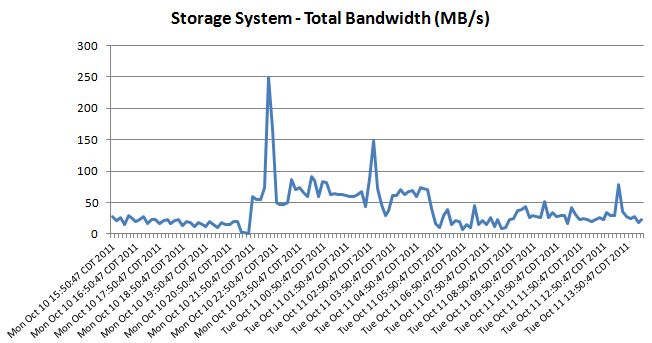
I have asked our vendor to quote out a FAS3210 just so we can get a better apples to apples price with the VNX 5300. Hopefully my assumption that the 3210 and the 5300 is reasonable. Does anyone know when the 2240 will start shipping?
We are also looking into starting up a DR site. IMO this will kill EMC since we don't think a VNXe will be good enough and the cheapest thing you can replicate a VNX 5300 to is another 5300.
