If you did not get any Balance alerts, this means that even though there was a spike, there may not have been enough information to determine the cause.
1) Do you have Balance set up to send you emails alerts? If not, you can view past alerts and analysis on the top of the storage page, or on the Admin -> Events page.
If there is an event from the time you are interested in, please post the details.
If not, you can still see the details of which workloads where driving the storage at that time. Go to the Aggregate Summary Page; Performance Summary tab. This will have the details of the storage, and below it, which workloads are active for the time window you select at the top. It is important to monitor all the hosts and guests, this level of detail is necessary to uncover which workload is cause the problem.
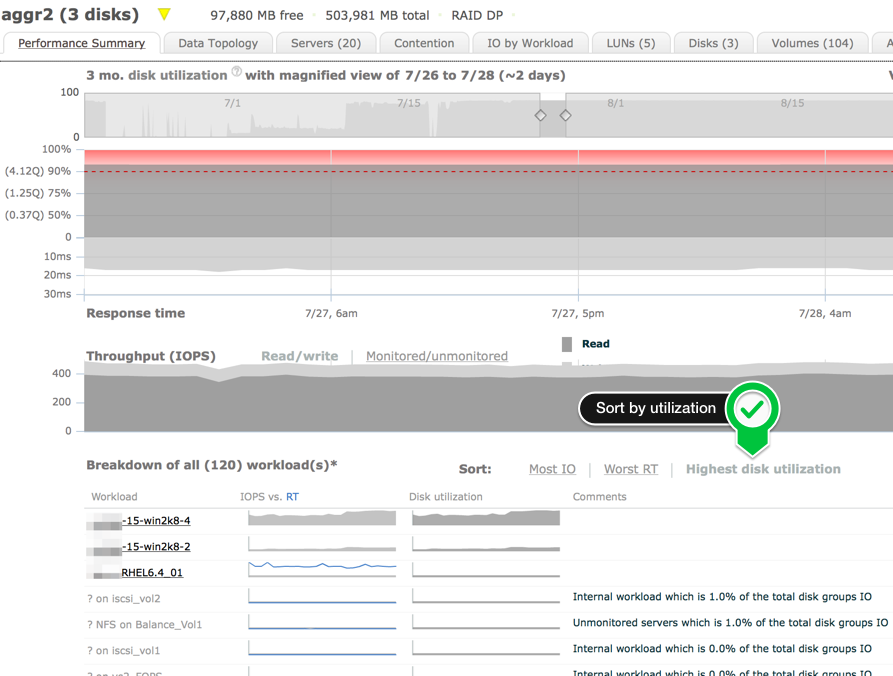
If this is not enough details, it may not have been due to a host workloads, but internal to the storage system, such as dedupe. If it was going on for several weeks, I wonder if dedupe can run that long...
