Network and Storage Protocols
- Home
- :
- ONTAP, AFF, and FAS
- :
- Network and Storage Protocols
- :
- Extremely slow NDMP recover with NetWorker
Network and Storage Protocols
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have observed it on multiple installations, now I have chance to capture it.
NetWorker 7.5 and 7.6, Data ONTAP 7.2 and 7.3, directly connected tape or 3-way backup via DSM, tape drive or backup on disk - in all cases I see exactly the same problem. Backup speed is quite good, it corrresponds to backend (i.e. over 100MB/s for tape drive or 1Gb/s network interface for 3-way backup). But recovery is miserable - it is approximately 8MB/s!
In all cases recovery was done via file base recover (nwrecover - browsing files, selecting them, starting recover, or direct call to recover).
As mentioned this happens in very different combinations of versions and backjup technology, so it appears to be inherent limitation of either NetApp or NetWorker. I attach screenshot (sorry, being connected to customer via read-only VNC session so can only do it) of recover session. Observe the throughput
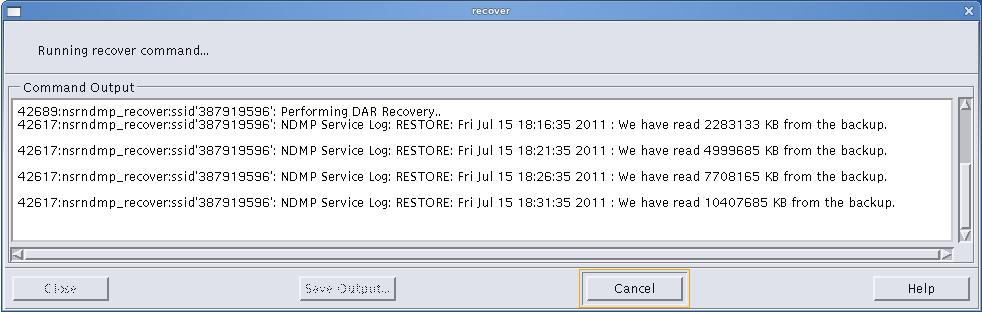
This is not high file count environment. It is NFS database with relatively low number of files. Total size is slightly above 1TB. And this is really reading data, after directory phase was already done.
Any hints, pointers and ideas appreciated. I probably has to (recommend to) try save set recovery next time. But it is frustrating ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In general recovery is slower than backup with NetWorker. To isolate the problem, you may want to capture some perfstat on NetApp controller, and if the controller is not busy then the problem is somewhere else.
Regards,
Wei
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is not busy. As mentioned, this is not limited to single installation only.
While I agree that recovery is slower, I would not expect it to be in order of magnitude slower.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yeah, it does seem a lot slower. If the storage is not busy, NetWorker may be doing a lot of round-trips to storage... my two cents.
Wei
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
After I had slept on it a bit I relalized that all documented cases of slow restore were using 3-way backup (with either another NetApp or NetWorker DSA as tape server). So I checked what was going on in 1TB restore session running right now. It appears there is indeed quite a bit of round trip overhead ... caused by NetApp.
From NDMP server log:
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Message NDMP_NOTIFY_DATA_READ sent
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Message Header:
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Sequence 466373
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Timestamp 1310805146
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Msgtype 0
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Method 1285
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: ReplySequence 0
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Error NDMP_NO_ERR
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Offset: 610934457344
Jul 16 12:32:26 GMT+04:00 [ndmpd:109]: Length: 1310720
From NDMP mover log:
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: NDMP message type: NDMP_MOVER_READ
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: NDMP message replysequence: 470892
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Message Header:
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Sequence 0
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Timestamp 0
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Msgtype 1
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Method 2566
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: ReplySequence 470892
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Error NDMP_NO_ERR
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Error code: NDMP_NO_ERR
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Offset: 616921826304
Jul 16 12:43:10 GMT+04:00 [ndmpd:37]: Length: 1310720
So it appears NetApp is issuing 10*128KB synchronous reads. Each read results in NDMP_NOTIFY_DATA_READ request from NDMP server to DMA (NetWorker) and NDMP_MOVER_READ request from DMA (NetWorker) to NDMP mover. So it is indeed quite a bit of round trip ... there are appr. 10 such requests per second which accounts for ~10MB/s restore performance.
Is it possible to change NetApp read size? Personally I'd rather issue single NDMP_NOTIFY_DATA_READ request for the whole dump size ... or at least once per file.
I have to test what NetApp does for direct tape restore.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good work! Sorry I can't answer your question. But I'll ask around. Regards, -Wei
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It cannot be explained by round trip delays alone. Here is tcpdump trace:
665 9.601275 192.168.2.130 192.168.2.57 TCP ndmp > 50031 [PSH, ACK] Seq=3213 Ack=1 Win=8760 Len=4 TSV=824507566 TSER=2117681160
666 9.601290 192.168.2.57 192.168.2.130 TCP 50031 > ndmp [ACK] Seq=1 Ack=3217 Win=2224 Len=0 TSV=2118197846 TSER=824507566
667 9.601410 192.168.2.130 192.168.2.57 TCP ndmp > 50031 [PSH, ACK] Seq=3217 Ack=1 Win=8760 Len=40 TSV=824507566 TSER=2117681160
668 9.601415 192.168.2.57 192.168.2.130 TCP 50031 > ndmp [ACK] Seq=1 Ack=3257 Win=2224 Len=0 TSV=2118197846 TSER=824507566
669 9.601444 192.168.2.57 192.168.2.131 NDMP MOVER_READ Request
670 9.601685 192.168.2.131 192.168.2.57 TCP [TCP segment of a reassembled PDU]
671 9.601691 192.168.2.57 192.168.2.131 TCP 52555 > ndmp [ACK] Seq=3285 Ack=2457 Win=1460 Len=0 TSV=2118197846 TSER=846710219
672 9.601785 192.168.2.131 192.168.2.57 NDMP MOVER_READ Reply
673 9.601787 192.168.2.57 192.168.2.131 TCP 52555 > ndmp [ACK] Seq=3285 Ack=2485 Win=1460 Len=0 TSV=2118197846 TSER=846710219
674 9.701244 192.168.2.130 192.168.2.57 TCP ndmp > 50031 [PSH, ACK] Seq=3257 Ack=1 Win=8760 Len=4 TSV=824507576 TSER=2117681160
Packets numbers 665+667 are for NDMP_NOTIFY_DATA_READ (for some reasons request is split by NetApp between two packets). As can be seen NetWorker immediately issues data mover request which is completed promptly (packets 669 - 673). After this we have 100ms pause before NetApp issues next NOTIFY_READ (674) ...
Unfortunately NDMP logs on NetApp do not offer sub-second granularity making it impossible to dig into it.
I also have seen description of exactly the same problem using Commvault with 3-way backup (using NRS which is analog of NetWorker DSA) - extremly slow restore without any obvious bottleneck anyhere.
This does look like NetApp bug ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
While this is frustrating, I wouldn't necessarily jump to the conclusion and call it a bug. Maybe it was done this way for a reason... But it's definitely something worth more investigation. -Wei
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do you have 'options ndmpd.tcpnodelay.enable on' ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
no
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Give that a try...
😉
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just curious, is the option intended to shorten the wait time? Thanks, -Wei
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The options manpage should be a logical reference point for such questions:
ndmpd.tcpnodelay.enable
Enables/Disables the TCPNODELAY configuration parameterfor the socket between the storage system and the DMA. When set to true , the Nagle algorithm is disabledand small packets are sent immediately rather than held and bundled with other small packets. This optimizes the system for response time rather than throughput.
The default value is false.
This option becomes active when the next NDMP sessionstarts. Existing sessions are unaffected.
This option is persistent across reboots.
You are a NetApp employee? ... Google will help you with the general socket option and effects of tcpnodelay...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks. Well noted. -Wei
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
It's quite some time since that problem was opened and I would be very curious to know if you solved that issue! I have the exact same problem, and we passed through the same phases... Activating tcpnodelay helped a bit, but we still have very poor single file restore performance...
Thanks
Gilles
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry, no. I never got around to retesting it myself and customer never complained about slow recovery after that either (I do not say it became faster, just that nobody complained …)
It is extremely hard to troubleshoot such issues simply because you do not perform multi-terabyte recover every day and when you do, you need to complete task and have no time to troubleshoot ☹
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for this reply, faster than single file restore!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oh, BTW, this problem was unrelated to single file restore, it was the whole backup that was being restored. To speed up single file restore the only option is to use DAR, but it has to be enabled during backup and you have to use specific utilities to restore (not all of NetWorker restore tools support DAR – check administration guide).
---
With best regards
Andrey Borzenkov
Senior system engineer
Service operations
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for this additional information. On my side actually, backup is also 100 MB/s , then whole restore is around 30MB/s and then single file restore is around 10MB/s ...
i will check what you say about the restore tools and DAR, quite an interesting information.
Gilles

{kind=link}
{kind=link}