Active IQ Unified Manager Discussions
- Home
- :
- Active IQ and AutoSupport
- :
- Active IQ Unified Manager Discussions
- :
- Selecting an Aggregate based on Least Used %
Active IQ Unified Manager Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I have a workflow for creating a cMode snapmirror relationship. The problem I have is that the workflow keeps selecting the same destination aggregate. I want it to select the destination aggregate based on least used percentage. Here is the code for the filter:
SELECT
aggr.name,
(((aggr.used_size_mb + '${used_space}')/ aggr.size_mb) * 100) AS used_percentage,
node.name AS 'node.name',
cluster.primary_address AS 'node.cluster.primary_address'
FROM
cm_storage.aggregate AS aggr
JOIN
cm_storage.node AS node
ON aggr.node_id = node.id
JOIN
cm_storage.cluster AS cluster
ON cluster.id = node.cluster_id
WHERE
(
(
aggr.used_size_mb + '${used_space}'
) / aggr.size_mb
) * 100 <= '${used_size_threshold}'
ORDER BY
used_percentage
Now, when I test this, it does in fact order the aggregates from least to greatest usage, but it keeps selecting the same one, eventhough that aggregate is not even close to being the least used. Any suggestions would be great.
-todd
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is a built-in finder in WFA 2.1 called "Find aggregate for SnapMirror destination volume". Perhaps, that might help when you are designing your own selection algorithm for the destination aggr. Take a look at "Returned attributes" tab. That is where you can select the ordering criteria. That finder has the following criteria (but you can select different columns and reorder them as per your needs):
1. Fault domain separation: Aggregate on a different node than the the specified node usually of the source aggreate.
2. Load balancing across the nodes of the cluster: Aggregate on a node with the least number of volumes.
3. Capacity balancing: Aggregate with the most free space.
neelesh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Does not work. It will list the aggregates like I want (from least used to most used), but when it chooses the aggregate, it seems to be doing so alphabetically. I can't find the code/logic that selects the aggregate.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Are you using a finder that uses your filter? Did you select the column used_percentage at top in the "Returned attributes" tab of the *finder*? See the screenshots below of a finder that I created using your filter query.

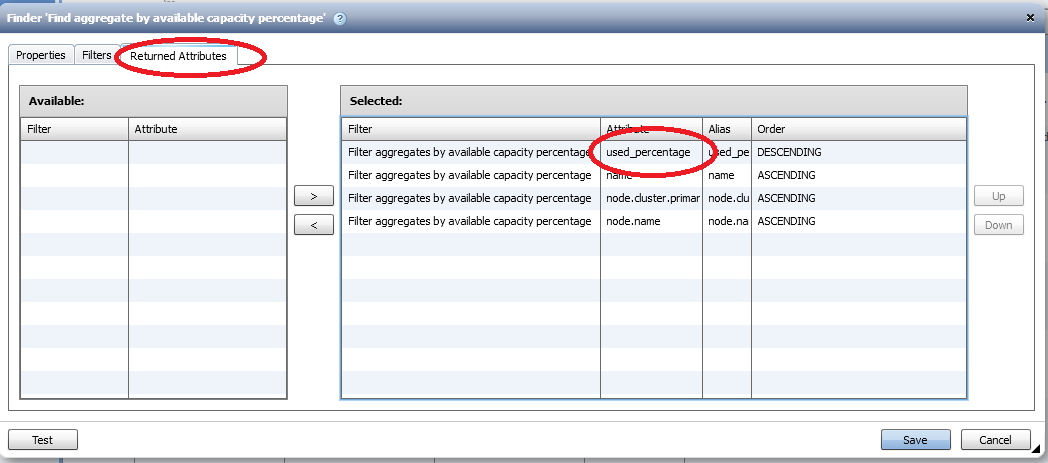
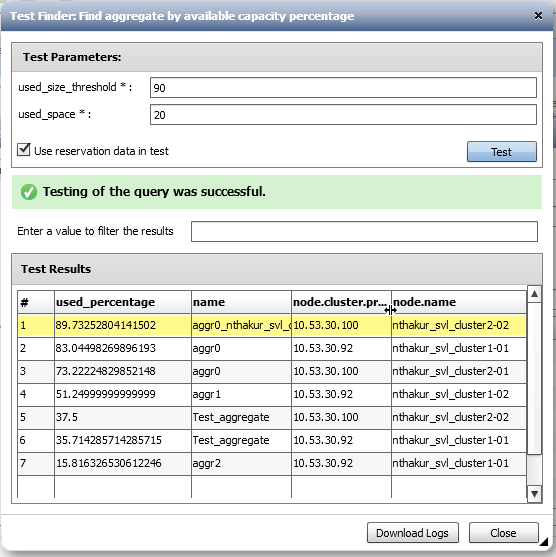
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is what I have set up:
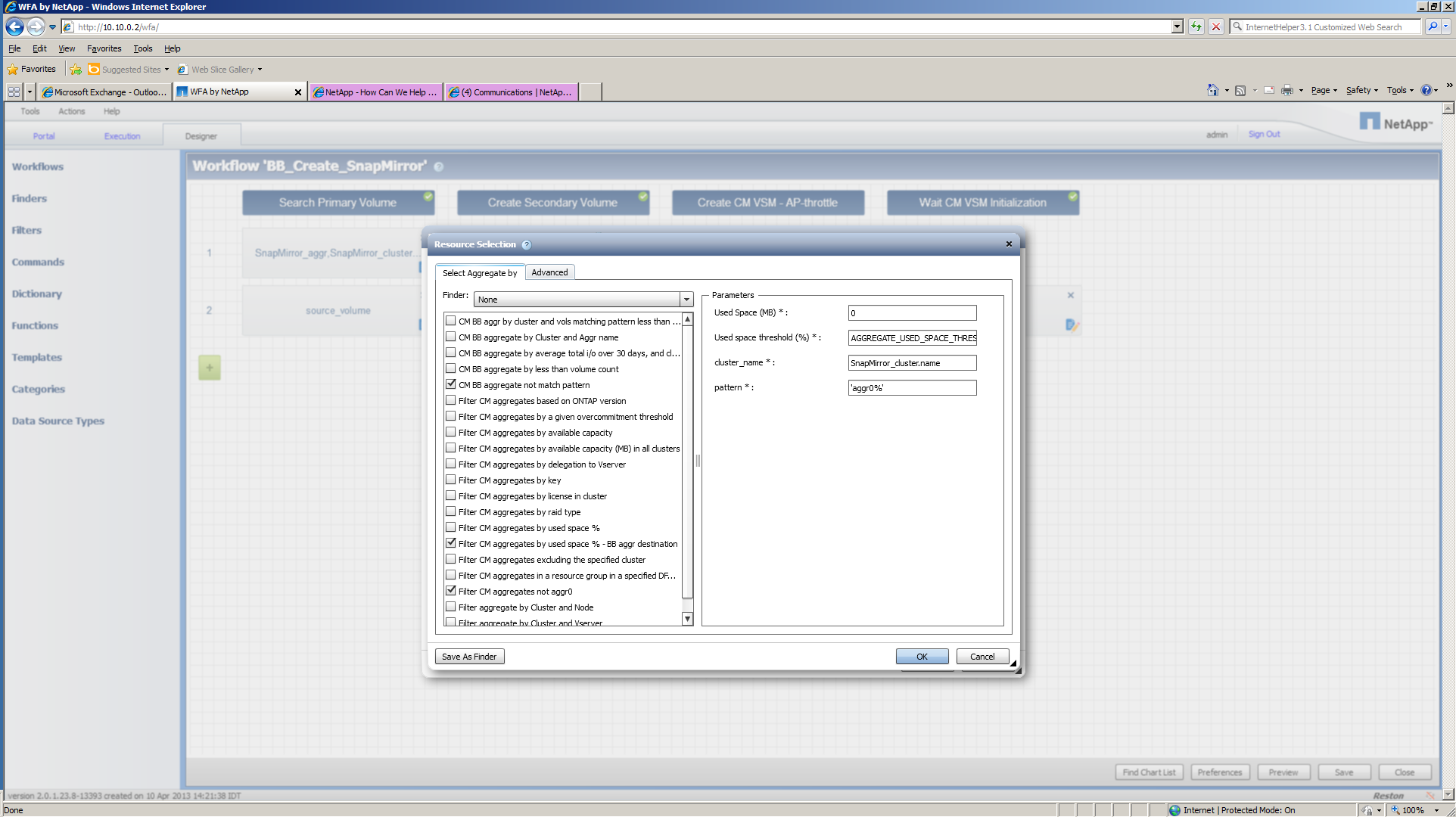
It looks as if I'm not using a Finder, but the Filter here seems to be doing the same thing. In fact, if I test this it works like I want:


But when I test the work flow, it never selects the lest used aggregate.
I'm just learning all this stuff, so forgive my ignorance of how these Filters and Finders work together.
Thanks for your help.
-todd
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try creating a named finder with all the filters that you have selected in the first screenshot. Then, use "Returned Attributes" tab of the *finder* to specify the selection order as I have shown in my screenshot.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm running 2.0, but I think I created the equivalent, but it still does not work. The finder per se works, in that it will pull the aggregates that are not aggr0 and will order them ascending, but it will not select based on that order:





- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Note that your sorting order is Ascending and not Descending as Neelesh example shows....
Yaron
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It makes no difference. It is still choosing an aggregate that is neither the lest used, nor the most used.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm curious if you've acquired the most recent information from Unified Manager for the systems you're interested in? I know sometimes I set my acquisition schedule to '0' (i.e. manual acquisition), if I'm testing a lot of things... Do you know if WFA has all of the current information for the aggregates it "sees"?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yup. It updates every 5 min and this has been a problem for months.
