Stay connected during the transition - Join our Discord community today.
Active IQ Unified Manager Discussions
- Home
- :
- Active IQ and AutoSupport
- :
- Active IQ Unified Manager Discussions
- :
- Capacity report
Active IQ Unified Manager Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please tell me how to collect below information of a filer by using powershell.
Raw Capacity (GB)
Usable Capacity (GB)
Allocated Capacity (GB)
Unallocated Capacity (GB)
Unused Allocated Capacity (GB)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello @venkate_SAN,
This post has a great start for that information, hopefully you can add what's missing.
Hope that helps.
Andrew
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Depends on how many systems you are managing, how many different matrix and reports you have to run every day/week/month, there will be different ways to do that. If you only have a handful systems, just use the cmdlets (Get-NcAggr, Get-NcAggrSpace, Get-NcVol, etc.) and script them to put them together like recomemnded in the thread. If you have more systems and need to run the reports frequently, and unlucky enough , have to put them together with other storage platforms ( IBM,Tintri, PureStorage, etc.) for Capacity Report monthly, then you might want to think differently.
I ended up with this hard way since I have 70+ NetApp systems, and others platform as mentioned above.
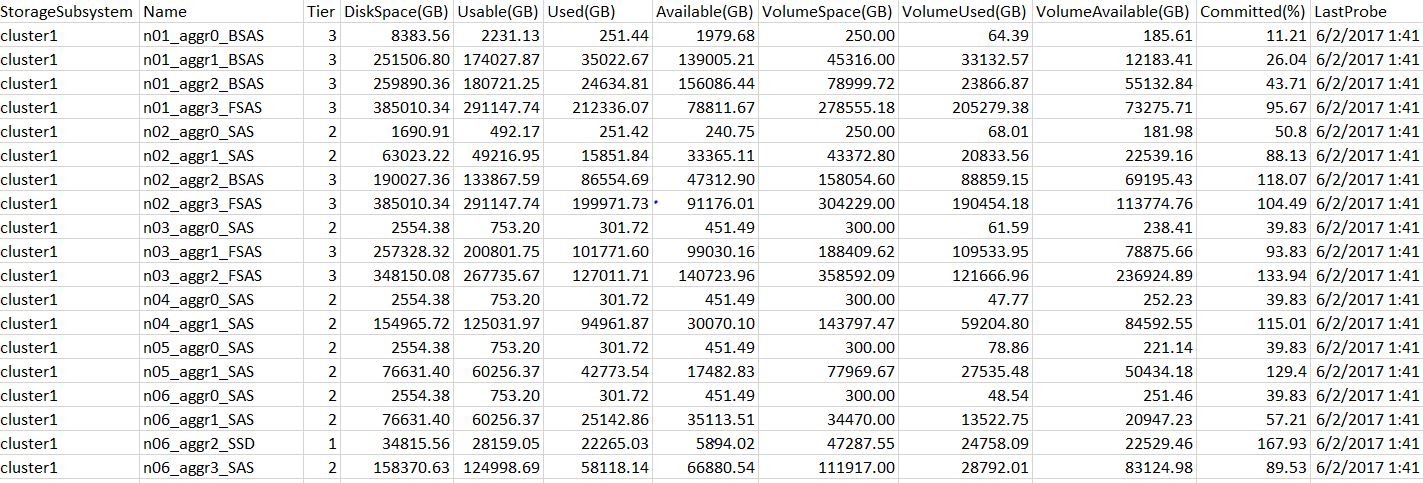
1. Use DataONTAP cmdlets to get all info for basic objects ( Aggr, Vol, LUN, etc.), output them into csv files
2. Import the csv files into an database ( MS SQL, MySQL, etc.) with tables pre-created based on cmdlet output preperty list
3. Create reports(database views) based on all of the info collected in step 1 in database, and optional publish them on Web GUI
4. Automate step 1-3 with cron jobs or task schedulers or SQL jobs, etc.
In this case, once you have aggr info and volume info, it will be just a join in database to get the Allocated info ( Total of VolumeSpace) per aggr or per controller or per facility, etc. Moreover, you will be able to get more and more reports based on queries and joins.( I have about 100 reports just for NetApp FAS/e-Series, and all are available in database anytime based on daily refresh for each system.) Attached is a sample capacity report for one cluster.
-Timothy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Venkate,
Have you considered that it would be much quicker to invoke a single SQL query in OCUM on the "ocum_report" database? OCUM periodically polls each cluster and invokes API's to query ONTAP then inserts the results (including the aggregate capacity information) into it's database. Hence it would be more efficent to query existing information once rather than connecting to each cluster using powershell to invoke API's against each cluster (which OCUM has already done). Here is an example query:
select distinct cluster.name as "Storage System", case when disk.interfaceType = "FCAL" then "FC/SAS" when disk.interfaceType = "SAS" then "FC/SAS" when disk.interfaceType = "BSAS" then "SATA" when disk.interfaceType = "ATA" then "SATA" when disk.interfaceType = "SSD" then "SSD" when disk.interfaceType = "FSAS" then "SATA" else disk.interfaceType end as `Storage Type`, aggregate.name as "Aggregate", aggregate.sizeTotal, aggregate.sizeUsed, aggregate.sizeAvail, aggregate.daysUntilFull from aggregate left join cluster on cluster.id = aggregate.clusterId left join diskaggregatemapping on diskaggregatemapping.aggregateId = aggregate.id left join disk on disk.id = diskaggregatemapping.diskId order by cluster.name, aggregate.name, `Storage Type`
Hope that helps.
/Matt
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
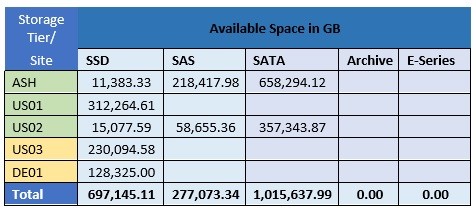
I need a report as attached.

we have 50+ filers, so i need report like this.
this report generated from oncommand report tool, is there any otherway to find the required details.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From the number of system you have, my guess is that you have both 7-mode and cDOT systems which makes things complicated. If you ONLY have cDOT, OCUM is the perfect place to to get the numbers you need. I just did a quick query and it works for me here, and I am pretty sure it can be optimized.
select cluster.name as "StorageSystem", d.`Raw Capacity(GB)`, cast(sum(a.sizeTotal/1024/1024/1024) as decimal(10,2)) as `Usable Capacity(GB)`, cast(sum(a.sizeUsed/1024/1024/1024) as decimal(10,2)) as `Used Capacity(GB)`, cast(sum(a.sizeAvail/1024/1024/1024) as decimal(10,2)) as `Unallocated Capacity(GB)`,v.`Allocated Capacity(GB)`,v.`Used Allocated Capacity(GB)`,v.`Unused Allocated Capacity(GB)` from aggregate a left join cluster on cluster.id = a.clusterId left Join ( select clusterid,cast(sum(totalbytes)/1024/1024/1024 as decimal(10,2)) as `Raw Capacity(GB)` from disk group by clusterid ) d on d.clusterid=a.clusterid left join ( select clusterid,cast(sum(size/1024/1024/1024) as decimal(10,2)) as `Allocated Capacity(GB)`,cast(sum(sizeused/1024/1024/1024) as decimal(10,2)) as `Used Allocated Capacity(GB)`,cast(sum(sizeavail/1024/1024/1024) as decimal(10,2)) as `Unused Allocated Capacity(GB)` from volume group by clusterid ) v on v.clusterid=a.clusterid group by a.clusterid order by cluster.name
So, bascially the Raw is the sum of all disk size which we paid for ;-), allocated is the sum of all volume sizes which we "sold" to customers, there are few columns not on your needed list though.
If you DO have 7-mode, probably need to put them together someway, but I am not quite fond of the old DFM/OM database so just pull data directly from Powershell from PSTK.
-Timothy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

{kind=link}
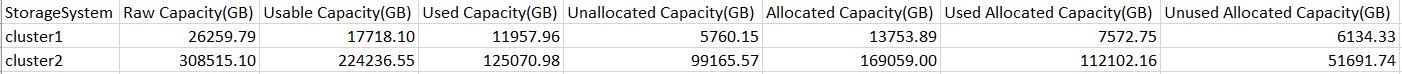{kind=link}
{kind=link}