ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: Lags on all (deployed) protocols
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
Last night, we had a strange behaviour on one of our filers. It's the second time within a year we noticed problems like that.
The server-admins told me, that they had problems with the databases because of write & read failures to the iSCSI-attached disks.
Because of that, I have checked the storage system log, and there are some strange messages:
Thu May 20 02:00:00 CEST [US-S001KAS: kern.uptime.filer:info]: 2:00am up 147 days, 1:49 18905916983 NFS ops, 990731558 CIFS ops, 572 HTTP ops, 703042 FCP ops, 16154794031 iSCSI ops
Thu May 20 02:01:35 CEST [US-S001KAS: wafl.volume.snap.autoDelete:info]: Deleting snapshot 'sqlinfo__crm-v001test__recent' in volume 'crmv001test_iscsi_snap' to recover storage
Thu May 20 02:04:10 CEST [US-S001KAS: wafl.volume.snap.autoDelete:info]: Deleting snapshot 'sqlinfo__crm-v001test__recent' in volume 'crmv001test_iscsi_snap' to recover storage
Thu May 20 02:04:42 CEST [US-S001KAS: wafl.snap.delete:info]: Snapshot copy sqlinfo__crms-v001__recent16753_deleting on volume crmsv001_iscsi_snap NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (119, 766396).
Thu May 20 02:04:56 CEST [US-S001KAS: wafl.snap.delete:info]: Snapshot copy sqlsnap__crm-v001test_05-13-2010_00.00.10 on volume crmv001test_iscsi_db NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (31, 363470).
Thu May 20 02:05:13 CEST [US-S001KAS: wafl.snap.delete:info]: Snapshot copy sqlsnap__crm-v001test_05-13-2010_00.00.10 on volume crmv001test_iscsi_logs NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (31, 846826).
Thu May 20 02:06:43 CEST [US-S001KAS: wafl.volume.snap.autoDelete:info]: Deleting snapshot 'sqlinfo__crm-v001test__recent' in volume 'crmv001test_iscsi_snap' to recover storage
Thu May 20 02:07:03 CEST [US-S001KAS: app.log.info:info]: CRM-V001TEST: SMSQL Version 5.0: (309) SnapBackup: SnapManager for SQL Server online full backup completed successfully. **** FULL DATABASE BACKUP RESULT SUMMARY #1 **** Backup Time: 05-20-2010_02.00.34 Backup Group [#1]: #1 : [CRM-V001TEST - DebitBAGECRMTest_MSCRM] : OK #2 : [CRM-V001TEST - DebitENFACRMTest_MSCRM] : OK #3 : [CRM-V001TEST - EnergieberatungTest_MSCRM] : OK #4 : [CRM-V001TEST - ReportServer] : OK #5 : [CRM-V001TEST - ReportServerTemp
Thu May 20 02:07:27 CEST [US-S001KAS: wafl.snap.delete:info]: Snapshot copy sqlinfo__crms-v001__recent5629_deleting on volume crmsv001_iscsi_snap NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (120, 766416).
Thu May 20 02:14:26 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:oradb-v006.kt.lunet.ch) sent LUN Reset request, aborting all SCSI commands on lun 1
Thu May 20 02:14:39 CEST [ussluz-v001@US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:sccm-v013.sluz.ch) sent LUN Reset request, aborting all SCSI commands on lun 0
Thu May 20 02:14:41 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:oradb-v003.kt.lunet.ch) sent LUN Reset request, aborting all SCSI commands on lun 2
Thu May 20 02:14:46 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:mxm-s401mur.edulu.lunet.ch) sent LUN Reset request, aborting all SCSI commands on lun 2
Thu May 20 02:14:46 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:mxm-s301kas.kt.lunet.ch) sent LUN Reset request, aborting all SCSI commands on lun 15
Thu May 20 02:15:15 CEST [US-S001KAS: NwkThd_00:warning]: NFS response to client 10.64.120.215 for volume 0x15fec782 was slow, op was v3 write, 108 > 60 (in seconds)
Thu May 20 02:15:15 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: New session from initiator iqn.1991-05.com.microsoft:oradb-v006.kt.lunet.ch at IP addr 10.64.120.208
Thu May 20 02:15:15 CEST [ussluz-v001@US-S001KAS: iscsi.notice:notice]: ISCSI: New session from initiator iqn.1991-05.com.microsoft:sccm-v013.sluz.ch at IP addr 10.64.121.185
Thu May 20 02:15:17 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:mxm-s301kas.kt.lunet.ch) sent Target Warm Reset request, aborting all SCSI commands
Thu May 20 02:15:17 CEST last message repeated 9 times
Thu May 20 02:15:18 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:mxm-s401mur.edulu.lunet.ch) sent Target Warm Reset request, aborting all SCSI commands
Thu May 20 02:15:18 CEST last message repeated 5 times
Thu May 20 02:15:48 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: New session from initiator iqn.1991-05.com.microsoft:mxm-s301kas.kt.lunet.ch at IP addr 10.64.120.222
Thu May 20 02:15:48 CEST last message repeated 2 times
Thu May 20 02:15:48 CEST [US-S001KAS: iscsi.notice:notice]: ISCSI: New session from initiator iqn.1991-05.com.microsoft:mxm-s301kas.kt.lunet.ch at IP addr 10.64.120.221
Thu May 20 02:26:09 CEST [US-S001KAS: wafl.snap.delete:info]: Snapshot copy 2010-05-18 00_00_06_esxprod0_nfs_sys on volume esxprod0_nfs_sys NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (244, 9516239).
Thu May 20 03:00:00 CEST [US-S001KAS: kern.uptime.filer:info]: 3:00am up 147 days, 2:49 18913200105 NFS ops, 990772097 CIFS ops, 572 HTTP ops, 703234 FCP ops, 16159385821 iSCSI ops
Thu May 20 03:27:37 CEST [US-S001KAS: wafl.snap.delete:info]: Snapshot copy 2010-05-18 01_00_08_esxprod0_nfs_sys on volume esxprod0_nfs_sys NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (246, 9516632).
Thu May 20 04:00:00 CEST [US-S001KAS: kern.uptime.filer:info]: 4:00am up 147 days, 3:49 18918102748 NFS ops, 990772792 CIFS ops, 572 HTTP ops, 703426 FCP ops, 16163496848 iSCSI ops
Thu May 20 04:14:40 CEST [ussluz-v001@US-S001KAS: iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:sccm-v013.sluz.ch) sent LUN Reset request, aborting all SCSI commands on lun 0
Thu May 20 04:14:48 CEST [US-S001KAS: NwkThd_00:warning]: NFS response to client 10.64.120.137 for volume 0x126281ee was slow, op was v3 write, 69 > 60 (in seconds)
Thu May 20 04:29:12 CEST [US-S001KAS: wafl.snap.delete:info]: Snapshot copy 2010-05-18 02_00_09_esxprod0_nfs_sys on volume esxprod0_nfs_sys NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (248, 9516917).
Thu May 20 04:37:36 CEST [US-S001KAS: app.log.info:info]: SPS-V001: SnapDrive 6.0.2: (134) Snapshot Copy event: For the description of this event please check the application event log on the host system.
Thu May 20 04:37:45 CEST [US-S001KAS: app.log.info:info]: SPS-V001: SnapDrive 6.0.2: (134) Snapshot Copy event: For the description of this event please check the application event log on the host system.
Thu May 20 04:46:36 CEST [US-S001KAS: wafl.volume.snap.autoDelete:info]: Deleting snapshot 'sqlsnap__sps-v001__recent' in volume 'spsv001_iscsi_index' to recover storage
A lot of iSCSI sessions were reseted by the initators because the target did not respond in the configured value. But at the same time, there was also a problem with the clients using NFS. Operation Manager monitored high write latency while we had the problems:
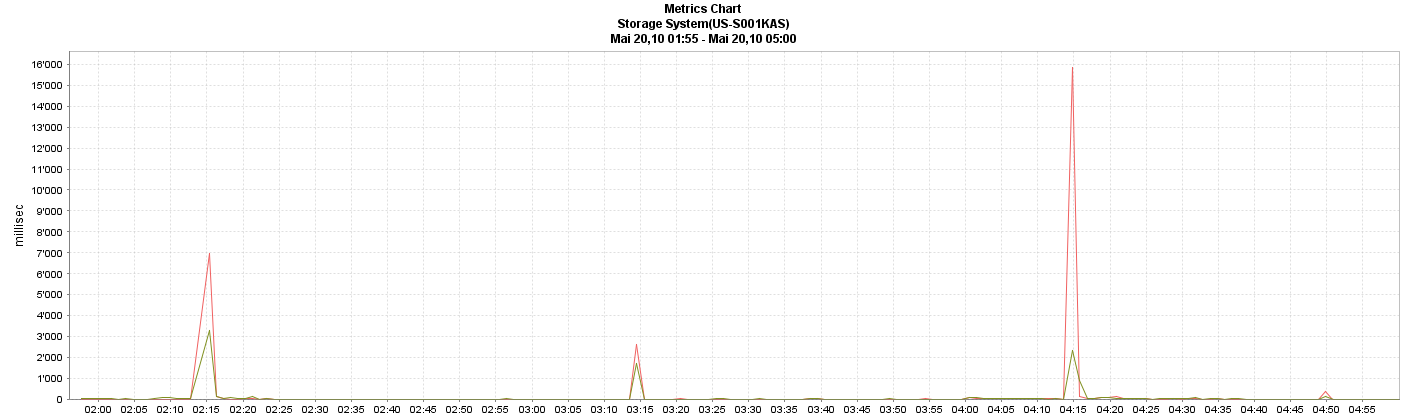
Red: Overall NFSv3 Write Latency
Green: Overall iSCSI Write Latency
| 20.05.2010 | 01:47:37 | WinHttpAutoProxySvc | Information | 12517 | The WinHTTP Web Proxy Auto-Discovery Service suspended operation. |
| 20.05.2010 | 01:47:37 | WinHttpAutoProxySvc | Information | 12503 | The WinHTTP Web Proxy Auto-Discovery Service has been idle for 15 minutes, it will be shut down. |
| 20.05.2010 | 02:14:33 | symmpi | Error | 9 | The device, \Device\Scsi\symmpi1, did not respond within the timeout period. |
| 20.05.2010 | 02:14:41 | iScsiPrt | Error | 39 | Initiator sent a task management command to reset the target. The target name is given in the dump data. |
| 20.05.2010 | 02:14:57 | Disk | Error | 11 | The driver detected a controller error on \Device\Harddisk0\DR0. |
| 20.05.2010 | 02:14:57 | symmpi | Error | 15 | The device, \Device\Scsi\symmpi1, is not ready for access yet. |
| 20.05.2010 | 02:14:57 | Disk | Error | 11 | The driver detected a controller error on \Device\Harddisk0\DR0. |
| 20.05.2010 | 02:14:57 | symmpi | Error | 15 | The device, \Device\Scsi\symmpi1, is not ready for access yet. |
| 20.05.2010 | 02:14:57 | Disk | Error | 11 | The driver detected a controller error on \Device\Harddisk1\DR1. |
| 20.05.2010 | 02:14:57 | symmpi | Error | 15 | The device, \Device\Scsi\symmpi1, is not ready for access yet. |
| 20.05.2010 | 02:15:01 | iScsiPrt | Error | 29 | Target rejected an iSCSI PDU sent by the initiator. Dump data contains the rejected PDU. |
| 20.05.2010 | 02:15:01 | iScsiPrt | Error | 39 | Initiator sent a task management command to reset the target. The target name is given in the dump data. |
| 20.05.2010 | 02:15:01 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:01 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:01 | iScsiPrt | Error | 49 | Target failed to respond in time to a Task Management request. |
| 20.05.2010 | 02:15:11 | iScsiPrt | Error | 29 | Target rejected an iSCSI PDU sent by the initiator. Dump data contains the rejected PDU. |
| 20.05.2010 | 02:15:11 | iScsiPrt | Error | 27 | Initiator could not find a match for the initiator task tag in the received PDU. Dump data contains the entire iSCSI header. |
| 20.05.2010 | 02:15:11 | iScsiPrt | Error | 39 | Initiator sent a task management command to reset the target. The target name is given in the dump data. |
| 20.05.2010 | 02:15:11 | iScsiPrt | Error | 39 | Initiator sent a task management command to reset the target. The target name is given in the dump data. |
| 20.05.2010 | 02:15:15 | iScsiPrt | Error | 27 | Initiator could not find a match for the initiator task tag in the received PDU. Dump data contains the entire iSCSI header. |
| 20.05.2010 | 02:15:15 | iScsiPrt | Error | 27 | Initiator could not find a match for the initiator task tag in the received PDU. Dump data contains the entire iSCSI header. |
| 20.05.2010 | 02:15:15 | iScsiPrt | Error | 27 | Initiator could not find a match for the initiator task tag in the received PDU. Dump data contains the entire iSCSI header. |
| 20.05.2010 | 02:15:15 | iScsiPrt | Error | 27 | Initiator could not find a match for the initiator task tag in the received PDU. Dump data contains the entire iSCSI header. |
| 20.05.2010 | 02:15:15 | iScsiPrt | Error | 27 | Initiator could not find a match for the initiator task tag in the received PDU. Dump data contains the entire iSCSI header. |
| 20.05.2010 | 02:15:15 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:15 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:21 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:21 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:21 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:21 | iScsiPrt | Error | 9 | Target did not respond in time for a SCSI request. The CDB is given in the dump data. |
| 20.05.2010 | 02:15:21 | iScsiPrt | Error | 49 | Target failed to respond in time to a Task Management request. |
| 20.05.2010 | 02:15:31 | iScsiPrt | Error | 49 | Target failed to respond in time to a Task Management request. |
There are a dozen servers (virtual and physicial systems) with the same error messages in the eventlog.
Oracle, Exchange and MSSQL crashed because of the disk timeout.
The oracle-dba gave me the following logfile:
Thu May 20 02:14:56 2010
Errors in file d:\app\dktoracle\admin\konsulp\bdump\konsulp_ckpt_1888.trc:
ORA-00221: error on write to control file
ORA-00206: error in writing (block 3, # blocks 1) of control file
ORA-00202: control file: 'D:\APP\DKTORACLE\ORADATA\KONSULP\LOG\CONTROL02.CTL'
ORA-27070: async read/write failed
OSD-04016: Error queuing an asynchronous I/O request.
O/S-Error: (OS 2) Das System kann die angegebene Datei nicht finden. //the system could not find the file specified
ORA-00206: error in writing (block 3, # blocks 1) of control file
ORA-00202: control file: 'D:\APP\DKTORACLE\ORADATA\KONSULP\DATA1\CONTROL01.CTL'
ORA-27070: async read/write failed
OSD-04016: Error queuing an asynchronous I/O request.
O/S-Error: (OS 2) Das System kann die angegebene Datei nicht finden. //""
Thu May 20 02:14:56 2010
CKPT: terminating instance due to error 221
Thu May 20 02:14:56 2010
Errors in file d:\app\dktoracle\admin\konsulp\bdump\konsulp_pmon_2884.trc:
ORA-00221: error on write to control file
I also noticed a high cpu utilization at this time:
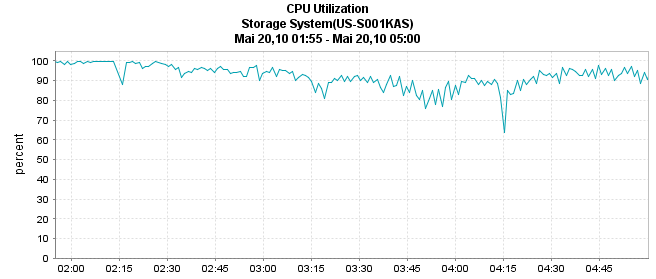
The only thing that's running at this time are dedupe-schedules and some NDMP-Backups in the background.
Has anyone seen a similar behaviour before? If yes, what could be the reason for this?
Kind regards,
Adrian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Are you running Performance Advisor? That's the next place I'd look...at least could pin down what aggregates were busy, cpu load, volume/lun busy-ness, etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Firstly, if you dont have a support call opened for this issue, I'd strongly suggest you do so.
I did some checking on the performance counters sent by your system in autosupport, and 90+% CPU utilisation between midnight and 6:00AM (GMT) seems to be fairly normal for your site and your latency generally remains pretty good throughout those times.
The problem appears to be that I/O was blocked for over 60 seconds across both iSCSI and NFS which is really very unusual. The write latencys spike a 2:15, 3:15, and 4:15, and even though 7,000-15,000ms response times are evil, they shouldnt be sufficient to cause a SCSI timeout. What I find suspicious here is the regularity of the spikes at each of these time intervals, this might indicate staggered backup or dedup schedules on the controller, or it might indicate some external event.
One theory is that what you are seeing here is a symptom, rather than a cause. i.e. something like a networking problem is causing the clients to lose connections to the filer and they issue a iSCSI bus reset, which in turn causes OnTAP to do a bunch of work that is CPU intensive, but this takes a long time to complete because the CPU's are being hammered by dedup and backup runs. NDMP dumps are surprisingly CPU hungry, and some Dedup phases can be too, as I said before, your system handles this pretty well most of the time, but I think the extra load incurred by the bus resets may be pushing them over the edge which results in the high write latencies for a short period of time.
Of course the thing that undermines that theory is that the events at 2:15 and 4:15 were accompanied by SCSI Bus reseta and caused NFS writes to exceed 60 seconds, but the smaller one at 3:15 didnt. Having said that you'll see that the CPU utilisation actually dropped breifly at each of these three times, inferring that the load coming into the box decreased temporarily. This says to me that the something outside the controller was the problem and that it interrupted the communication between the controller and the clients. As to why write latency spiked dramatically during each of these events, I'm reasonably sure that we report write latency as the elapsed time between when we recieve a packet from a client containing a write request to the time the client acknowleges that weve told it that we've commited the write to stable storage (NVRAM). If something was to slow down the ACK packet back from the client, then this would be included in the overall latency.
If you trigger an autosupport for the system and raise a support call, the global support center will be able to analyse the data and should be able to find a root cause for you, even if it lies outside the controller.
Regards
John Martin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thank you for your response.
last time we had a similar issue, i opened a case and they told me to collect perfstats until the problem appears again.
but as the problem never appeared again, we closed the case and disabled the perfstat-task.
I will not open a new case to just get the same information as last time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have seen similar lag shortly after a number of large snapshots delete simultaneously. This behavior appears to affect more than just the aggregate containing the volumes. I believe the behavior appeared after the move to 7.3.2 (no patch). Support has opined that a move to a later patch set such as 7.3.2P7 will probably resolve the issue as there are many similar issues listed as bugs (see the list at: http://now.netapp.com/NOW/download/software/ontap/7.3.2P7/). We are going to live with the problem until we move to 7.3.3P1.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The same issue. iSCSI sessions were terminated when several old snapshots were deleted.
SQL and Exchange were crashed ;-/
Mon Mar 14 00:38:55 MSK [app.log.info:info]: MSK-HQ-EX1: SME Version 6.0: (129) General: (Exchange Version 8.3 (Build 83.6))
Mon Mar 14 00:39:11 MSK [lun.map:info]: LUN /vol/ex07data/{f1e08301-54a1-46ed-8731-f86e3e335de6}.rws was mapped to initiator group msk-hq-ex1=5
Mon Mar 14 00:53:05 MSK [lun.map.unmap:info]: LUN /vol/sql3_data/{1ae3afaa-14f7-4cc9-9af2-4089e7503678}.rws unmapped from initiator group msk-hq-sql3
Mon Mar 14 00:53:05 MSK [lun.destroy:info]: LUN /vol/sql3_data/{1ae3afaa-14f7-4cc9-9af2-4089e7503678}.rws destroyed
Mon Mar 14 00:53:27 MSK [lun.map.unmap:info]: LUN /vol/sql3_logs/{f624354b-3c94-4e33-a0d6-80614fe5c465}.rws unmapped from initiator group msk-hq-sql3
Mon Mar 14 00:53:27 MSK [lun.destroy:info]: LUN /vol/sql3_logs/{f624354b-3c94-4e33-a0d6-80614fe5c465}.rws destroyed
Mon Mar 14 00:53:45 MSK [wafl.snap.delete:info]: Snapshot copy sqlsnap__msk-hq-sql3_02-21-2011_00.00.09__weekly on volume sql3_data NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (163, 5324910).
Mon Mar 14 00:54:14 MSK [wafl.snap.delete:info]: Snapshot copy sqlsnap__msk-hq-sql3_02-21-2011_00.00.09__weekly on volume sql3_logs NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (122, 6846389).
Mon Mar 14 00:54:43 MSK [wafl.snap.delete:info]: Snapshot copy sqlinfo__msk-hq-sql3_02-21-2011_00.00.09__weekly on volume sql3_snapinfo NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (20, 3653205).
Mon Mar 14 00:54:46 MSK [app.log.info:info]: MSK-HQ-SQL3: SMSQL Version 5.0: (309) SnapBackup: SnapManager for SQL Server online full backup completed successfully. **** FULL DATABASE BACKUP RESULT SUMMARY #1 **** Backup Time: 03-14-2011_00.02.29 Backup Group [#1]: #1 : [MSK-HQ-SQL3 - xxxx] : ...
Mon Mar 14 00:57:49 MSK [wafl.snap.delete:info]: Snapshot copy @snapmir@{D0830DD7-2E3D-470F-B800-929FCAB1D60A} on volume sql3_data NetApp was deleted by the Data ONTAP function zapi_snapshot_delete. The unique ID for this Snapshot copy is (200, 5531271).
Mon Mar 14 01:00:00 MSK [kern.uptime.filer:info]: 1:00am up 309 days, 16:31 0 NFS ops, 1884412733 CIFS ops, 2952 HTTP ops, 0 FCP ops, 11809686265 iSCSI ops
Mon Mar 14 01:00:38 MSK [iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:msk-hq-ex1) sent LUN Reset request, aborting all SCSI commands on lun 0
Mon Mar 14 01:00:59 MSK [iscsi.notice:notice]: ISCSI: Initiator (iqn.1991-05.com.microsoft:ex1-ex2010.ex2010.msk.local) sent LUN Reset request, aborting all SCSI commands on lun 2
Mon Mar 14 01:01:08 MSK [iscsi.notice:notice]: ISCSI: New session from initiator iqn.1991-05.com.microsoft:msk-hq-sql3 at IP addr 192.168.43.1
Mon Mar 14 01:01:08 MSK [iscsi.notice:notice]: ISCSI: New session from initiator iqn.1991-05.com.microsoft:msk-hq-ex1 at IP addr 192.168.41.1
ONTAP 7.3.3 without P.
I don't see iSCSI fixes in 7.3.3 P1 - P5.
It seems the latest ONTAP release (7.3.3) has this bug.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What version of ONTAP are you using?
I experienced an issue similar to this about a year ago which was ONTAP bug related. The solution was to upgrade the ONTAP version, from what I recall it was a bug in ONTAP 7.2 which was fixed in ONTAP 7.3.
