This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
Active IQ Unified Manager Discussions
- Home
- :
- Active IQ and AutoSupport
- :
- Active IQ Unified Manager Discussions
- :
- netapp-harvest - WAFL Write Pending
Active IQ Unified Manager Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
First of all... Awesome work with Netapp-Harvest \ Graphite \ Grafana! I am really enjoying this tool.
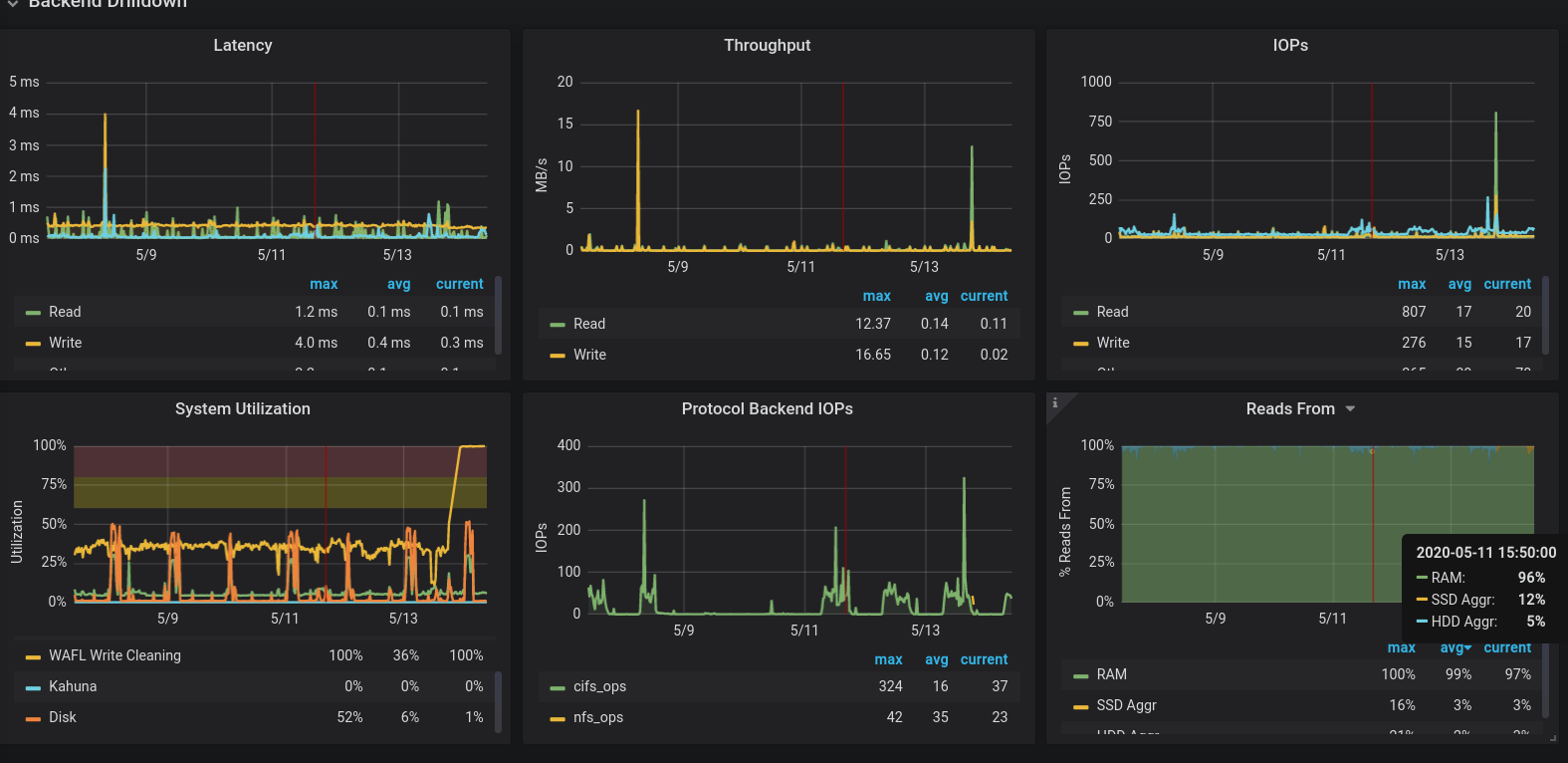
We recently had an incident where our 7-mode FAS6210 was getting heavy read latency. Ultimately we ended up executing a cluster takeover\giveback to get us out of the situation. Later we started looking at the data to see if we could determine which metrics could have been an indicator of the issue. We came across the below metric that lined up perfectly with the timing of our issue. We tried to get some additional information on what this metric was actually gathering by opening a case with Netapp. At first the support engineer stated that there was no such metic called "WAFL Write Pending". We later figured out the acutal metic was cp_phase_times\P2_FLUSH, just being aliased as "WAFL Write Pending".
The Netapp API documentation states P2_FLUSH is time taken for CP phase2 flush stage in msecs per vol.
It appears that some math and aliasing is being executed on this metric based on how I see the metric configured in Grafana (See screen shot below).
I am curious of the thought process of converting the raw data from msesc to a percentage for display in Grafana?
We would like to understand the root cause of why this metric spiked. Are there other metrics of interest to look at when "WAFL Write Pending" spikes?


Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Glad you like the monitoring stack!
This write cleaning metric is related to how Data ONTAP (DOT) persists data written by clients in a consistency point (CP). A CP actually has many phases. I simplify it into two: write cleaning and flushing to disk. So flushing is actually writing out to disk and cleaning (or maybe nicer to call it ‘write allocation’) is anything else including metadata reads needed to write data, building tetrises around fragmented freespace, etc. By design DOT will flush in a lazy way to avoid spikes of IO on the disks and only if DOT is under write pressure will it instead flush as fast as possible. So typically cleaning is the minority time, and flushing the majority.
If cleaning becomes the majority then something isn’t healthy. Maybe it’s freespace fragmentation, maybe readahead wasn’t able to prefetch required metadata or data needed to process partial IOs in time, maybe a bug caused no prefetch to occur, maybe lots of data was deleted on a full volume and it is reclaiming freespace in an aggressive mode, or more things. So this is why I show it as a sign of health of writes.
The only wrinkle I heard from another customer was he saw that during a heavy write workload on AFF the graph also went high. My guess (since I don’t have an AFF to test with) is that because the flush phase to SSD is so fast that the majority time ends up being cleaning. So this caveat should apply if interpreting the graph on AFF.
Did you have a heavy write workload during this incident? Did you delete any large snapshots or large files on full volumes while heavy writes were occurring (check your disk used graphs)? These are some ideas for you to research to try and get to the root cause. A perfstat also contains much more diagnostic info and could pinpoint root cause in case you have one (or so that if it happens again you can collect one).
Cheers,
Chris Madden
Storage Architect, NetApp EMEA (and author of Harvest)
Blog: It all begins with data
If this post resolved your issue, please help others by selecting ACCEPT AS SOLUTION or adding a KUDO
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Glad you like the monitoring stack!
This write cleaning metric is related to how Data ONTAP (DOT) persists data written by clients in a consistency point (CP). A CP actually has many phases. I simplify it into two: write cleaning and flushing to disk. So flushing is actually writing out to disk and cleaning (or maybe nicer to call it ‘write allocation’) is anything else including metadata reads needed to write data, building tetrises around fragmented freespace, etc. By design DOT will flush in a lazy way to avoid spikes of IO on the disks and only if DOT is under write pressure will it instead flush as fast as possible. So typically cleaning is the minority time, and flushing the majority.
If cleaning becomes the majority then something isn’t healthy. Maybe it’s freespace fragmentation, maybe readahead wasn’t able to prefetch required metadata or data needed to process partial IOs in time, maybe a bug caused no prefetch to occur, maybe lots of data was deleted on a full volume and it is reclaiming freespace in an aggressive mode, or more things. So this is why I show it as a sign of health of writes.
The only wrinkle I heard from another customer was he saw that during a heavy write workload on AFF the graph also went high. My guess (since I don’t have an AFF to test with) is that because the flush phase to SSD is so fast that the majority time ends up being cleaning. So this caveat should apply if interpreting the graph on AFF.
Did you have a heavy write workload during this incident? Did you delete any large snapshots or large files on full volumes while heavy writes were occurring (check your disk used graphs)? These are some ideas for you to research to try and get to the root cause. A perfstat also contains much more diagnostic info and could pinpoint root cause in case you have one (or so that if it happens again you can collect one).
Cheers,
Chris Madden
Storage Architect, NetApp EMEA (and author of Harvest)
Blog: It all begins with data
If this post resolved your issue, please help others by selecting ACCEPT AS SOLUTION or adding a KUDO
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your great explanation.
I see heavy Wafl Write Cleaning after upgrading Ontap (we went from 9.3 over 9.5 to 9.6) and had a high spike (100% for several hours). I dont know if this has a negative effect on our system besides being graphed in grafana. Latency,.. seems fine. The system is under no heavy load, though. Attached is the time days before the upgrade to see the difference.

{kind=link}