This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: Oracle Database 11.2 slow performance on NetApp FAS3240
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Oracle Database 11.2 slow performance on NetApp FAS3240
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
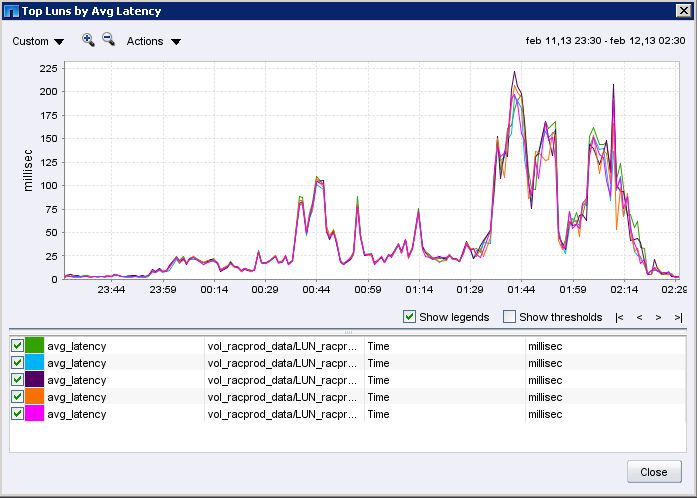

Throughput

On "controller 2" on the same a aggregate we have created several volume for deploy a SQL Server 2012 Enterprise Edition used by our BI team
Latency

Throughput
My feeling is that the storage has a poor performance when Oracle execute multiblock IO operations, Oracle could execute bigger (in size) multiblock IO operations than SQL Server because of that the issue only happen with Oracle.
Please, Any one running Oracle with a similar environment has detected any similar issue or could give me any feedback about how can I solve this issue.
Thank you in advance, regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Please, any one has any idea or have a similar scenario.
Thank you in advance, regards.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
have you checked for partition misalignment?
priv set diag
lun show -v
/vol/w2k8_server/mproot.lun 5.0g (5371107840) (r/w, online, mapped)
Comment: " "
Serial#: XXXXXXXXXXX
Share: none
Space Reservation: disabled
Multiprotocol Type: windows_gpt
Maps: w2k8-server=0
Occupied Size: 1.3g (1352630272)
Creation Time: Mon Oct 6 17:38:38 CEST 2008
Alignment: indeterminate
Cluster Shared Volume Information: 0x0
Space_alloc: disabled
See what "Alignment" row displays.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Thomas,
Thank you about your feedback.
Yes, we have checked for partition misaligment, all the luns show "Alignment: aligned" for the volume created to storage the database data, the output of one of the LUNs is:
LUNs from one controller:
/vol/vol_racprod_data/LUN_racprod_A_data0 100g (107374182400) (r/w, online, mapped)
Serial#: GoeKc4nt27zN
Share: none
Space Reservation: enabled
Multiprotocol Type: linux
Maps: 36=10 38=10
Occupied Size: 97.7g (104879898624)
Creation Time: Wed Nov 28 17:19:30 CET 2012
Alignment: aligned
Cluster Shared Volume Information: 0x0
LUNs from the other controller:
/vol/vol_racprod_B_filesystem/LUN_racprod_B_filesystem0 100g (107374182400) (r/w, online, mapped)
Serial#: GoeKcZpe6WXH
Share: none
Space Reservation: enabled
Multiprotocol Type: linux
Maps: 38=8 36=9
Occupied Size: 99.9g (107282169856)
Creation Time: Tue Feb 26 15:39:55 CET 2013
Alignment: aligned
Cluster Shared Volume Information: 0x0
We also have checked the reallocate status for each volume and is under threshold (4).
Any other suggestion are welcome.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
during times of performance problems, please be so kind to run a "sysstat -x 1" for about a minute as well as an "priv set diag; sysstat -M 1;priv set" for about a minute and post that output.
Cheers,
Thomas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Thomas,
I have executed the following test: Export datapump of two tables with size 42,3 gbytes and the other one 35,1 Gbytes with the options: PARALLEL=2 EXCLUDE=GRANT,INDEX,CONSTRAINT,TRIGGER
NetApp Management Console reports the following latency peak:
Controller 1 (source data/read operations)
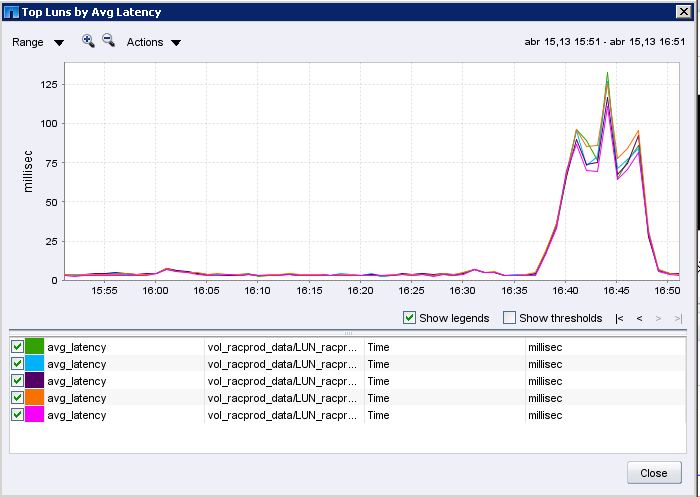
Controller 2 (destination data/write operations)
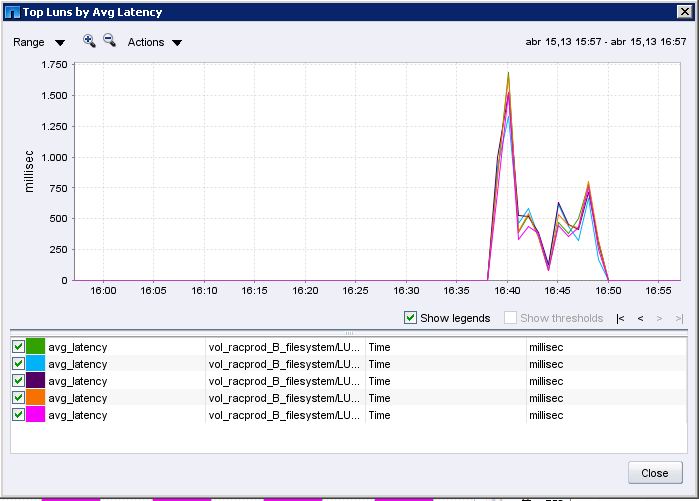
Output for the requested commands (executed at 16:42)
- Controller 1 (source data/read operations)
STOMTSZRH020> sysstat -x 1
CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s
in out read write read write age hit time ty util in out in out
30% 0 0 0 967 1 1 134160 111764 0 0 2s 69% 100% :f 100% 0 963 0 4852 103950 0 0
31% 0 0 0 925 0 1 135556 50624 0 0 3s 75% 100% :f 100% 0 919 0 5810 115403 0 0
28% 0 0 0 876 1 0 147504 39784 0 0 3s 72% 66% : 100% 3 867 0 500 116145 0 0
32% 0 0 0 948 0 1 191312 24 0 0 2s 65% 0% - 100% 0 940 0 3107 150673 0 0
26% 0 0 0 509 1 0 123888 0 0 0 2s 70% 0% - 100% 0 499 0 358 100698 0 0
33% 0 0 0 695 0 1 189083 0 0 0 2s 60% 0% - 100% 0 673 0 778 129569 0 0
33% 0 0 0 1051 1 0 168644 24 0 0 1s 69% 0% - 100% 0 1015 0 3611 145716 0 0
32% 0 0 0 559 1 9 176932 8 0 0 2s 63% 0% - 100% 10 543 0 4697 135126 0 0
57% 0 0 0 566 3 34 169447 66953 0 0 2s 87% 41% Hn 100% 0 556 0 4331 132790 0 0
50% 0 0 0 1405 1 53 143070 190196 0 0 2s 89% 100% :n 100% 0 1377 0 11274 105535 0 0
37% 0 0 0 710 1 7 173932 31872 0 0 3s 73% 100% :s 100% 0 708 0 5359 143653 0 0
36% 0 0 0 1071 0 1 185860 16416 0 0 3s 63% 100% :f 100% 0 1063 0 1840 148832 0 0
34% 0 0 0 1655 1 0 186844 3616 0 0 2s 60% 100% :f 100% 3 1650 0 8683 142281 0 0
31% 0 0 0 973 0 1 166516 12264 0 0 2s 66% 100% :f 100% 0 963 0 835 136860 0 0
32% 0 0 0 921 1 0 172204 106364 0 0 3 54% 100% :f 100% 4 807 0 636 128427 0 0
33% 0 0 0 1793 0 1 144440 75820 0 0 2s 69% 100% :f 100% 0 1791 0 14816 128297 0 0
26% 0 0 0 443 1 0 121692 115680 0 0 2s 69% 100% :f 93% 0 429 0 512 101560 0 0
23% 0 0 0 653 1 1 108144 49520 0 0 2s 81% 89% : 87% 3 648 0 1312 94758 0 0
16% 0 0 0 742 0 1 80904 24 0 0 3s 75% 0% - 47% 0 742 0 4872 73284 0 0
CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s
in out read write read write age hit time ty util in out in out
4% 0 0 0 384 1 1 3672 0 0 0 3s 55% 0% - 18% 0 370 0 5379 2538 0 0
10% 0 0 0 1104 0 2 5172 0 0 0 3s 84% 0% - 19% 0 1092 0 12569 2825 0 0
8% 0 0 0 917 2 2 6496 24 0 0 3s 70% 0% - 29% 0 915 0 7444 5332 0 0
10% 0 0 0 962 0 1 2100 8 0 0 3s 85% 0% - 15% 3 953 0 13224 2193 0 0
7% 0 0 0 1697 1 0 3492 0 0 0 3s 79% 0% - 23% 0 1693 0 16085 3412 0 0
31% 0 0 0 1937 0 1 148812 24 0 0 7s 70% 0% - 97% 0 1933 0 11834 105887 0 0
33% 0 0 0 1570 8 20 137416 0 0 0 6s 72% 0% - 96% 0 1566 0 7351 105443 0 0
34% 0 0 0 1365 1 42 164824 0 0 0 1s 68% 0% - 100% 0 1343 0 8781 147850 0 0
37% 0 0 0 961 2 31 175972 7306 0 0 1s 78% 11% Tn 100% 3 912 0 4710 141802 0 0
53% 0 0 0 503 0 1 103720 131160 0 0 1s 90% 100% :s 100% 0 501 0 4775 68666 0 0
37% 0 0 0 751 3 4 181288 20428 0 0 3 65% 100% :s 100% 0 739 0 2617 142585 0 0
40% 0 0 0 1432 0 1 160172 83584 0 0 1s 75% 100% :f 100% 0 1418 0 9119 121772 0 0
35% 0 0 0 658 2 2 148312 64856 0 0 1s 75% 100% :f 100% 0 642 0 1124 120170 0 0
33% 0 0 0 941 1 2 170488 43612 0 0 1s 73% 100% :f 100% 3 928 0 842 138561 0 0
36% 0 0 0 1660 1 0 196884 39444 0 0 1s 71% 100% :f 100% 0 1658 0 12694 163402 0 0
35% 0 0 0 1010 5 12 182368 87712 0 0 1s 66% 100% :f 100% 0 1000 0 1784 145221 0 0
33% 0 0 0 889 1 2 149584 85980 0 0 1s 70% 100% :f 100% 0 877 0 1101 123594 0 0
34% 0 0 0 1701 0 1 165204 3180 0 0 1s 66% 39% : 100% 0 1649 0 10153 122686 0 0
34% 0 0 0 1234 1 0 169308 8 0 0 0s 69% 0% - 100% 3 1183 0 2156 136115 0 0
36% 0 0 0 1078 0 1 204584 0 0 0 1s 69% 0% - 100% 0 1064 0 4999 178453 0 0
STOMTSZRH020*> sysstat -M 1
ANY1+ ANY2+ ANY3+ ANY4+ AVG CPU0 CPU1 CPU2 CPU3 Network Protocol Cluster Storage Raid Target Kahuna WAFL_Ex(Kahu) WAFL_XClean SM_Exempt Cifs Exempt Intr Host Ops/s CP
52% 23% 7% 2% 21% 16% 22% 27% 21% 1% 0% 0% 12% 16% 4% 12% 25%( 19%) 1% 0% 0% 13% 2% 1% 383 100%
54% 26% 9% 2% 23% 19% 25% 29% 20% 1% 0% 0% 12% 16% 5% 8% 33%( 24%) 2% 0% 0% 14% 2% 1% 793 100%
59% 29% 11% 3% 26% 22% 26% 33% 24% 1% 0% 0% 12% 18% 4% 13% 30%( 22%) 9% 0% 0% 16% 2% 1% 470 100%
52% 25% 9% 2% 23% 18% 25% 29% 19% 1% 0% 0% 11% 17% 4% 6% 35%( 25%) 0% 0% 0% 14% 2% 2% 567 100%
51% 25% 8% 2% 22% 18% 24% 28% 18% 1% 0% 0% 12% 17% 5% 7% 30%( 22%) 0% 0% 0% 14% 2% 1% 652 100%
54% 27% 9% 2% 24% 19% 24% 32% 19% 1% 0% 0% 11% 19% 4% 7% 31%( 23%) 0% 0% 0% 18% 2% 1% 590 100%
41% 19% 6% 1% 17% 13% 18% 22% 15% 1% 0% 0% 9% 13% 3% 7% 22%( 16%) 0% 0% 0% 12% 2% 1% 325 100%
24% 8% 2% 0% 9% 8% 8% 12% 9% 1% 0% 0% 3% 7% 2% 7% 6%( 5%) 0% 0% 0% 8% 2% 1% 778 100%
14% 5% 1% 0% 5% 4% 5% 7% 5% 1% 0% 0% 3% 4% 1% 4% 2%( 2%) 0% 0% 0% 5% 1% 1% 234 85%
14% 4% 1% 0% 6% 5% 7% 6% 4% 1% 0% 0% 3% 3% 1% 2% 7%( 5%) 0% 0% 0% 2% 1% 2% 298 0%
10% 2% 1% 0% 4% 3% 4% 3% 4% 1% 0% 0% 3% 1% 1% 3% 3%( 3%) 0% 0% 0% 1% 1% 1% 404 0%
13% 4% 1% 0% 5% 5% 5% 3% 7% 1% 0% 0% 2% 1% 2% 5% 6%( 4%) 0% 0% 0% 0% 2% 1% 595 0%
50% 23% 8% 2% 21% 17% 22% 27% 19% 1% 0% 0% 11% 14% 6% 7% 33%( 25%) 0% 0% 0% 11% 2% 1% 1401 0%
48% 22% 8% 2% 21% 18% 22% 24% 18% 1% 0% 0% 10% 12% 7% 6% 34%( 24%) 0% 0% 0% 10% 2% 1% 1755 0%
50% 22% 7% 2% 21% 18% 21% 26% 17% 1% 0% 0% 11% 13% 6% 6% 32%( 24%) 0% 0% 0% 10% 2% 1% 1035 0%
44% 18% 5% 1% 18% 15% 19% 21% 15% 1% 0% 0% 9% 12% 4% 6% 27%( 20%) 0% 0% 0% 10% 2% 1% 477 0%
47% 22% 7% 2% 20% 17% 21% 25% 18% 1% 0% 0% 10% 13% 4% 6% 33%( 24%) 0% 0% 0% 11% 2% 1% 463 0%
38% 15% 5% 1% 15% 13% 15% 17% 15% 1% 0% 0% 7% 8% 4% 7% 23%( 17%) 0% 0% 0% 7% 2% 1% 1076 0%
22% 4% 1% 0% 7% 5% 5% 5% 13% 1% 0% 0% 3% 3% 1% 12% 2%( 2%) 4% 0% 0% 1% 1% 1% 431 12%
ANY1+ ANY2+ ANY3+ ANY4+ AVG CPU0 CPU1 CPU2 CPU3 Network Protocol Cluster Storage Raid Target Kahuna WAFL_Ex(Kahu) WAFL_XClean SM_Exempt Cifs Exempt Intr Host Ops/s CP
52% 18% 6% 2% 20% 12% 16% 21% 31% 1% 0% 0% 7% 13% 1% 28% 6%( 4%) 11% 0% 0% 11% 1% 1% 588 100%
21% 6% 2% 0% 8% 6% 7% 8% 11% 1% 0% 0% 3% 4% 2% 9% 5%( 4%) 0% 0% 0% 5% 1% 1% 927 100%
20% 6% 2% 1% 8% 7% 8% 10% 7% 1% 0% 0% 4% 5% 3% 4% 7%( 5%) 0% 0% 0% 5% 1% 1% 1094 100%
37% 18% 8% 4% 17% 15% 18% 21% 16% 1% 0% 0% 7% 10% 6% 7% 27%( 16%) 0% 0% 0% 9% 2% 1% 2880 100%
54% 27% 10% 3% 24% 19% 26% 31% 21% 1% 0% 0% 12% 16% 7% 7% 37%( 26%) 0% 0% 0% 13% 2% 1% 1475 100%
53% 25% 9% 2% 23% 17% 25% 30% 20% 1% 0% 0% 12% 17% 7% 8% 31%( 23%) 0% 0% 0% 13% 2% 1% 948 100%
55% 27% 9% 2% 24% 18% 27% 31% 19% 1% 0% 0% 12% 17% 7% 7% 34%( 25%) 0% 0% 0% 15% 2% 1% 842 100%
58% 31% 13% 5% 27% 21% 29% 34% 25% 1% 0% 0% 12% 18% 9% 8% 43%( 28%) 0% 0% 0% 15% 2% 1% 2330 100%
51% 24% 9% 2% 22% 17% 24% 27% 20% 1% 0% 0% 11% 14% 8% 8% 34%( 25%) 0% 0% 0% 11% 2% 1% 1802 72%
52% 23% 7% 2% 22% 18% 23% 28% 18% 1% 0% 0% 11% 14% 5% 6% 33%( 25%) 0% 0% 0% 11% 2% 1% 812 0%
53% 26% 10% 4% 24% 20% 26% 28% 22% 1% 0% 0% 11% 14% 7% 7% 42%( 27%) 0% 0% 0% 11% 2% 1% 2165 0%
47% 21% 7% 1% 20% 16% 22% 25% 15% 1% 0% 0% 11% 13% 5% 5% 31%( 24%) 0% 0% 0% 10% 2% 1% 745 0%
48% 22% 7% 2% 20% 16% 23% 25% 17% 1% 0% 0% 11% 14% 5% 6% 31%( 23%) 0% 0% 0% 11% 2% 1% 576 0%
51% 25% 10% 4% 24% 21% 24% 28% 21% 1% 0% 0% 11% 14% 8% 7% 39%( 26%) 0% 0% 0% 11% 2% 1% 2481 0%
49% 22% 7% 1% 20% 17% 22% 26% 16% 1% 0% 0% 11% 14% 5% 6% 31%( 23%) 0% 0% 0% 11% 2% 1% 621 0%
54% 26% 9% 2% 23% 20% 23% 29% 21% 1% 0% 0% 11% 15% 6% 8% 36%( 26%) 0% 0% 0% 12% 2% 1% 1003 0%
56% 27% 10% 3% 25% 21% 25% 30% 22% 1% 0% 0% 11% 14% 7% 7% 42%( 29%) 0% 0% 0% 13% 2% 1% 1990 0%
28% 10% 3% 1% 11% 9% 12% 13% 11% 1% 0% 0% 6% 6% 3% 5% 16%( 12%) 0% 0% 0% 4% 2% 1% 772 0%
35% 8% 3% 1% 12% 7% 8% 9% 24% 1% 0% 0% 4% 5% 1% 23% 3%( 2%) 6% 0% 0% 3% 1% 1% 455 27%
70% 32% 14% 5% 31% 20% 26% 32% 43% 1% 0% 0% 10% 18% 3% 35% 24%( 14%) 14% 0% 0% 16% 2% 1% 1307 100%
- Controller 2 (destination data/write operations)
STOMTSZRH022> sysstat -x 1
CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s
in out read write read write age hit time ty util in out in out
27% 0 0 0 964 2 29 12680 74424 0 0 15s 98% 100% :f 26% 0 964 0 81903 3919 0 0
13% 0 0 0 806 2 54 4272 75604 0 0 15s 96% 100% :f 14% 0 796 0 48193 4850 0 0
16% 0 0 0 928 1 2 1092 45676 0 0 16s 97% 62% : 12% 0 928 0 66323 4963 0 0
39% 0 0 0 1534 0 1 10424 114156 0 0 16s 98% 47% Ff 32% 10 1523 0 75067 6098 0 0
17% 0 0 0 998 1 0 4300 96052 0 0 15s 95% 100% :f 14% 0 991 0 67154 4950 0 0
14% 0 0 0 1073 0 1 7952 75848 0 0 15s 96% 100% :f 14% 0 1073 0 57476 5303 0 0
16% 0 0 0 1558 1 0 5884 26320 0 0 16s 96% 37% : 12% 0 1558 0 60216 8393 0 0
9% 0 0 0 1088 0 1 2344 0 0 0 16s 94% 0% - 6% 0 1074 0 27371 5529 0 0
65% 0 0 0 1643 1 0 19384 194184 0 0 14s 96% 95% Ff 70% 3 1640 0 290315 2789 0 0
61% 0 0 0 1052 0 1 22536 245736 0 0 6s 98% 100% Bn 79% 0 1052 0 255065 313 0 0
50% 0 0 0 490 1 1 16621 181924 0 0 6s 99% 100% Bn 70% 0 490 0 174667 143 0 0
62% 0 0 0 843 1 0 26105 305035 0 0 6s 98% 100% B0 80% 0 843 0 177126 1635 0 0
68% 0 0 0 1038 0 1 16042 301885 0 0 3s 97% 100% B0 72% 0 1025 0 267981 1044 0 0
62% 0 0 0 324 4 9 20706 297771 0 0 2s 98% 100% B0 77% 3 321 0 174467 440 0 0
64% 0 0 0 504 1 3 20889 305609 0 0 2s 98% 100% #f 81% 0 454 0 185060 181 0 0
75% 0 0 0 1700 1 2 40123 299639 0 0 2s 95% 100% Bf 81% 0 1606 0 240323 16613 0 0
72% 0 0 0 1534 1 0 33649 292647 0 0 2s 96% 100% Bs 87% 0 1530 0 275515 5618 0 0
73% 0 0 0 720 0 1 21492 312732 0 0 2s 98% 100% Bs 74% 0 687 0 238782 3230 0 0
68% 0 0 0 640 1 0 22592 299676 0 0 2s 98% 100% Bs 76% 3 624 0 88215 2041 0 0
CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s
in out read write read write age hit time ty util in out in out
51% 0 0 0 1126 0 1 19056 34468 0 0 3s 99% 34% : 73% 0 1110 0 81281 3587 0 0
8% 0 0 0 738 1 1 4568 8 0 0 3s 83% 0% - 8% 0 736 0 27035 5874 0 0
22% 0 0 0 1338 0 1 4050 5750 0 0 5s 91% 9% Fn 24% 0 1338 0 64754 5178 0 0
52% 0 0 0 1118 1 0 30473 215893 0 0 5s 99% 100% :f 78% 0 1118 0 56154 3918 0 0
16% 0 0 0 853 1 3 3800 104128 0 0 6s 94% 56% : 18% 5 846 0 51258 5479 0 0
17% 0 0 0 1389 1 1 1376 24 0 0 6s 94% 0% - 8% 0 1381 0 76174 4204 0 0
28% 0 0 0 1715 0 1 4095 5557 0 0 7s 96% 12% Fn 12% 0 1707 0 71517 4881 0 0
56% 0 0 0 1562 1 1 21544 184824 0 0 6s 98% 100% :f 77% 0 1562 0 100949 3676 0 0
17% 0 0 0 1218 1 8 8312 76140 0 0 6s 95% 100% :f 15% 0 1218 0 61772 5020 0 0
23% 0 0 0 2553 1 2 3780 47473 0 0 10s 97% 63% : 14% 351 2194 0 61903 10645 0 0
44% 0 0 0 1631 2 14 15616 120112 0 0 10s 98% 58% Ff 45% 0 1625 0 62638 4184 0 0
32% 0 0 0 1434 3 44 7644 77344 0 0 11s 98% 100% :f 31% 0 1434 0 76846 4952 0 0
27% 0 0 0 2007 1 37 5984 116332 0 0 11s 95% 93% : 24% 0 2007 0 101008 6113 0 0
46% 0 0 0 1459 2 4 15800 211828 0 0 9s 97% 67% Ff 38% 0 1459 0 70722 5889 0 0
23% 0 0 0 1436 0 1 5484 100020 0 0 10s 93% 69% : 19% 3 1433 0 91953 5532 0 0
10% 0 0 0 2076 1 0 2536 0 0 0 10s 98% 0% - 6% 0 2062 0 17902 5562 0 0
20% 0 0 0 1784 0 1 720 8 0 0 10s 97% 0% - 5% 0 1770 0 87513 5683 0 0
35% 0 0 0 1363 1 0 14829 155984 0 0 10s 94% 46% Fs 34% 0 1338 0 52878 3292 0 0
48% 0 0 0 2085 0 1 23420 112828 0 0 10s 99% 100% :f 68% 0 1974 0 51894 4388 0 0
18% 0 0 0 1279 1 1 2288 35296 0 0 10s 97% 47% : 11% 3 1230 0 60525 4345 0 0
STOMTSZRH022*> sysstat -M 1
ANY1+ ANY2+ ANY3+ ANY4+ AVG CPU0 CPU1 CPU2 CPU3 Network Protocol Cluster Storage Raid Target Kahuna WAFL_Ex(Kahu) WAFL_XClean SM_Exempt Cifs Exempt Intr Host Ops/s CP
61% 28% 16% 7% 29% 18% 20% 24% 53% 1% 0% 0% 8% 15% 6% 42% 28%( 13%) 2% 0% 0% 10% 2% 1% 1480 56%
28% 9% 3% 0% 12% 12% 11% 9% 18% 1% 0% 0% 3% 1% 7% 10% 17%( 11%) 0% 0% 0% 0% 2% 8% 1964 0%
67% 40% 23% 11% 36% 30% 31% 39% 43% 1% 0% 0% 8% 26% 7% 30% 33%( 16%) 9% 0% 0% 26% 2% 2% 1626 63%
40% 14% 4% 1% 16% 10% 12% 12% 28% 1% 0% 0% 5% 7% 5% 22% 14%( 9%) 1% 0% 0% 5% 2% 1% 1755 41%
25% 8% 2% 0% 9% 10% 7% 6% 15% 1% 0% 0% 2% 1% 6% 8% 17%( 11%) 0% 0% 0% 0% 2% 1% 1785 0%
71% 51% 33% 17% 45% 39% 40% 46% 53% 1% 0% 0% 9% 30% 9% 34% 49%( 24%) 10% 0% 0% 30% 2% 5% 1935 64%
9% 1% 0% 0% 3% 3% 4% 2% 3% 1% 0% 0% 2% 1% 2% 2% 3%( 2%) 0% 0% 0% 0% 1% 1% 657 0%
9% 1% 0% 0% 3% 4% 4% 2% 3% 1% 0% 0% 2% 1% 2% 2% 3%( 2%) 0% 0% 0% 0% 1% 1% 756 0%
15% 3% 1% 0% 5% 6% 6% 4% 6% 1% 0% 0% 3% 1% 4% 4% 6%( 5%) 0% 0% 0% 0% 2% 1% 1347 0%
17% 5% 1% 0% 6% 5% 7% 4% 9% 1% 0% 0% 2% 1% 4% 5% 10%( 7%) 0% 0% 0% 0% 1% 1% 1061 0%
19% 6% 2% 0% 7% 7% 6% 5% 11% 1% 0% 0% 2% 1% 4% 6% 12%( 7%) 0% 0% 0% 0% 2% 1% 1275 0%
78% 48% 26% 10% 41% 34% 29% 39% 62% 1% 0% 0% 9% 21% 10% 42% 52%( 23%) 9% 0% 0% 17% 2% 1% 2132 84%
83% 62% 47% 29% 56% 45% 49% 57% 72% 1% 0% 0% 10% 35% 12% 44% 77%( 29%) 8% 0% 0% 34% 2% 1% 962 100%
81% 63% 48% 28% 57% 50% 48% 61% 67% 1% 0% 0% 10% 40% 9% 43% 69%( 27%) 9% 0% 0% 38% 2% 6% 750 100%
79% 54% 40% 22% 50% 42% 39% 49% 69% 1% 0% 0% 10% 29% 9% 46% 65%( 24%) 5% 0% 0% 28% 2% 3% 920 100%
87% 61% 41% 21% 53% 42% 41% 54% 74% 1% 0% 0% 10% 33% 9% 51% 62%( 24%) 10% 0% 0% 33% 2% 1% 733 100%
84% 58% 42% 23% 52% 43% 40% 52% 74% 1% 0% 0% 11% 32% 10% 53% 59%( 22%) 8% 0% 0% 31% 2% 1% 851 100%
86% 60% 43% 18% 52% 43% 42% 52% 72% 1% 0% 0% 10% 31% 10% 49% 66%( 25%) 10% 0% 0% 29% 2% 1% 803 100%
86% 60% 44% 22% 54% 40% 43% 52% 79% 1% 0% 0% 9% 29% 11% 53% 72%( 27%) 7% 0% 0% 29% 2% 1% 978 100%
ANY1+ ANY2+ ANY3+ ANY4+ AVG CPU0 CPU1 CPU2 CPU3 Network Protocol Cluster Storage Raid Target Kahuna WAFL_Ex(Kahu) WAFL_XClean SM_Exempt Cifs Exempt Intr Host Ops/s CP
84% 49% 28% 13% 44% 29% 28% 41% 77% 1% 0% 0% 11% 33% 4% 71% 13%( 8%) 9% 0% 0% 31% 2% 1% 1311 74%
34% 7% 2% 0% 11% 7% 8% 8% 23% 1% 0% 0% 5% 5% 4% 21% 6%( 5%) 0% 0% 0% 2% 2% 1% 1554 0%
18% 4% 1% 0% 7% 8% 6% 4% 8% 1% 0% 0% 2% 1% 6% 5% 8%( 7%) 0% 0% 0% 0% 2% 1% 2088 0%
9% 1% 0% 0% 3% 4% 4% 2% 3% 1% 0% 0% 2% 1% 2% 2% 3%( 2%) 0% 0% 0% 0% 1% 1% 810 0%
9% 1% 0% 0% 3% 3% 4% 2% 3% 1% 0% 0% 2% 1% 1% 2% 3%( 2%) 0% 0% 0% 0% 1% 1% 491 0%
11% 2% 1% 0% 4% 4% 4% 3% 5% 1% 0% 0% 2% 1% 2% 3% 5%( 4%) 0% 0% 0% 0% 1% 1% 903 0%
9% 1% 0% 0% 3% 3% 4% 2% 3% 1% 0% 0% 2% 1% 1% 2% 2%( 2%) 0% 0% 0% 0% 1% 1% 401 0%
9% 1% 0% 0% 3% 3% 4% 3% 3% 1% 0% 0% 2% 1% 2% 2% 3%( 2%) 0% 0% 0% 0% 1% 1% 591 0%
12% 2% 0% 0% 4% 4% 4% 3% 5% 1% 0% 0% 2% 1% 2% 3% 4%( 4%) 0% 0% 0% 0% 1% 1% 768 0%
8% 1% 0% 0% 3% 3% 4% 2% 3% 1% 0% 0% 2% 1% 2% 2% 2%( 2%) 0% 0% 0% 0% 1% 1% 605 0%
29% 9% 3% 1% 11% 12% 9% 8% 14% 1% 0% 0% 4% 6% 2% 12% 3%( 3%) 9% 0% 0% 3% 2% 1% 771 23%
34% 12% 3% 1% 13% 13% 7% 11% 21% 1% 0% 0% 5% 7% 2% 16% 9%( 6%) 3% 0% 0% 7% 1% 1% 669 100%
17% 6% 1% 0% 7% 9% 6% 8% 5% 1% 0% 0% 3% 5% 2% 3% 4%( 3%) 0% 0% 0% 7% 1% 1% 557 100%
21% 7% 1% 0% 8% 10% 5% 8% 8% 1% 0% 0% 4% 5% 1% 7% 4%( 3%) 0% 0% 0% 7% 1% 1% 442 100%
10% 2% 1% 0% 4% 4% 3% 4% 4% 1% 0% 0% 2% 1% 2% 3% 4%( 3%) 0% 0% 0% 1% 1% 1% 819 9%
10% 3% 2% 1% 4% 4% 5% 4% 5% 1% 0% 0% 2% 1% 3% 2% 6%( 3%) 0% 0% 0% 0% 1% 1% 739 0%
96% 75% 54% 30% 64% 53% 55% 67% 81% 1% 0% 0% 10% 31% 21% 43% 109%( 42%) 11% 0% 0% 28% 2% 1% 1345 76%
84% 63% 47% 27% 56% 45% 50% 54% 74% 1% 0% 0% 10% 31% 17% 46% 78%( 29%) 7% 0% 0% 30% 2% 1% 937 100%
92% 69% 51% 27% 60% 49% 50% 59% 82% 1% 0% 0% 8% 32% 17% 54% 82%( 30%) 10% 0% 0% 34% 2% 1% 783 100%
86% 63% 47% 29% 57% 46% 48% 59% 74% 1% 0% 0% 11% 38% 12% 49% 66%( 26%) 10% 0% 0% 37% 2% 1% 754 100%
Thank you in advance regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hey,
Controller 1: disk util is 100%. Disk util shows the highes usage of a single disk in the systems. Means you can have an aggregate at 20% and another aggregate at 100% and it will always show you the most busy one, so 100%
Controller 2: CP time 100% a few times in a row. CP means consistency points, the netapp WAFL filesystems writes a "checkpoint" so to say every 10 seconds, each time a snapshot is done or as soon as the NVRAM write log is full. If you write too much it will sort of run from CP to next CP within seconds, we call that a back 2 back cp. Bigger NVRAM would help as disks are not 100%.
Conslusions: You might need more disks for your workload and maybe a bigger head for more write cache. There has been a KB article with optimizations for sequential i/o, couldnt find it that quick tho.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Thomas,
Yes I agree, controller 1 has a high disk utilization, for all of then, as you can see on a gathered with statit for this test case:
disk ut% xfers ureads--chain-usecs writes--chain-usecs cpreads-chain-usecs greads--chain-usecs gwrites-chain-usecs
/aggr1/plex0/rg0:
0b.04.11 5 7.88 0.13 1.00 1933 7.39 61.41 104 0.36 27.13 163 0.00 .... . 0.00 .... .
0b.04.10 5 8.05 0.13 1.00 1571 7.63 59.52 104 0.30 19.30 187 0.00 .... . 0.00 .... .
0b.04.9 93 252.71 243.50 6.34 3620 7.30 59.79 570 1.91 13.11 1336 0.00 .... . 0.00 .... .
0b.04.2 95 255.80 246.52 6.33 3924 7.20 60.58 606 2.07 11.90 1781 0.00 .... . 0.00 .... .
0b.04.0 94 255.33 245.91 6.32 3737 7.23 60.05 555 2.20 12.55 1391 0.00 .... . 0.00 .... .
0b.04.1 94 254.11 244.98 6.34 3715 7.20 60.78 576 1.93 12.66 1383 0.00 .... . 0.00 .... .
0b.04.3 94 255.51 246.00 6.32 3655 7.19 60.21 624 2.32 12.27 1562 0.00 .... . 0.00 .... .
0b.05.7 98 255.56 246.06 6.34 4414 7.22 60.17 616 2.28 11.96 2066 0.00 .... . 0.00 .... .
0b.04.5 94 255.76 246.36 6.45 3650 7.21 60.56 567 2.19 11.97 1545 0.00 .... . 0.00 .... .
0b.04.6 94 253.77 244.79 6.27 3797 7.19 60.90 601 1.78 13.79 1538 0.00 .... . 0.00 .... .
0b.04.7 93 253.91 244.85 6.32 3662 7.21 60.90 617 1.85 12.80 1398 0.00 .... . 0.00 .... .
0b.04.8 95 253.81 244.92 6.39 3756 7.20 61.16 592 1.69 12.87 1538 0.00 .... . 0.00 .... .
/aggr1/plex0/rg1:
3a.02.0 4 7.61 0.00 .... . 7.25 62.75 97 0.37 26.22 162 0.00 .... . 0.00 .... .
3a.02.1 5 7.71 0.00 .... . 7.35 61.87 100 0.36 25.28 172 0.00 .... . 0.00 .... .
3a.02.2 98 253.59 244.58 6.29 4462 7.19 60.79 659 1.82 13.42 1960 0.00 .... . 0.00 .... .
3a.02.3 97 248.70 240.12 6.39 4384 7.22 61.21 640 1.35 14.53 2195 0.00 .... . 0.00 .... .
0b.05.6 98 249.72 240.89 6.31 4486 7.20 60.93 646 1.62 13.98 2330 0.00 .... . 0.00 .... .
3a.02.5 98 254.41 245.70 6.35 4429 7.19 61.14 644 1.52 13.95 1894 0.00 .... . 0.00 .... .
3a.02.6 98 249.97 241.28 6.46 4354 7.21 61.49 650 1.48 12.67 1956 0.00 .... . 0.00 .... .
3a.02.7 97 250.32 241.39 6.40 4262 7.21 60.97 727 1.71 13.77 1780 0.00 .... . 0.00 .... .
3a.02.8 97 249.75 240.97 6.39 4377 7.23 60.99 634 1.55 14.85 1862 0.00 .... . 0.00 .... .
3a.02.9 98 250.72 241.94 6.31 4527 7.23 60.84 664 1.55 14.83 1783 0.00 .... . 0.00 .... .
3a.02.10 98 251.77 242.99 6.34 4396 7.21 61.04 665 1.57 13.27 1847 0.00 .... . 0.00 .... .
3a.02.11 98 251.95 243.33 6.33 4481 7.21 61.39 657 1.41 13.18 2192 0.00 .... . 0.00 .... .
Yes I agree, with your that with this values the solution could be to add more disks, but my question are:
- Why with a EMC storage (entry level) with 8 disks SAS 15k rpm and 1 Gbyte of write cache we can get a better latency executing this test than with a NetApp FAS3240 with 24 disks SAS 10k rpm and 8 Gbytes of write cache?
- If I am running the expdp process between 00:00-07:00 why the issue only happen when I export the database biggest tables as you can see on the
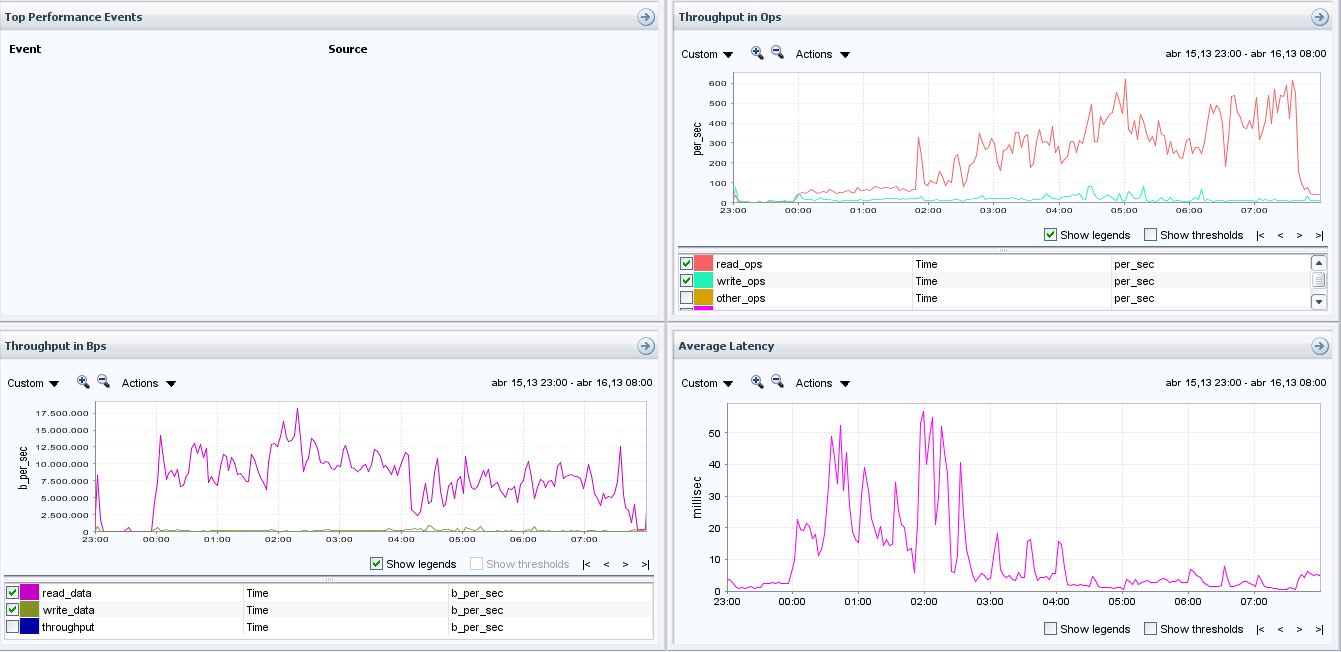
Could be a bug or is the expected behaviour?
Thank you in advance, regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
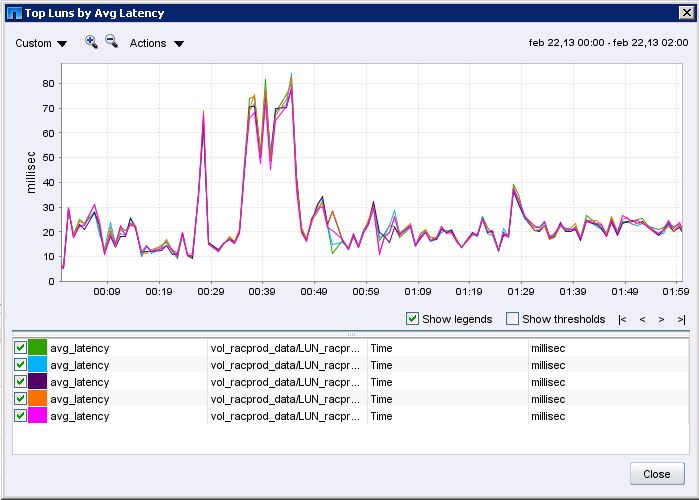
In this chart your latency drops around 3AM, but your throughput remains the same. I suspect there are other things running around midnight that are having an impact. Please open a case with NetApp Global Support to verify what is impacting your data pump process.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Erick,
Thank you about your feedback.
I think so, because is a ideal environment, an aggregate connected to a single machine dedicated to run a single database.
We have all ready open a case with NetApp Global Support and has been closed by himself with the following conclusion:
- To improve the performance of the Controller 1 increase the number of disk to support the load (with 24 disk (12+12) I can not reach the performance of my previous storage EMC with 8 disks)
- To improve the performance of the Controller review if I can migrate to Data Ontap 8.1.2 P3
Both operations are non rollback (in a easy way) and I do not know with improvement I could expect.
We have added two new disk to the Controller 1 and the improvement has ben more than 50%, please review the following post.
Because of that. my sensation is I do not have a mechanical issue (26 disk could not get a 50% improvement than 24 disk), is a Data Ontap bug or the expected behaviour.I have reviewed some forums in with some guys report an unstable performance behavior when you have raid groups lower than 16 disks but I can not found any graph or detailed test.
Any suggestion are welcome.
Thank you in advance, regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hey guys,
is it possible to post the AWR reports for both the EMC and NetApp environments? Possible to get a Perfstat posted as well? Last request - do the controllers send ASUP data? Would be nice to see a bit of the configuration about the controllers too...
Thanks
Greg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Igreg
Yes I can share with you the AWR and the perfstats, please let me know how can I do it, sorry I am new in this communities
To the last question, yes controllers send Autosuport data to NetApp.
Thank you about your feedback.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Going to ONTAP 8.0.5 could help, yes.
You usualy only have issues if the data is large sequential and does not fit into NVRAM (1GB per Head on a FAS3240). NetApp isnt a single thread optimized solution per Default but strong on multithread small random i/o.
Ever considered opening a performance case at netapp global support?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Thomas,
We have deployed 8.0.2P6 because was the recommended configuration for our environment do it by the partner who install the storage. I will review the compatibility matrix in order to review if my environment is compatible with this release.
Yes, I only have issues if the data is large sequential and does not fit into NVRAM, Please, could you explain to me with different there are between "Memory size " reported by sysconfig (8 Gbytes for FAS3240) and "NVMEM III size" reported by nv ( 1 Gbyte) because up to now I was thinking that I have 8 Gbytes of memory cache.
Yes we have already opened a performance case at netapp global support, it is opened since January, and the only solution offered up to know is to increase the number of disks because as you can see the disk utilization is 100%, but I can not got any explanation about the root causes of this behavior only in this scenario.
Thank you about your feedback, regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi there,
the FAS3240 has 8GB of RAM per controller for its operating System which includes kernel spaces, read cache and write cache. The filesystem transaction log will be written in a 1GB part of that 8GB of Memory which is battery power backed up in case of a sudden outage. So your system has 7GB of RAM to use (read/write cache size may then vary depending on configuration or current workload) but the filesystem transaction log will always be "stuck" at 1GB.
During sequential i/o this log will be filled quickly and needs a few disks to be flushed fast enough. A real life Performance experience for a FAS3240 with plenty of disks (about 42 15k disks) would be about 1000MByte read and about 400MBytes write (as seen by plenty of our customers).
Your first controller seems to suffer from too few spindles to give good read performance and the second Controller seems to suffer from too few spindes to properly flush the write cache back to back/too small cache.
If you have no FlashCache SSD read cache modules in your System, you might consider adding FlashPool SSDs as read/write cache to your System. But be sure that your average workload fits into the provided SSD cache space.
Good luck!
Thomas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Thomas,
Thank you very much four your help, you replays are very useful try to understand my problem.
Please, could you suggest me any document, book, what ever about the NetApp architecture, I could not find any reference to the "filesystem transaction log".
My second controller has 40 (18+2/18+2) 10k SAS disks, and appear to be not enough to support a database export datapump
I have SSD, but I can not create a FlashPool SSDs because Oracle asmlib do not work properly with the NetApp 8.1 release (see metalink alert 1500460.1) we are using like normal pool.
Yesterday we have added two new disk to my first controller (10+2/10+2) (one per raid group) and execute a reallocate force of the read volume source, and we have reduce latencies from 50ms to 30ms. NetApp recommend a raid groups of 16 disks I do not know why, please, could you suggest me any document to try to understand the improvement gathered with this change?.
Thank you in advance, regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hey,
in deepth explanations of how & why WAFL works are not publicly available, most of my knowledge comes from trying plenty of stuff myself and dealing with over 200 customers in the last 5 years 😉
In regards of aggregates and raid groups, you could give TR-3838 (Storage Subsystem Configuration Guide) as well as TR-3437 (Storage Best Practices) a try. Generaly speaking, the bigger an aggregate is, the better the performance. For sequential workloads bigger raid groups (22 disks+) are good due to more disks in one raid group and less parity calculation, for small random i/o smaller raid groups (16-20 disks) are ok for less read-ahead-for-parity calculation.
Your first controller possibly just needs more disks for the sequential i/o. Your second controller seems overwhelmed due to small write Cache. flashpool could help as it can flush the write cache faster than SAS disk. Besides engange netapp global Support on how to optimize a System for sequential i/o, they can increase read ahead sizes for example (vol options <volname> minra on/off, no_atime_update on/off and some aggregate settings).
Kind regards
Thomas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Thomas
Thanks a lot about your help.
I will review your suggested documents and I will be back as soon as I have completed some test on my environments.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
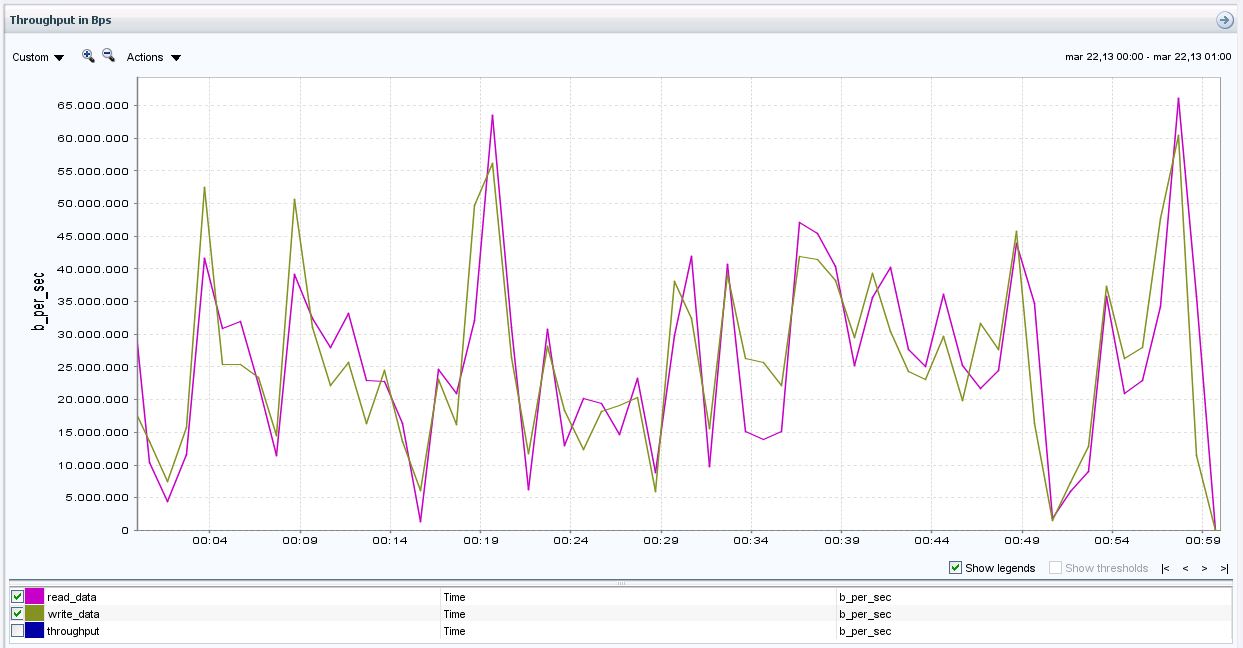
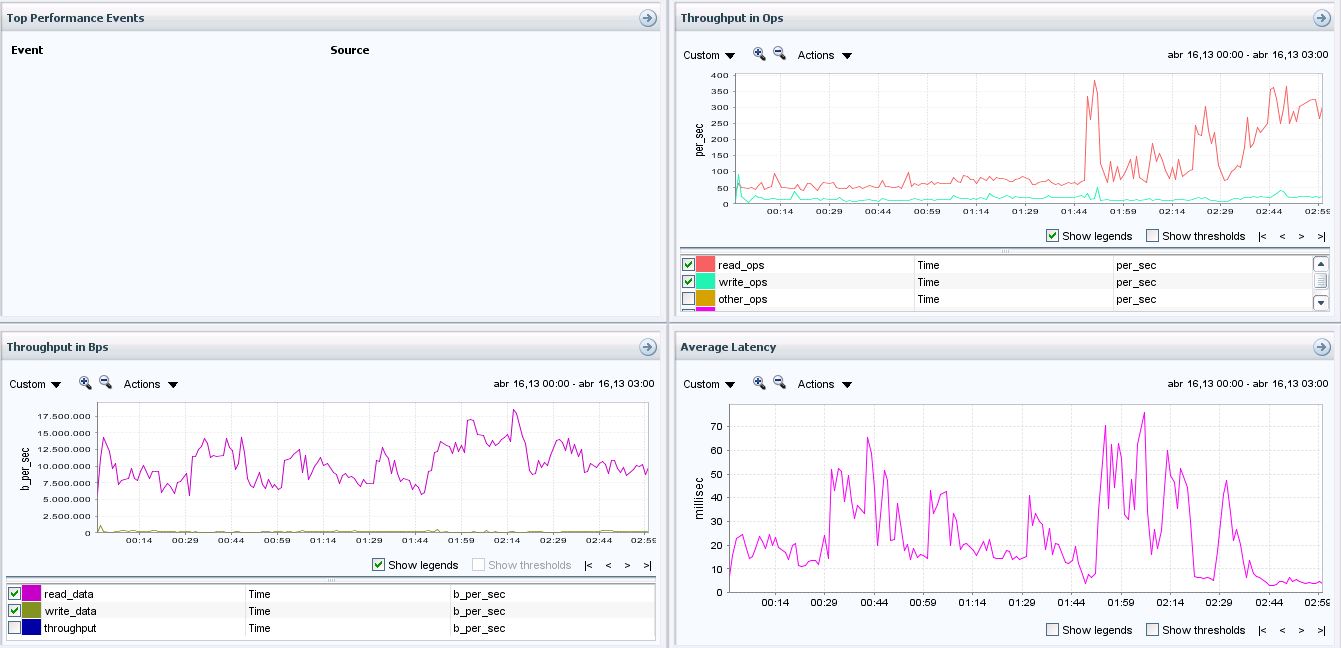
Hi,
On 17/04 we have added two new disk (same size and performance 600 Gbytes SAS 10k rpm) to the aggregate 1 (10+2/10+2) to increase the number of mechanical disk.
Once added the disk we forced a reallocated of the database data volume to spread the information for all the disk
After three business days we gather the same performance because of that I think that this values could be more or less stable:
Before the change:
After the change:
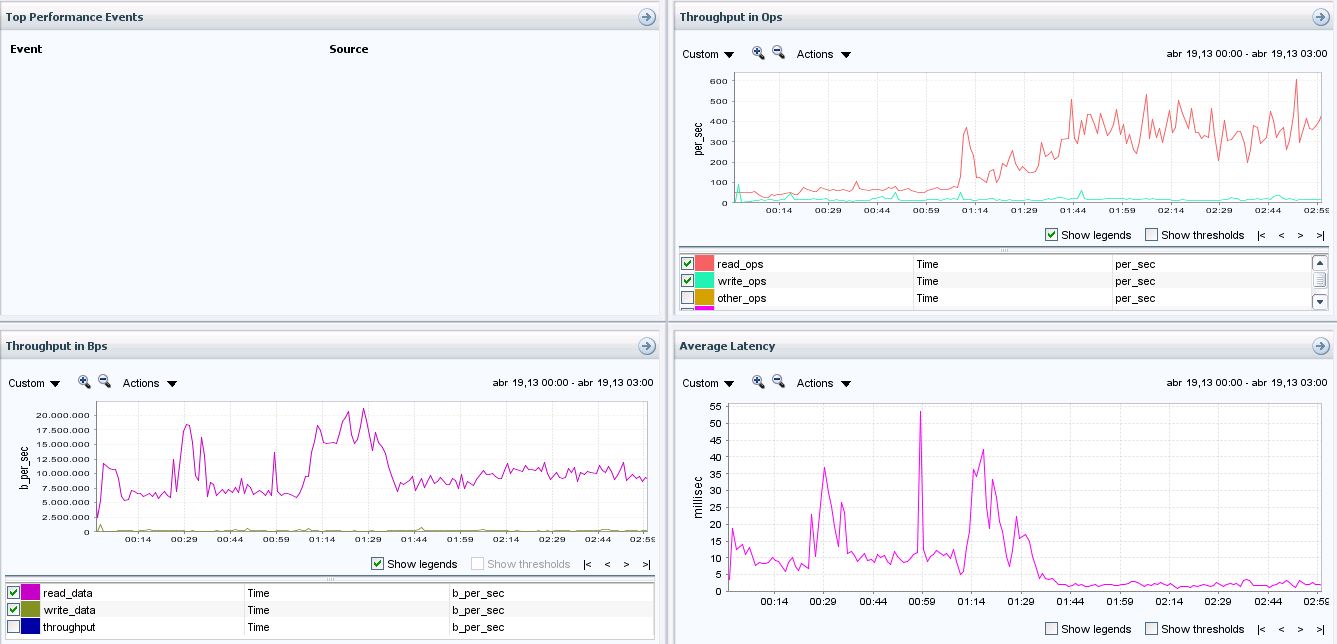
My conclusions are:
- We have reduce the latency peak from 70 ms to 40 ms and the overall amount of time with latencies bigger than 20 ms
- We have increase the throughput peak from 17,5 Mbps to 20 Mbps
- We have increased the IOPs peak from 400 to 500 ms
Now I am afraid, If I add more disk I will improve the performance or I will return to my previous scenario?
Any suggestions?
Thank you in advance, regards
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi.
We will be in a very similar situation like yours, as we have just adquired a 3220HA for main Datacenter and are in the migration path from an old HDS and a small EMC ( DB storage ) to the new NetApp. Also we are running daily datapumps at night, and our ASM config ( RAC, two nodes ) is built of small 100G volumes from the EMC... So, very similar indeed.
We will be subscribed to this case.Will provide feedback about our tests at the secondary DC ( FAS2240HA ) as soon as possible ( hope soon ).
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You may wish to double check the backup & AV schedule to see which processes are running around midnight.
Good luck
Henry
