This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
ONTAP Hardware
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Hardware
- :
- Re: FAS 3140 FC High CPU load ?
ONTAP Hardware
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey,
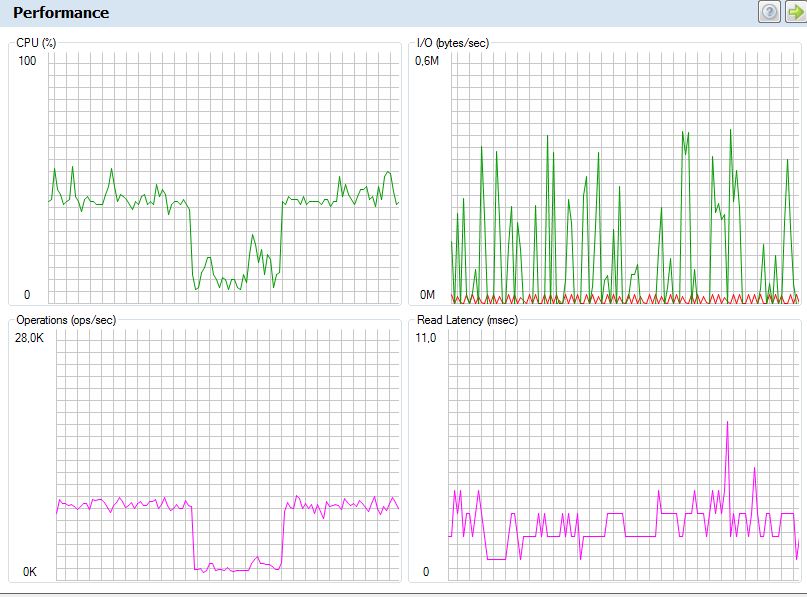
i was wondering if anybody has had the problem that the filer goes way over 60% CPU Load for a certain time and then FALLS down to below 10 % for a few minutes and then goes back to over 60% again without any major changes in the devices connected to it. it looks like a scheduled task but not even the support can say if something is wrong.
using around 10 ESX Servers with 120 VMs and 2 Brocade FC switches connected to it. perfstat file just showed Netapp that IO response times are okay. but why does it go up and down all the time ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How about a few more technical details including ONTap version.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
7.3.2P4
Snapmirror running nightly, Dedup running nightly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I guess you could run a stats or perfstats run to try to pinpoint things a bit closer. I'd check your reallocation schedules one more time. You might also want to check 'lun config_check' to see if you are (in the case that you have a cluster... again... no details... ) to see if you have some passive paths in use. The last thing is to run through the list of fixed bugs. I ran 7.3.2P4 on a few boxes for a while. It's not the worst release, but 7.3.5.1 seems to be very good up to this point. You might (will probably) find some bugs on wafl scanners that are running too often. Then you can schedule an upgrade.
Good luck.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Could a passive path usage produce high cpu load ?
Do you think it could be a lack of free space in one of the 2 aggregates ?
where could i check the reallocation schedules ?
thanks for the help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
If you have a NetApp HA cluster, then incorrectly configured FC paths will cause you extra CPU load, yes. This is essentially when the hosts try to access LUN's that are on the NetApp "partner" controller. Again, run 'lun config_check -v ' on the cli.
I don't know how much free space you have, so it is hard to comment on whether or not that is a problem.
To check your reallocation schedules, just run 'reallocate status -v'. I've managed to fat-finger the interval based things to run minutes apart a few times before... instead of days apart.
It seems you really need to familiarize yourself with the NOW website as well. All of the documentation is there. There is a ton of knowledge and help to be found there. I think what you are seeing is a wafl scanner that is running buggy. Even if I'm not a fan of pushing upgrades for everything, I was glad to get away from 7.2.x and over to 7.3.5.1 .
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thank you ! this already helps. i know i have to get deeper knowlege of the NOW site, will try to solve that soon. I just had the impression i wanna ask here for a fair comment on it cause both consultants that are here for upgrades/installations told me either to 1) make a call at netapp for help -> didnt help much or 2) buy a new filer with more power.... wanted to double check with other netapp users before deciding what to do next.
about the space, i heard from several people that running 85-90 % aggregate will make a filer go slow, we are down to 80 % at the moment, wasnt sure if that could be a reason for ontap to move around data. we are getting a new shelf next week anyway, maybe this solves it also ?
reallocate status -v
Reallocation scans are on
No reallocation status.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
If you aren't seeing any external I/O when these spikes are coming, then it is most likely an internal routine. If you have the chance to upgrade (the amount of effort is small, the risk low, and it might solve the problem without tons of investigation), then do that.
You aren't doing any reallocation, which may or may not be a bad thing. Your LUN fragmentation will increase over time and the performance will decrease. You might want to get reading up on that too.
80% shouldn't really be a problem, at least not from decreased performance because of WAFL.
Remember to reallocate your volumes when you add disks... Do try to squeeze in some reading on storage allocation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
if you run sysstat -m 5 from CLI during high and low load moments,
does this shows the same values?
gr,
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can drive yourself crazy chasing CPU reasons in Data ONTAP. In 7.x it's a proprietary (made by NetApp) kernel that reprioritizes CPU usage based on actual workload. I've personally seen a system pegged at 100% CPU doing internal workload drop to low numbers on new/incoming client workload (NAS/SAN traffic). The thought process in the design is to use the maximum CPU for existing tasks to get them done quicker, but make sure that it never impacts the client protocols.
NetApp encourages you to investigate the cause of any increased or unacceptable latency and if it's a runaway process consuming CPU then we can help you find if that's tied to a workload request, undersized hardware, or some type of bug in the software.
HTH
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks for the answer. its increased, yeah, but not unacceptable for now. i just wanted a heads up IF we have to do something, fix or upgrade or so. since the call didnt really bring out much knowledge of the situation, and my FC fabrig health is all fine i just thought id give it a try here to get a opinion of whats going on with our hardware. sorry for the questions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
what would you say that i have to check next. had a storage consultant here last few days, got a new shelf and configured reallocate for my volumes on the FC filer which has high cpu load.
he said hes seeing lots of FC traffic when using sysstat. what i wonder now is:
lets say there is 60 % cpu for 20 minutes, AND around 40.000 FC according to sysstat, then in that low moment it drops to 10 % CPU load AND the FC traffic is low too down to around 5000.
now i checked my Brocade traffic monitoring to check the traffic on the uplink to the netapp, and guess what, its NOT going over 5% even. its almost idle. where do i have to dig to find the where the load comes from and WHY it stops all of a sudden, makes a break and then goes on ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would state a priv set -q diag; statit -b at the beginning of a high-cpu-period followed by a statit -e at the end of that period.
Maybe you want to do it from a Linux/UNIX Client and pipe the output to a file like this
client-prompt> ssh filername 'priv set -q diag; statit -e' >filername_statit.out
The command statit -b starts sampling several statistics (b for begin); statit -e stops sampling (e for end) and gives a lot of output.
The second section is called 'Multiprocessor Statistics', where you might find out, what your CPUs are busy with.
Although you might not understand at once what these cpu-domains mean (like 'grab kahuna' and such), at least you will get a buzzword to investigate further.
Another guess: Could this be application-driven? Maybe your application(s) do build reports or such out of a database running on your LUNs. That could be reading out lots of data (for about 30 minutes - that's the action) then calculating and building the report out of that data - which could take 10 minutes? But there must be traffic then over FC when massive reading takes place...
Another guess: A lot of FC Operations without much I/O makes me think of LUN misalignment. If you do have ONTAP 8.x, then run a 'priv set -q advanced; lun show -v' to check this.
If you are running ONTAP 7.x you can have a look at stats lun:*:read_align_histo and lun:*:write_align_histo. Or you can use mbrscan / mbralign tools which come with the FC Host Utilities
HTH
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks everyone, this has been resolved. it has been 1 VM that has some kind of virus/error which was permanently writing stuff on its volume. ive found out about it via esxtop and once it was down the filer has gone down too, no more spikes. ive reallocated all volumes anyway and will check alignment. thank you!

{kind=link}