ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: Snapvault Snapshot network throughput
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
we have a pair of FAS3040 filers (Ontap 8.0.1). One for the data and one for the snapshots. Each of two has 4x GbE interaces which are connected to a Cisco switch in a Port Channel. The filers are located in different datacenters which are connected by 10 GbE. I don't know the exact network topology but according to the network support team there is no network performance bottleneck (they checked the stats and graphs).
What I see during the transfer of a snapshot to the backup filer is a throughput of ~30 MB/s. I've seen CIFS traffic to and from the data filer with >50 MB/s. The cpu load is ø 30%.
Any ideas what to check?
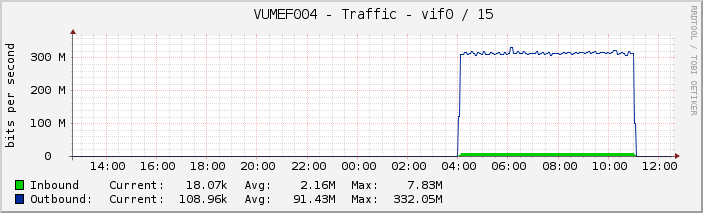
VUMEF004 is the primary system (source)
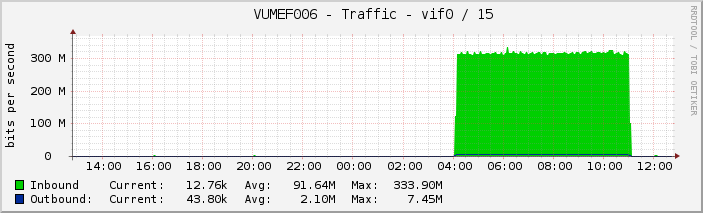
VUMEF006 the backup system (destination)
VUMEF004> ifgrp status
default: transmit 'IP Load balancing', Ifgrp Type 'multi_mode', fail 'log'
vif0: 4 links, transmit 'IP Load balancing', Ifgrp Type 'multi_mode' fail 'default'
Ifgrp Status Up Addr_set
up:
e4b: state up, since 16Dec2010 16:49:58 (35+19:54:38)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 617954924, input bytes 201018021022
output packets 18661492, output bytes 1548164538
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 16Dec2010 16:49:58
consecutive 3095447, transitions 1
e4a: state up, since 16Dec2010 16:49:58 (35+19:54:38)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 31327899, input bytes 3541567215
output packets 1003817786, output bytes 1498665173524
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 16Dec2010 16:49:58
consecutive 3095447, transitions 1
e3b: state up, since 16Dec2010 16:49:58 (35+19:54:38)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 6763888, input bytes 709795867
output packets 47740311, output bytes 3829076142
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 16Dec2010 16:49:58
consecutive 3095447, transitions 1
e3a: state up, since 16Dec2010 16:49:58 (35+19:54:38)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 7380650, input bytes 614070676
output packets 5273889, output bytes 7586525498
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 16Dec2010 16:49:58
consecutive 3095447, transitions 1
VUMEF006> ifgrp status
default: transmit 'IP Load balancing', Ifgrp Type 'multi_mode', fail 'log'
vif0: 4 links, transmit 'IP Load balancing', Ifgrp Type 'multi_mode' fail 'default'
Ifgrp Status Up Addr_set
up:
e4b: state up, since 06Jan2011 16:48:56 (14+19:56:40)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 668826329, input bytes 1013962060137
output packets 5048868, output bytes 590464021
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 06Jan2011 16:48:56
consecutive 1281303, transitions 1
e4a: state up, since 06Jan2011 16:48:56 (14+19:56:40)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 2031316, input bytes 133486263
output packets 60777, output bytes 5758807
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 06Jan2011 16:48:56
consecutive 1281303, transitions 1
e3b: state up, since 06Jan2011 16:48:56 (14+19:56:40)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 16087423, input bytes 1783457403
output packets 224969, output bytes 16381402
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 06Jan2011 16:48:56
consecutive 1281303, transitions 1
e3a: state up, since 06Jan2011 16:48:56 (14+19:56:40)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 2303947, input bytes 769575573
output packets 352882441, output bytes 32534561175
up indications 1, broken indications 0
drops (if) 0, drops (link) 0
indication: up at 06Jan2011 16:48:56
consecutive 1281303, transitions 1
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is the aggregate full more than 85% full can be a bad place to be for performance.
The command sysstat -x will tell you what is happening in your system. Is anything maxed out?
You can use the statit command to see what the disks are doing, are they maxed out, any hot spots.
you could use the pktt start / stop command to create a packet trace on both filers. Use wireshark or another tool to see what is happening to your packets. TCP windowing issue, MTU problem, retransmits due to inline compression on the WAN?
Hope it helps
Bren
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
the 2 filers are FAS3140 not 3040, I'm always mixing it up. Right now there is inbound traffic to the data server, the Windows client that is writing to the share is connected by a different interface. Additionally I triggered a snapvault to run now. It's the same max. throughput it was this night (30-40 MB/s).
The attached graph shows that the throughput seems to hit some limit, the max. throughput shows only a few % difference over the running time. I can't see much of a performance problem in the sysstat output.
snapvault source
CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s
in out read write read write age hit time ty util in out in out
21% 0 544 0 547 35962 38127 33124 340 0 0 6s 40% 11% : 10% 3 0 0 0 0 0 0
33% 0 478 0 478 31794 38770 36564 53252 0 0 4s 78% 52% Ff 18% 0 0 0 0 0 0 0
29% 0 518 0 518 34271 39376 40112 60880 0 0 6s 78% 100% :f 20% 0 0 0 0 0 0 0
24% 0 498 0 498 33063 39318 45412 18284 0 0 24 57% 42% : 14% 0 0 0 0 0 0 0
20% 0 548 0 548 36234 38758 30856 0 0 0 24 32% 0% - 8% 0 0 0 0 0 0 0
37% 0 498 0 503 33023 39269 41329 57277 0 0 24 76% 85% Ff 18% 5 0 0 0 0 0 0
28% 0 494 0 494 32792 39539 35468 57084 0 0 4s 77% 100% :f 15% 0 0 0 0 0 0 0
23% 0 522 0 522 34603 40132 35548 18608 0 0 24 56% 43% : 15% 0 0 0 0 0 0 0
30% 0 478 0 478 31638 39340 43476 18976 0 0 5s 62% 20% Ff 13% 0 0 0 0 0 0 0
30% 0 535 0 535 35432 39820 40060 61767 0 0 5s 81% 100% :f 19% 0 0 0 0 0 0 0
29% 0 534 0 537 35431 42297 37572 51476 0 0 24 79% 96% : 17% 3 0 0 0 0 0 0
21% 0 546 0 546 36174 41229 35872 24 0 0 24 39% 0% - 8% 0 0 0 0 0 0 0
39% 0 492 0 556 32603 37453 33676 57352 0 0 4s 82% 62% Ff 18% 64 0 0 0 0 0 0
31% 0 518 0 518 34351 38045 42376 61324 0 0 4s 75% 100% :f 19% 0 0 0 0 0 0 0
23% 0 545 0 545 35997 36496 38548 13780 0 0 4s 59% 34% : 10% 0 0 0 0 0 0 0
28% 0 498 0 501 32909 36817 33022 3485 0 0 7s 40% 10% Fn 9% 3 0 0 0 0 0 0
32% 0 517 0 517 34277 39103 42443 67154 0 0 4s 79% 100% :f 20% 0 0 0 0 0 0 0
29% 0 518 0 518 34322 38960 32792 61304 0 0 9s 79% 100% :f 17% 0 0 0 0 0 0 0
snapvault destination
CPU NFS CIFS HTTP Total Net kB/s Disk kB/s Tape kB/s Cache Cache CP CP Disk OTHER FCP iSCSI FCP kB/s iSCSI kB/s
in out read write read write age hit time ty util in out in out
26% 0 0 0 0 38315 848 3836 59486 0 0 4s 100% 63% Ff 12% 0 0 0 0 0 0 0
18% 0 0 0 0 37695 835 8 63256 0 0 4s 100% 100% :f 10% 0 0 0 0 0 0 0
14% 0 0 0 0 39143 866 204 12792 0 0 4s 100% 30% : 12% 0 0 0 0 0 0 0
24% 0 0 0 3 38654 855 5348 34448 0 0 4s 100% 40% Ff 11% 3 0 0 0 0 0 0
18% 0 0 0 0 37276 825 1800 62192 0 0 4s 100% 100% :f 10% 0 0 0 0 0 0 0
17% 0 0 0 0 38087 843 836 38444 0 0 4s 100% 78% : 13% 0 0 0 0 0 0 0
22% 0 0 0 0 39770 883 2412 23292 0 0 4s 100% 27% Ff 7% 0 0 0 0 0 0 0
19% 0 0 0 0 39647 881 692 63520 0 0 26 100% 100% :f 11% 0 0 0 0 0 0 0
17% 0 0 0 3 38304 848 808 47420 0 0 26 100% 91% : 20% 3 0 0 0 0 0 0
19% 0 0 0 0 40060 886 1175 7936 0 0 4s 100% 9% Fn 5% 0 0 0 0 0 0 0
24% 0 0 0 0 42355 936 6378 83141 0 0 26 100% 100% :f 16% 0 0 0 0 0 0 0
17% 0 0 0 0 38834 859 428 44140 0 0 26 100% 82% : 14% 0 0 0 0 0 0 0
12% 0 0 0 0 36964 818 0 8 0 0 4s 100% 0% - 2% 0 0 0 0 0 0 0
26% 0 0 0 5 35451 785 3360 83496 0 0 4s 100% 97% Ff 16% 5 0 0 0 0 0 0
18% 0 0 0 0 36488 808 1364 52212 0 0 4s 100% 96% : 14% 0 0 0 0 0 0 0
12% 0 0 0 0 36823 815 0 0 0 0 4s 100% 0% - 0% 0 0 0 0 0 0 0
26% 0 0 0 0 38536 853 3904 60112 0 0 5s 100% 59% Ff 13% 0 0 0 0 0 0 0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ah, forgot. The volume is new and only 20% is used.
source
VUMEF004> df -Vh /vol/VUMEF004_nas_vol009/
Filesystem total used avail capacity Mounted on
/vol/VUMEF004_nas_vol009/ 7782GB 1533GB 6248GB 20% /vol/VUMEF004_nas_vol009/
/vol/VUMEF004_nas_vol009/.snapshot 409GB 878MB 408GB 0% /vol/VUMEF004_nas_vol009/.snapshot
destiantion
VUMEF006> df -Vh /vol/VUMEF006_svd_VUMEF004_nas_vol009/
Filesystem total used avail capacity Mounted on
/vol/VUMEF006_svd_VUMEF004_nas_vol009/ 7782GB 1094GB 6688GB 14% /vol/VUMEF006_svd_VUMEF004_nas_vol009/
/vol/VUMEF006_svd_VUMEF004_nas_vol009/.snapshot 409GB 4219MB 405GB 1% /vol/VUMEF006_svd_VUMEF004_nas_vol009/.snapshot
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is fair to say the system is not maxed out for CPU, Disk I/O or Network. Looks like you are using 1/2 of 1Gb pipe so it should do more.
Have you confirmed that the snapvault does not have throttling enabled? snapvault modify filer:/vol/volname/qtree
Bren
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also have a look at the options of both filers for replication throttle
options rep
If there is no throttling it could be a network throughput issue. Here is how to get a network trace from the filer.
https://kb.netapp.com/support/index?page=content&id=1010155
Good luck
Bren
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
VUMEF004> options rep
replication.logical.reserved_transfers 0 (value might be overwritten in takeover)
replication.throttle.enable off
replication.throttle.incoming.max_kbs unlimited
replication.throttle.outgoing.max_kbs unlimited
replication.volume.reserved_transfers 0 (value might be overwritten in takeover)
replication.volume.use_auto_resync off (value might be overwritten in takeover)
VUMEF006> options rep
replication.logical.reserved_transfers 0 (value might be overwritten in takeover)
replication.throttle.enable off
replication.throttle.incoming.max_kbs unlimited
replication.throttle.outgoing.max_kbs unlimited
replication.volume.reserved_transfers 0 (value might be overwritten in takeover)
replication.volume.use_auto_resync off (value might be overwritten in takeover)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
looks ok to me
VUMEF006> snapvault modify VUMEF006:/vol/VUMEF006_svd_VUMEF004_nas_vol009/xxxxx
No changes in the configuration.
Configuration for qtree /vol/VUMEF006_svd_VUMEF004_nas_vol009/xxxxx is:
/vol/VUMEF006_svd_VUMEF004_nas_vol009/xxxxx source=VUMEF004:/vol/VUMEF004_nas_vol009/xxxxx kbs=unlimited tries=2 back_up_open_files=on,ignore_atime=off,utf8_primary_path=off
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What is the round trip latency between SnapVault primary and secondary systems?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
VUMEF004> ping -s vumef006
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=0 ttl=250 time=42.132 ms
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=1 ttl=250 time=56.589 ms
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=2 ttl=250 time=40.971 ms
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=3 ttl=250 time=54.194 ms
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=4 ttl=250 time=39.315 ms
VUMEF006> ping -s vumef004
64 bytes from vumef004.rd.corpintra.net (xx.60.6.232): icmp_seq=0 ttl=250 time=46.550 ms
64 bytes from vumef004.rd.corpintra.net (xx.60.6.232): icmp_seq=1 ttl=250 time=55.573 ms
64 bytes from vumef004.rd.corpintra.net (xx.60.6.232): icmp_seq=2 ttl=250 time=43.920 ms
64 bytes from vumef004.rd.corpintra.net (xx.60.6.232): icmp_seq=3 ttl=250 time=51.817 ms
I have too look into this again on monday, then I will contact the network people again and our netapp support. Thanks so far!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also look at traceroute to see which hope is giving you the problem.
My ping is across multiple routers and a WAN link and I get >10ms
round-trip min/avg/max = 0.895/1.746/6.016 ms
Bren
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Without knowing anything else with the environment, I think (this is a wild speculation) the limited window size *might* be your issue here. Assuming 45ms round trip latency (RTT) from your output you posted earlier.
Max throughput possible = Window Size / RTT = 2MB / 45ms =~ 44MB/s
The max and default window size for SnaVault is 2MB as of now. I need to confirm if there are plans to increasing this.
I suggest you open a case and resolve/confirm is this is the real issue.
Regards
Srinath
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ah, this looks interesting....
Now, without the snapshot transfer, the RTT looks perfectly normal.
VUMEF004> ping -s vumef006
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=0 ttl=250 time=0.395 ms
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=1 ttl=250 time=0.410 ms
64 bytes from vumef006.rd.corpintra.net (xx.62.180.179): icmp_seq=2 ttl=250 time=0.435 ms
VUMEF006> ping -s vumef004
64 bytes from vumef004.rd.corpintra.net (xx.60.6.232): icmp_seq=0 ttl=250 time=0.445 ms
64 bytes from vumef004.rd.corpintra.net (xx.60.6.232): icmp_seq=1 ttl=250 time=0.431 ms
64 bytes from vumef004.rd.corpintra.net (xx.60.6.232): icmp_seq=2 ttl=250 time=0.402 ms
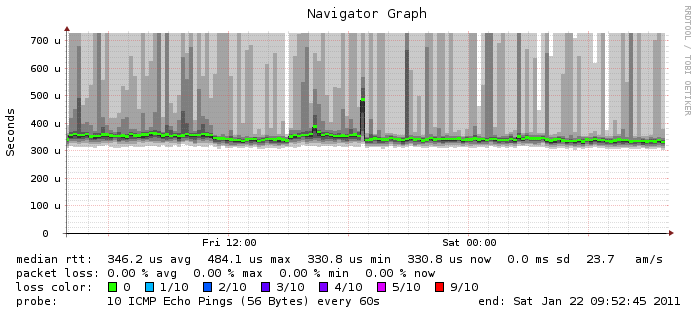
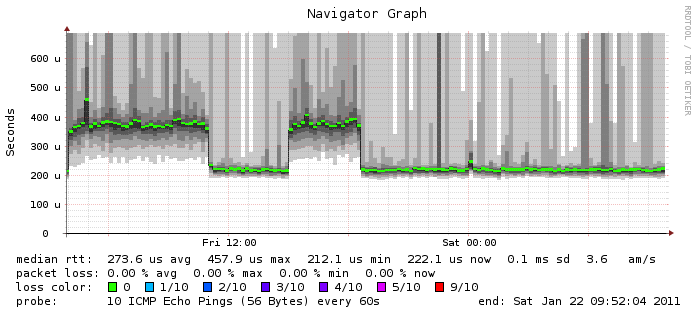
Both systems are monitored with smokeping. I see an increase in the RTT from the monitoring server during snapshot transfer too, but ony in the 400 us range (graphs attached).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
this is a bit strange. I only see this high RTT during the snapshot transfer. And it's not the same for all clients/server.
- VUMEF004 (source) -> VUMEF006 (destiantion): high RTT during snapshot transfer (0,2 ms -> 40 ms) in both directions.
- monitoring server (same datacenter as VUMEF004) -> VUMEF004: higher RTT, but only 0,2 ms -> 0,5 ms
- monitoring server -> VUMEF006: higher RTT, but only 0,2 ms -> 0,5 ms
So smokeping on the monitoring server doesn't see the extrem high RTT during snapshot transfer.
- my desktop client -> VUMEF004: higher RTT, 0,2 ms -> 40 ms
- my desktop client -> VUMEF006: higher RTT, but only 0,2 ms -> 0,5 ms
Can this be realated to the ifgrp settings? So that depending on the IP adresse, a different interface of the 4 in this ifgrp is answering the UDP packets? Should I see such a high RTT during snapshot transfer at all? The networt people told me again that none of the switches between the two netapp systems is a bottleneck.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, did some debugging with the networking support... The vif0 port group consist of 4 interfaces on netapp side (e4b, e3a, e4a, e3b) and is part of a cisco etherchannel. vif0 ueses an IP based hash, so does the Cisco etherchannel. The 4 ports on the Cisco side are split up in 2 switch modules to get module redundancy.
We started with removing one switch port interface after the other on the switch side from the etherchannel. When there was just one interace in the etherchannel left, the throughput jumped up to 120 MB/s, which is what I would have also expected for vif0 with 4 active ports - max. speed of one interface. Then we enabled all interfaces and did the same again but starting on the other switch module. The same effect, but after enabling the second interface again, the throughput stayed at 120 MB/s. This seems to be a bit random.
The networking people still say the config of the etherchannel is ok and not differnt to other netapp filers.
VUMEF004> ifgrp status vif0
default: transmit 'IP Load balancing', Ifgrp Type 'multi_mode', fail 'log'
vif0: 2 links, transmit 'IP Load balancing', Ifgrp Type 'multi_mode' fail 'default'
Ifgrp Status Up Addr_set
up:
e4b: state up, since 24Jan2011 12:39:35 (00:38:59)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 2800144986, input bytes 353775398696
output packets 205795367, output bytes 283714034956
up indications 2, broken indications 1
drops (if) 0, drops (link) 4
indication: up at 24Jan2011 12:39:35
consecutive 3355235, transitions 3
e3a: state up, since 24Jan2011 12:37:40 (00:40:54)
mediatype: auto-1000t-fd-up
flags: enabled
input packets 10953612, input bytes 869592825
output packets 11440162, output bytes 16913835120
up indications 2, broken indications 1
drops (if) 0, drops (link) 1
indication: up at 24Jan2011 12:37:40
consecutive 3355350, transitions 3
broken:
e4a: state broken, since 24Jan2011 12:38:13 (00:40:21)
mediatype: auto-1000t-fd-down
flags:
input packets 44847287, input bytes 4604932999
output packets 5155921939, output bytes 7783151794313
up indications 2, broken indications 2
drops (if) 0, drops (link) 18
indication: broken at 24Jan2011 12:38:13
consecutive 3354048, transitions 4
e3b: state broken, since 24Jan2011 12:38:06 (00:40:28)
mediatype: auto-1000t-fd-down
flags:
input packets 26651056, input bytes 2106565453
output packets 62931662, output bytes 26813694553
up indications 2, broken indications 2
drops (if) 0, drops (link) 0
indication: broken at 24Jan2011 12:38:06
consecutive 3353953, transitions 4
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Every interface on its own in the etherchannel delivers the full 120 MB/s speed. But... as soon as there are more ports in the channel/vif0 active _and_ the incoming and outgoing packets are comin in / going out on different ports the throughput dropps to 40 MB/s. If 2..3..4 ports are active but the in/out traffic is going to the same interface everything is fine.
IMHO this is strange, because it is perfectly normal that the netapp filer chooses a outgoing port based on the IP hash, and the switch chooses a different port on its own hash for the packets directed to the netapp.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I completely forgot to give some feedback.
NetApp Support could reproduce the problem. It's a bug in at least Ontap 8.0.1. The workaround ist to do a setflag tcp_do_rfc1323 0 on the snapvault destination filer. After that the throughput rises to ~100 MB/s with all 4 interfaces active. That's still ~20 MB/s less than with a single interface, but much better than the 40 MB/s before.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}