This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
Active IQ Unified Manager Discussions
- Home
- :
- Active IQ and AutoSupport
- :
- Active IQ Unified Manager Discussions
- :
- Perf Capacity Used
Active IQ Unified Manager Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am continuously getting OCUM alerts for Perf. Capacity Used value of 212% on nodename1 has triggered a WARNING event based on threshold setting of 100%.
When I check the performance view I see things like 25K IOPs, ~500MB/s throughput and latency <1ms... so, in my opinion, nothing obviously grinding to a halt here.
The OCUM manual tries to explain what "Perf Capacity" is. But what is the community's take on these alerts and how best to address/resolve them in the real world? If this is a case of over-alerting I'd like to know that as well.
Thank you
Greg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Performance Capacity Used would get to levels where a warning is generated only if latency increase is observed at the node processing level. However, the increase in latency is a relative rather than an absolute measure. As a result, if this warning is a real concern for the environment depends on the workloads that are running. There are workloads that may be sensitive to such changes and there are workloads that may be not. Hence, a warning is generated as a precaution and the admin needs to make the final judgement.
There may be cases, when the latency increase is temporary, either due to a temporary load increase or temporary change in the workload demand. If this warning in persisting or occurs periodically then it should be taken into consideration, because it represents a proactive warning that cautions the user of performance issues if further load is added into the node.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Since we upgraded to CDOT I have been getting these errors. At least 5-10 each night. Imagine the weekends. I have logged tickets with support which have lasted weeks. According to all the perfstats they have collected there is no performance issue on the system whatsoever. We have FAS8060 AFF. Eventually a bug was created for me and this has not been fixed to date. I was advised that 7.2 should fix it. I am not able to install that version yet as we aren't on ESX 6+.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, Navman,
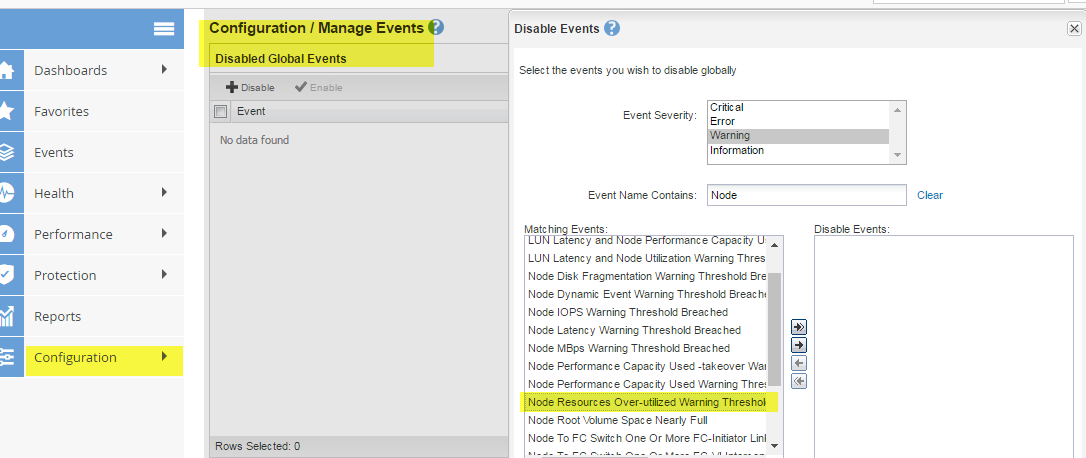
If you are sure there is are no performance issues with the system and you would rather not receive this alert, you can disable this particular alert.
The events would still be generated in the system, but you will not be receiving the alerts.
Here are the steps:
Configuration\Manage Events\Disable
See attached screenshot for details.
Julia
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Julia.
Must be a new setting in 7.2/7.3. This option was not available in 7.1. What version are you using?
Regards
Naveed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, Naveed,
Yes, this feature is only available in UM 7.2 or 7.3. Please consider upgrading or installing the newer build at your earliest convenience.
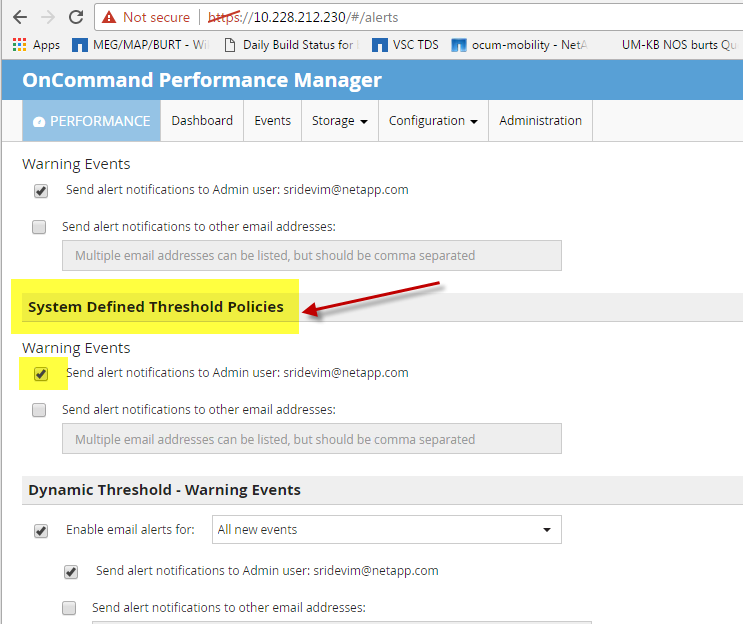
I'm assuming you are running OCUM 7.1 connected to OPM. There is a way not to receive this event, but in a more complex way.
Go to Performance\Configuration\Configuration\Event Handling\System Defined Threshold Policies, and uncheck the Email alert box.
This will stop this event from being "published" and sent through email.
The caveat is it will also stop the aggregate utilization system-defined event from being sent as well.
See attached screenshot for details.
Julia
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Julia
I upgraded to 7.3. The alerts have stopped coming through without me having to change anything which is great. I think it is still interesting though that the Perf. Capacity Used is still showing as quite high, sometimes up to 200%. When I logged tickets for this previously, I was advised there was no performance issue from the perfstat which was collected. Quite a confusing counter then really.
Naveed

{kind=link}
{kind=link}