This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: Could I create a data volume on CFO HA policy aggr
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see a document,There is a saying that I can not understand,"However, data volumes in CFO aggregates are given back together with the root volume immediately."
But when I create vserver, operating system does not allow data vol specifies on node's root aggr。
I have two questions, first, whether aggr with CFO HA policy is only node's root aggr,And it can not create data vol。
The second problem is , since on c-mode HA pairs, root aggr is CFO HA policy,When controller failover, whether on a surviving node will still be bringing up the failed node virtual instance
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes.
cluster1::> storage aggregate modify -aggregate [aggregate] -ha-policy [cfo|sfo]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Answer 1 - By default, clustered ONTAP creates data aggregates with 'ha-policy' of SFO. Typically, data aggregates have 'ha-policy' of CFO when they contain the Target volume that is being transitioned from 7-Mode to clustered ONTAP. The fact that you cannot create a data volume in the node root aggregate is partly related to the fact that NetApp does not recommend putting user data on the root aggregate and partly related to the failover times for aggregates with 'ha-policy' of CFO that also contain user data.
Answer 2 - The node failover behaviour in clustered ONTAP is different when compared to the failover in 7-Mode. In clustered ONTAP we do not bring up a virtual instance of the failed node. The surviving node takes ownership of the disks from the failed node. This can be verified by running the 'storage aggregate show' command and looking at the 'nodes' column of the command output.
In general....
CFO (Controller FailOver) is how ONTAP handles resiliency between controllers that run Data ONTAP 7G or Data ONTAP 8 7-Mode. This failover behaviour is also used for the node root aggregate on nodes running clustered ONTAP. However for the purpose of explaining CFO we will focus on 7G / 7-Mode HA pairs.
When one of the two nodes in a 7G / 7-Mode HA pair is unexpectedly unavailable the partner node picks up the function of serving data that was hosted on the failed node. In order to serve data the surviving node brings up a virtual instance of the failed node in its memory and mimics its configuration to clients looking to access data belonging to the failed node. For a giveback event to occur the surviving node checks for a message from the partner node that it is waiting for giveback. When such a message is detected, the surviving node hands back control of all data serving functions to its partner. Once the partner indicates that the giveback has been successful the surviving node removes the virtual instance of the partner from its memory. If the giveback fails for any reason the surviving node continue to host the virtual instance of its partner.
SFO (Storage FailOver) is how clustered ONTAP (also known as Data ONTAP 8 Cluster-Mode) handles resilient failover of aggregate containing user data between HA pairs of controllers. Unlike 7G / 7-Mode the failover mechanism of network resources is outside the scope of SFO. One of the reasons takeover is more efficient in clustered ONTAP is because RAID on the HA partner makes a RPC call to the VLDB to update the location of the CFO and SFO HA policy aggregates. This allows access to the volumes on these aggregates from the Nblade. In effect, the HA partner takes ownership of the partners disks, whereas in 7-Mode the partner brings up a virtual instance of the failed node.
When performing a giveback in clustered ONTAP, aggregates are given back sequentially. First all CFO aggregates are given back. With the root volume back online (stored in a CFO root aggregate), the node given back will synchronize its cluster database and make sure all its settings are correct, so that it can serve data correctly before SFO aggregates are returned. During this time, all the volumes in the SFO aggregates are still served out by the partner. One by one, the partial giveback (where some aggregates are given back and some are not) becomes a full giveback as SFO aggregates return one by one.
However, data volumes in CFO aggregates are given back together with the root volume immediately. As long as it takes for the recovering node to be fully healthy and ready to serve data, (starting the RDB applications, synchronizing the cluster database, etc) these volumes in CFO aggregates are not available for NAS clients; the node giving back has released them, and the recovering node is not able to serve NAS data until all its cluster-related data is fully verified and up to date. This process of volume downtime can take a number of minutes, making a giveback a highly disruptive process for the volumes stored in CFO aggregates. This is why you see below warning when switching an aggregate with data volumes to CFO:
Warning: Setting ha_policy to cfo will substantially
increase the client outage during giveback for volumes
on aggregate 'aggr1_cm3240c_rtp_01'. Do you still want
to continue? {y|n}:
Or why you see below waring when adding data volumes to the root aggregate:
Warning: You are about to create a volume on a root
- aggregate. This may cause severe performance or
stability problems and therefore is not recommended.
Do you want to proceed? {y|n}:
The RAID / sanown operations themselves are probably similar in speed for CFO and SFO aggregates, but the time until data access is restored for hosted volumes differs substantially based on the policy.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Typically, data aggregates have 'ha-policy' of CFO when they contain the Target volume that is being transitioned from 7-Mode to clustered ONTAP.
Colud I change 'ha-policy' of CFO aggr to 'ha-policy' of SFO aggr
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes.
cluster1::> storage aggregate modify -aggregate [aggregate] -ha-policy [cfo|sfo]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for this...there is a lot of confusion in the field and many describe a virtual instance similar to 7-mode. This clearly and succinctly explains the difference in clustered ontap.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
However, I tested 2 node cluster, when one node "storage failover takeover" another node,
I entered nodeshell,I found still can use "partner" command shift to failure node's shell,
But said in the document, on clustered ONTAP, if a takeover occurs, the node is gone, there is no virtual instance live on.
How to explain can still enter the failure node's shell?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I am confused. Can you explain what you are looking to achieve by using these commands on the nodeshell? All the necessary actions and commands options to handle a failover scenario are available on the clustershell.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
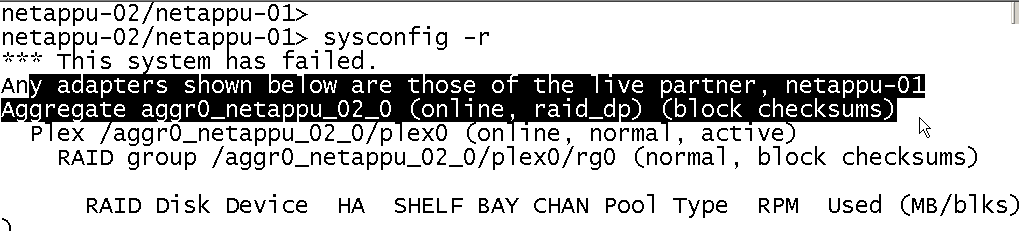
I have uploded a picture to community.I'm confused now.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please do not use the 'partner' command on the nodeshell of a clustered ONTAP system. It will yield unexpected results.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Mrinal,
Do you have an idea on how much time(as you said, no. of minutes) does it take to restart the RDB and syncronizing/updating the DB across?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This varies depending on the size of the cluster and the size of RDB. Generally this takes less than a couple of minutes, provided all is well in the cluster.

{kind=link}