ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- CDOT == Vista ?
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Am I the only one thinking that CDOT is NetApp's Vista (or Win8)?
I do see some good things about CDOT, but nothing is feature complete. And the CLI interface is tab completion, lacks syntax documentation.
As for the movement, it still mostly disruptive, and can only be done on a volume by volume basis.
I would have thought that the movement should be at the volume level on the lowest echelon, but should apply to the vserver to make it really usable. The lack of application group identification is also another feature which should have been there. I should be able to group my volumes by vserver/app or app-group, and should be able to perform mass-moves as such. What use is being able to move individual volumes around?
And in reality I see two tiers of storage these days, SSD, and SAS 2.5". Both are ultra low power, faster than SATA, and I bet they are cheaper over the long run than the power hog 3.5" SATA's. So there are really two tiers? I'm just saying...
I just don't know that there is any real value in CDOT for the average user.
I think NetApp should have continued development of 7DOT, adding SMB 3, pNFS (soon), and the non-disruptive volume migration. And they should have kept the 7DOT CLI.
Am I off-base?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Full disclosure... I work for NetApp.
I wouldn't call cDOT "Vista"... maybe more of a Windows 7, or even Windows 8. It would be fair to call GX "Vista," I think.
There are value adds in cDOT that you don't get in 7-mode, even for the most basic admins.
For instance, in 7-mode, could you have 4 nodes in a single namespace? No... if you wanted to add CPU or RAM, or even disk (if you maxed out your HA pair) you had to add a whole new HA pair with new IP addresses, new folder structure, etc. Then you had to tell all your users "hey, mount this AND this."
With cDOT, you don't have to tell your users anything. You simply add new nodes non-disruptively and provision storage under the same namespace/vserver/SVM. That's it. No new IP addresses, no re-mounting, no communication with your users about downtime.
What admin wouldn't want THAT?
As for movement, you are forgetting about aggregate relocation (ARL), which allows you to move entire aggrs non-disruptively. Did 7-mode have that?
In 7-mode, you could move volumes... between two nodes. But what if both of those nodes are slammed? In cDOT, I can add more nodes (up to 24 in NAS) and move the volume to a node that isn't being used at all.
There are definitely use cases for application/group based volume moves, and I suggest you speak to your sales representatives to put that sort of thing on the radar for the product managers, if it isn't already on the radar.
For your point about disks/spindles, there are still use cases for high capacity, low RPM SATA drives - many customers still use this type of disk for backups, archival, etc. And with different disk types on separate HA pairs, service providers can sell tiered storage to their customers. You want faster storage? You pay a premium. You want economy storage? You get the SATA drives!
7-mode would never be able to properly leverage features like pNFS, which is one reason why you won't see it in 7-mode. What point is there to a protocol that is built for highly agile, mobile storage in a single namespace on an OS that is limited to two nodes, each with their own namespace?
Things like CLI, feature gaps, etc... those are all valid concerns and things I have rallied for improving behind the scenes. Changes are coming. 8.3 will be a major improvement over 8.2. And later releases will introduce even more feature parity and usability for everyone.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply Parisi.
You make some good points. However, from my perspective it is still a half baked product, since it will not allow me to perform online group/app moves. What is the difference between moving an applications volumes in 7DOT, one at a time, versus CDOT, one at a time also.
As for shelf replacement, from what I've been told, it is a little more marketing. The reason I say that, is that if I have a shelf that has become stuck, which I've had happen many times, the only way to clear it is to power off the entire stack. That means, having enough extra disc stacks to move the data on the stack which is failing, plus enough bleed-over space for each aggregate in the failing stack allocated in other stacks. I usually don't have stacks of shelves sitting unused, so I will still need to take an outage.
I was not aware of the aggregate relocation, that is an awesome feature. Sort of what I want with volume/app groups.
Perhaps I maybe wrong; I have been trying to get a CDOT vSIM cluster setup since the beginning of they year and have had no luck. I may very well change my mind once I can start playing with the cluster.
HOWEVER, the CLI... ...and the changes to the CLI interface make learning CDOT onerous. I'm glad to hear that 8.3 will improve it.
Thanks for responding and giving me ideas about features to investigate, once I have a cluster setup. Perhaps others will chime in and help me understand CDOT better.
BTW, a shameless plug, the "NetApp Communities Podcast" has been a tremendous tool for learning about CDOT features. I get it on iTunes, but I believe it is available elsewhere as well. (And no, NetApp, do not take it over, leave it semi-independent as it is).
Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There are plenty more features that make cDOT an improvement over 7mode. I just mainly listed the ones that addressed your overall concerns.
For shelf issues, there is a feature called "hot shelf removal" (added in 8.2.1) that can be used in conjunction with aggregate relocation to allow you to power cycle, remove shelves, etc.
To read more:
https://library.netapp.com/ecmdocs/ECMP1367947/html/GUID-2B80FBD2-007D-4D19-8EB1-9CCEED211001.html
For 7-mode veterans, yes, the CLI is a challenge. But the feedback I have heard from users who never touched 7-mode is that the cDOT CLI is easy to use. In 8.2, there were improvements made to the man pages on-box, too. So if you ever had questions about a command, just type "man [command]" and you'll see all the info.
Additionally, rather than using tab completion, you can leverage ? to get listing of available values for a command option. There are plenty of tricks and tips for cDOT CLI.
8.3 won't necessarily completely improve the CLI, but it will further converge the 7-mode features and commands into cDOT. Even now, you can run 7-mode like commands in cDOT (such as df, sysconfig, etc) in the cluster shell.
Go ahead and install the simulator and test it out. The more you use it, the more you will see the advantages over 7-mode.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For shelf issues, there is a feature called "hot shelf removal" (added in 8.2.1) that can be used in conjunction with aggregate relocation to allow you to power cycle, remove shelves, etc.
Are you sure it is aggregate and not volume reallocation? To hot remove shelf it must be empty which means all data must be evacuated and aggregates on this shelf destroyed. Aggregate relocation changes ownership but not physical placement; to evacuate data one would need to move volumes off to another aggregate.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, you are correct. Brain fart.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here are some comments from a customer perspective.
The CLI in CDOT is incredible once you get acclimated to it and it really doesn't take that much time. I was so used to administering everything from a linux host via SSH so I could get an extra set of tools like grep to supplement. Now I prefer to be consoled directly in because of the tab autocomplete capability.
The migration from 7-mode to CDOT wasn't without pain. The 7MTT was helpful but was far from perfect as of version 1.2 at least which is what we completed our transition on. It's great at getting the volumes mirrored from 7-mode to CDOT so you're data is all intact. The access to the data, which is pretty critical, is a different issue. We ran into a decent number of gotchas in regards to access after the transition.
Here are some from our experience:
- We had cifs shares where the case of the folder name in the path DID NOT match the case of the actual folder. 7-mode didn't care, but CDOT is not forgiving of such. 7MTT did not warn me of this and the result of 81 cifs shares not being recreated on the CDOT side during the transition. I was fortunately able to identify all of these shares from the logs of the tool noting the share could not be created.
- Crucial to have an understanding of junction paths and how much different it is compared to 7-mode /etc/exports.
- Per KB 3011859, we have qtrees w/ NTFS-style ACLs that are accessed from linux servers. The KB doesn't provide any method for resolving the issues described for CDOT. I had to scour the documentation to find the equivalent workaround which is hinted in the 7-mode to CDOT options map write-up.
- Inability to NFS export at a qtree level until 8.2.1 which delayed our migration for some time until it went GA and we upgraded to it. One issue you won't have to deal with at least.
Overall, the transition pain is worth the benefits of being on CDOT in my personal opinion, but we have a relatively small environment compared to other companies (just two physical nodes).
I personally installed the CDOT simulator before any planning in order to get a feel for the new CLI and also learn how the commands map. It helped tremendously.
At this point, we're mainly still getting reports here and there of NTFS data being accessed from linux hosts failing, but I believe I've discovered all of the fixes and workarounds for the different types of circumstances surrounding these and have been able to resolve as they are reported. The user mapping piece in general is just as confusing as it was in 7-mode for NTFS/UNIX.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What use is being able to move individual volumes around?
So you can utilise different I/O performance tiers and network paths within a given vServer..
cDOT is good because it dissassociates vServers from physical controllers and aggregates and allows you can access resources across the whole cluster via a single namespace.
Personally I would never want to move a whole vServer or application group from "A" to "B" in one go except for very small vServers (one volume) while rebooting node. Thinking about a vServer as a unit of storage which needs to be put somewhere and moved around as single entity is contrary to the way cDOT is designed to work IMHO. The way I see it, a vServer is primarily a namespace and security realm, rather than a storage object.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Think of it this way... 8.0 and 8.1 were the alpha and beta releases... thus Ontap "Cluster Mode" the rename to CDOT came with the live production release of 8.2, and we have seen SP1 come out already, with 8.2.1, and are working our way toward the next major release.
There are many wonderful features in CDOT that are impossible in 7 mode, many are similar to what other major storage vendors are doing, and many are revolutionary. I see it as a real step forward.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You are not alone.
The only CDOT feature that is of interest is the promise of non disruptive cluster pair upgrades when heads and disks go EOL. However, the level of effort and time required to migrate/convert 2PB and 35 HA pairs to cluster mode doesn't seem like its worth the effort or risk. Specially with Mars on the horizon.
Here's a few CDOT concerns
7mode to CDOT migration: Migrating from 7mode to CDOT is about the same level of effort as moving from 7mode to Isilon. The 7mode migration tool has helped, but still hearing of gotchas and SMB issues.
Workload isolation: Currently we have isolated our 7mode workloads into HA Pairs. HA pairs for each of Oracle NFS, VDI, Vmware, Backups, SMB, etc. This physical isolation has worked well for performance, manageability, and most important politically. We have considered using a single CDOT cluster for all the workloads, however isolation seems like it's going to be an administrative challenge. Now considering multiple clusters based on workload type, aka 7mode physical isolation.
Naming conventions: It was hard enough in 7mode, but CDOT with all its logical and physical objects adds a whole new level of complexity. Fortunately, most everything including the cluster name can be renamed on the fly. We must have renamed our test cluster and SVMS 5 times now, and still don't know what to name the SVMs. Can't tell you how many needless hours spent debating unix host naming standards in the past. Try debating a system that needs 20 different object names.
Namespace: Again, a whole new level of trying to design a standard namespace. Get this naming wrong, and live with it forever. So far, everyone wants a flat namespace with no sub levels which seems like it's going to be a mess down the road one way or the other
CDOT upgrade path: The marketing folks are saying non disruptive updates. Adding new nodes to a 2014 CDOT in 2018, yea right. I'm sure the exception list will be 4 pages long, and most likely not supported.
SMV: How many, what to name them, how to isolate aggregates to prevent other SVMs from using isolated heads. It would be cool to be able to snapmirrow at the SVM level.
Performance Monitoring and metrics. A whole new way to monitor CDOT and a limited performance metrics available in CDOT. The promise of non disruptive volume migrations is of little use when you don't have metrics needed to make decisions based on performance. Work in progress I guess.
CDOT SAN. Wow, yet another level of complexity. SAN is bad enough on its own.
Performance? Still haven't seen performance marketing stats... Does CDOT perform better than 7mode for the same workload? Maybe I missed those marketing slides.
CDOT seems extremely flexible and a great foundation for creating things like flexpods where you need a great deal of flexibility for features like multi-tenancy. But way to complicated for shops that are just needing SMB and NFS shares and maybe even iscsi with minimal administrative knowledge and short on staff.
CDOT broke the KISS rule, same as VISTA. Maybe just wait for Mars to rise.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
7mode to CDOT migration: Yeap completely agree, but in saying that its not that much harder that migrating 7-mode to 7-mode with EOL disks. From what i understand there will be some synergy between mars and cDoT how much i'm not sure.
Workload isolation: I'd argue that you can get the same if not better isolation on a clustered ontap system. if your requirements are that strict then creating an SVM binding the nic's and aggrs from a single node to it will give you the exact same thing as you have currently. I'd question if you really need it or whether you're doing it because thats what you've always done. cDoT is different, Ideally you setup your stuff to leverage the features of cDoT, if you dont want to then you can run them in a very 7-mode ish way. but features like QoS and binding specific nodes and resources together into seperate SVM's provides IMO superior isolation to what you can do in 7-mode.
Naming conventions: They confusing until you understand why they are important and what you can do with a well thought out naming scheme. Generally i stick with "clustername" clustername-xx for the nodes, node_aggr_type for the aggregates. in the SVM space i use svmname, svm_data1 for the lifs etc. this allows you to use wildcards if you want to make changes or gather information about specific node aggrs or lifs or what ever.
Namespace: Its no different that creating the wrong share name, you can fix it, but it requires an outage. Like anything its needs to be carefully planned.
CDOT upgrade path: I've been working with cDoT since the 10.0.2 GX days, my first cluster was based on 6070's which we added 6080's to without issue and migrated data onto new disks seemlessly. We inserted 3050's into the cluster temporarily and moved data onto it with no issues at all. The new ARL functionality in 8.2. seems awesome, but i havent had a chance to play with it yet. We even moved a cluster between datacenters without the users noticing using nothing but stretched vlans and volume move.
SMV: Yeap i agree. this is something i've spent a reasonable amount of time thinking about. its personal, generally i prefer one large SVM unless i have the need to isolate it for what ever reason (like some of the ones you mention above) additonally its sometimes useful to break out protocols into svm's
cDoT SAN: its actually not that bad. once the op hits the nblade it ends up as a spin op no matter what d-blade it hits.
Performance: From what i've seen in most cases its about the same. We see differences in how a workload effects a system but not that much a better or worse. indirect op/s can introduce a tiny amount of latency, but thats not that hard to avoid with good planning. (if latency is a major for you)
thats the thing with cDoT is it can be as complex or simple as you want it to. I have installed 2node 2240 clusters with 2 svm's, a single trunk per node, single aggr per node ala how we would do it with 7-mode. and i've installed multi node 6280 clusters, midrange dual node 6240 clusters running multiple svm's, protocols, vlans, lifs etc.
Its is a different way of thinking, but does provide some definite benefits over 7mode in most cases.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I haven't done much research, but I'm having a hard time trying to understand how you isolate an aggregate to a SVM. I want to isolate my ORACLE to a set of nodes/disks and not allow other SVM to add workloads... I also have clients that basically paid for dedicated nodes, space etc, and want a workload "guarantee" ..... Currenly every SVM can see all aggregatges... How do I force isoloation to the point where even jr admins can't acidently mix workloads?
I must be missing something simple on aggr isolation in a cluster....
Have you tried to migrate from a 6070 to 8060's? I would expect 6070 to 6080 to work with no issues, but how about nodes that differ in several generations. How about a 3160 to a 8060?
Anyone with production experience in a financial environment using a 20 node cluster and mixed workloads? That's where we are headed with our 7PB. At least thats the plan from some team members.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
SVM sees only those volumes that had been allocated to it. It is cluster administrator who sees all aggregates. If you want to restrict it - assign aggregates exclusively to SVM and let vserver (not cluster) admin to do it. Makes sense in multitenant environment anyway.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can define which aggregates are accessible to which SVM inside System manager (and probably the commandline) they are still visible correct but they need to jump through hoops to add them to the wrong area. Otherwise you do it via WFA if you dont believe your engineers are capable enough to put data in the right place. to be fair its trival to move even if someone makes a mistake
I've upgraded from/to many things starting from F720's up to the latest and greatest FAS8080 styles. most of the clustered ontap ones i have done are with high end to high end. Biggest difference i've done on cDoT is FAS3050 to FAS6080.
In 7 mode i've upgraded a FAS960 to a FAS3050 to a FAS3240 to a FAS6080 (same disk no config changes) without issue. FAS3140 to FAS6240 was another one.
I've looked after some decent sized clusters from an I/O perspective mainly 6 nodes but with throughputs of in excess of 12GB/s Generally the systems i work with dont end up with more than about 100TB of disk behind each node because thats the sweetspot for our particular workloads.
Assuming you're talking highend systems here 7PB behind a 20 node system shouldnt be any trouble, thats like 350TB per node give or take. assuming you size the nodes appropriate for the load
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
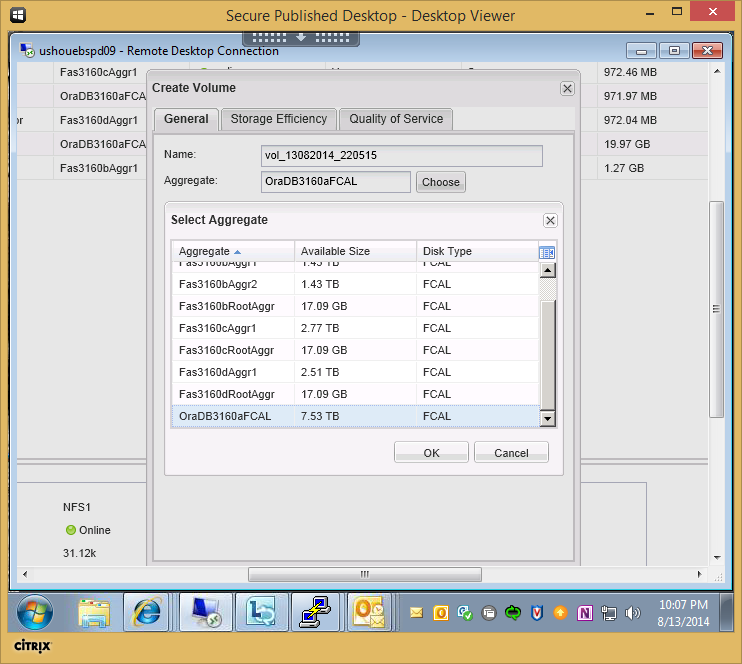
You can define which aggregates are accessible to which SVM inside System manager (and probably the commandline) they are still visible correct but they need to jump through hoops to add them to the wrong area.Maybe I need a new version of System Manager? How do you define which aggregates are accessible to which SVM inside System manager? When I go to create a volume for example in any SVM, I see all the aggregates across the cluster including root aggrs.
I was hoping to find a way to assign aggr to SVMs and only to those SVMs
Maybe we just messed up our initial configuration?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From memory its done when you setup the SVM (i dont have a cluster to check here)
https://library.netapp.com/ecmdocs/ECMP1196912/html/GUID-54FA031E-C60D-4AEF-887E-93DBA463211C.html
If the Vserver for that volume has aggregates assigned to it, then you can use only one of those assigned aggregates to provide storage to volumes on that Vserver. This can help you ensure that your Vservers are not sharing physical storage resources inappropriately. This segregation can be important in a multi-tenancy environment, because for some space management configurations, volumes that share the same aggregate can affect each other's access to free space when space is constrained for the aggregate. Aggregate assignment requirements apply to both cluster administrators and Vserver administrators.
EDIT2:
https://library.netapp.com/ecmdocs/ECMP1196912/html/GUID-5255E7D8-F420-4BD3-AEFB-7EF65488C65C.html
Thats the command, it may not be in system manager, i dont use it that often
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, the following did the trick, sorta...
vserver modify -vserver vs1 -aggr-list aggr1,aggr2
After running the previous command, I still see all the aggregate when trying to create a new volume(which is a bug IMHO), however now if I try to use aggr3, i get the following "Cannot create volume: Reason, aggregate aggr3 is not in aggrlist of vserver..."
There needs to be a way to quickly allow, or limit aggregate from System Manager, Specially root volumes which I hate seeing in system manager already with only 4 nodes.
This functionality really should be in System Manager day one.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Its not pretty and could definitely be better but it does achieve protection against what you were worried about.
It doesnt make sense to not see root aggregates in system manager. You need to keep an eye on them as a storage admin. They're part of the array. If you want limited accounts then create VSadmin accounts then you cant see the root volumes.
Personally i'm not fussed, i hardly use system manager. I prefer the commandline but thats probably because i've been using it for a long time. I started in environments where finding a client with a GUI was the first hurdle to getting a web browser
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't want to see root aggr listed in the create new volume dialog. At least a check box to not view them. I can't even search in this dialog which really bites..
Thanks for the info!! At least we can do some level of isolation to prevent admins from randomly assigning volumes to any aggr they feel like. Neither our onsite Netapp RA or sales tech could find this answer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can create a role to prevent users from seeing root aggregates. Simply use the query fields to allow access only to the data aggrs.
| parisi-cdot::> aggr show -root false | Aggregate | Size Available Used% State #Vols Nodes | RAID Status |
--------- -------- --------- ----- ------- ------ ---------------- ------------
| aggr1 | 896.4MB 489.5MB 45% online | 10 parisi-cdot-01 raid_dp, | |
| normal | |||
| aggr2 | 896.4MB 290.7MB 68% online | 9 parisi-cdot-02 raid_dp, | |
| normal | |||
| aggr3 | 280.2MB 278.9MB | 0% online | 1 parisi-cdot-01 raid_dp, |
| normal |
3 entries were displayed.
parisi-cdot::> security login role create -role hide_aggr -cmddirname volume -access all -query "-aggr aggr1,aggr2,aggr3" -vserver SVM
Then you can apply that role to a user:
| parisi-cdot::> security login create -username hide -application ssh -authmethod password -role hide_aggr -vserver SVM |
Please enter a password for user 'hide':
Please enter it again:
Once I log in as that user, volume create will not permit me to create volumes on the aggregates not in the list:
SVM::> vol create -aggregate aggr0 -volume test -size 20m -state online
(volume create)
Error: command failed: not authorized for that command
Aggr0 is a root aggr:
parisi-cdot::> aggr show -aggregate aggr0 -fields root
aggregate root
--------- ----
aggr0 true
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
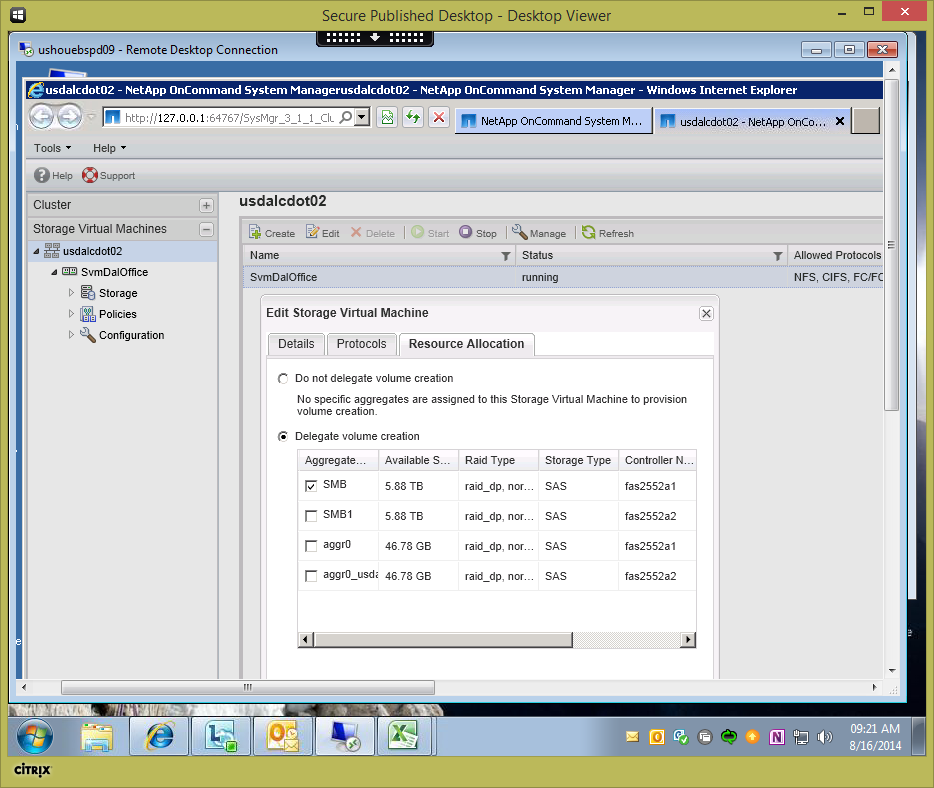
Turns out, System Manager has a way to isolate aggregates to a SVM after all.
It's not that east to find the setting, and it took me 3 times to remember how to get back to it.
On the Storage Virtual Machine pane, click on the Cluster Name (not the SVM), then right click on the SVM you want to change in the right pane, then click on Edit. Click on Delegate Volume Creation and select the aggregate(s) that you want to make visible during volume creation.
Now, when creating a new volume, you only see the aggregates that are allowed to be used for an individual SVM.
We are now planning to name our aggregates based on workloads/projects, instead of less meaningful aggr1_fas8060 type name. We no longer need some type of workload spreadsheet to figure our what goes where...
.