ONTAP Hardware
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Hardware
- :
- Re: Identifying failed disk
ONTAP Hardware
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I have an aggregate with 4 raid groups.
Received a messages about not enough spare disks in pool.
Looked at the filer and figure out there are 2 failed disk. However there is no amber light on a disk and there is no information in output of aggr status -r command about failed disk location.
Tried to compare 2 outputs show disk and storage show disk, found three missing drives. I replaced those 3 drives and the issue still there.
Thinking of backplane failure...
Any advices really appreciated.
Thanks
FILER2*> aggr status -r
Aggregate aggr0 (online, raid_dp) (block checksums)
Plex /aggr0/plex0 (online, normal, active, pool0)
RAID group /aggr0/plex0/rg0 (scrubbing 2% completed, block checksums)
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
Aggregate aggr1 (online, raid_dp, degraded) (block checksums)
Plex /aggr1/plex0 (online, normal, active, pool0)
RAID group /aggr1/plex0/rg0 (scrubbing 3% completed, block checksums)
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
dparity 0a.73 0a 4 9 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
parity 0d.82 0d 5 2 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.70 0d 4 6 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
--
RAID group /aggr1/plex0/rg1 (degraded, scrubbing 3% completed, block checksums)
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
dparity FAILED N/A 136000/ -
parity 0d.28 0d 1 12 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.69 0a 4 5 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.21 0d 1 5 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.90 0a 5 10 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
RAID group /aggr1/plex0/rg2 (degraded, scrubbing 0% completed, block checksums)
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
dparity 0c.112 0c 7 0 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
parity 0a.32 0a 2 0 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.52 0d 3 4 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0a.80 0a 5 0 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.64 0d 4 0 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0a.112 0a 7 0 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0c.113 0c 7 1 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0a.33 0a 2 1 FC:B 0 FCAL 10000 136000/278528000 137485/281570072
data 0a.54 0a 3 6 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.81 0d 5 1 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.65 0d 4 1 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.113 0d 7 1 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0c.114 0c 7 2 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.37 0a 2 5 FC:B 0 FCAL 10000 136000/278528000 137485/281570072
data FAILED N/A 136000/ -
data 0d.84 0d 5 4 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
Pool1 spare disks (empty)
Pool0 spare disks (empty)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can look at sysconfig -a and see if any disks are missing/bypassed/failed. If you have a guess as to when they failed, or failed within a month, then you can probably look at the oldest weekly_log ASUP and compare its sysconfig -r output. I'm not sure if you can get those disks replaced, though. If your root vol snapshots go back far enough then you can look in there and look at their oldest messages.0/.1/.2/.3/.4/.5 file and see when the disks failed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
- sysconfig -r shows the same information.
- log files informing about data disk failed in rg1
autosupport files available for a month, however did not find any useful info there. Might be looking at the wrong place. ![]()
Filer doesn't send autosupport to NetApp, looking at the local files in /etc/log directory.
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't know which version of ONTAP it's running, but if you look in /etc/log/autosupport you will probably find a number of directories for each ASUP that's generated. I get that it's not sending ASUPs to NetApp but if it's getting generated it'll be there. And some of these ASUPs will have sysconfig -r output so if you look for old ones, you can probably find it. Having said that, you may also look through sysconfig -a and look at disk IDs and maybe you can find some missing disk IDs. For DS14 types the IDs run in 14 consecutive numbers with 2 missing numbers between shelves:
ID 16-29 for shelf 1
ID 32-45 for shelf 2, so on.
So you know the numbers you're supposed to be missing(30, 31, 46, 47, etc) If you're missing some IDs that should NOT be missing(43, for example), then it's probably not a bad guess that that's the missing/bypassed/failed disk. You may also need to do this from both nodes in a cluster(if this is an HA pair). Sometimes one node can report healthy status while the other won't.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You could also try "storage show hub" and "fcadmin device_map" commands to view similiar information.
Cannot find the answer you need? No need to open a support case - just CHAT and we’ll handle it for you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ok. found one 0d.20. Hoever in rg2 there was no luck 🙂
it failed a while ago. These findings actualy are the same as i compared two outputs i was talking above.
will try to swap disk one more time.
RAID group /aggr1/plex0/rg1 (normal, block checksums)
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
dparity 0d.20 0d 1 4 FC:B 0 FCAL 10000 136000/278528000 137422/281442144 (prefail)
parity 0a.28 0a 1 12 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.69 0d 4 5 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0a.21 0a 1 5 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.90 0d 5 10 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.29 0d 1 13 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.22 0a 1 6 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.35 0a 2 3 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0c.125 0c 7 13 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0d.23 0d 1 7 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.75 0a 4 11 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.24 0d 1 8 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.121 0a 7 9 FC:B 0 FCAL 15000 136000/278528000 137104/280790184
data 0d.25 0d 1 9 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.26 0a 1 10 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.27 0a 1 11 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
RAID group /aggr1/plex0/rg2 (degraded, block checksums)
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
dparity 0c.112 0c 7 0 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
parity 0a.32 0a 2 0 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.52 0d 3 4 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0a.80 0a 5 0 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.64 0d 4 0 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0a.112 0a 7 0 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0c.113 0c 7 1 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0a.33 0a 2 1 FC:B 0 FCAL 10000 136000/278528000 137485/281570072
data 0d.54 0d 3 6 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0a.81 0a 5 1 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.65 0d 4 1 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0a.113 0a 7 1 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0c.114 0c 7 2 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.37 0d 2 5 FC:B 0 FCAL 10000 136000/278528000 137485/281570072
data FAILED N/A 136000/ -
data 0a.84 0a 5 4 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
swapped one drive, it became a data disk in rg2.
RAID group /aggr1/plex0/rg2 (reconstruction 1% completed, block checksums)
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
dparity 0c.112 0c 7 0 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
parity 0d.32 0d 2 0 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.52 0d 3 4 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.80 0d 5 0 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.64 0d 4 0 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.112 0d 7 0 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0c.113 0c 7 1 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0d.33 0d 2 1 FC:B 0 FCAL 10000 136000/278528000 137485/281570072
data 0d.54 0d 3 6 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.81 0d 5 1 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
data 0d.65 0d 4 1 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.113 0d 7 1 FC:B 0 FCAL 10000 136000/278528000 137104/280790184
data 0c.114 0c 7 2 FC:B 0 FCAL 10000 136000/278528000 137422/281442144
data 0d.37 0d 2 5 FC:B 0 FCAL 10000 136000/278528000 137485/281570072
data 0a.20 0a 1 4 FC:B 0 FCAL 10000 136000/278528000 137422/281442144 (reconstruction 1% completed)
data 0d.84 0d 5 4 FC:B 0 FCAL 10000 136000/278528000 139072/284820800
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The problem solved. The easy way is just compare 2 outputs as i described above.
Love the message - System Global Status is Normal ![]()
thanks everyone
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Everyone,
Can anybody tell me how to get failed disk report on unified manager dashboard GUI. I am able to get the failed disk list using SSH on filers but want this report on OUM dashboard.
Please let me how can get this done with my onCommand unified manager dashboard.
Thanks in advance.
Vik
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@VIKAS_MAURYA wrote:Hello Everyone,
Can anybody tell me how to get failed disk report on unified manager dashboard GUI. I am able to get the failed disk list using SSH on filers but want this report on OUM dashboard.
Please let me how can get this done with my onCommand unified manager dashboard.
Thanks in advance.
Vik
I jist tried it, rarely use it. CLI 99.9% 🙂
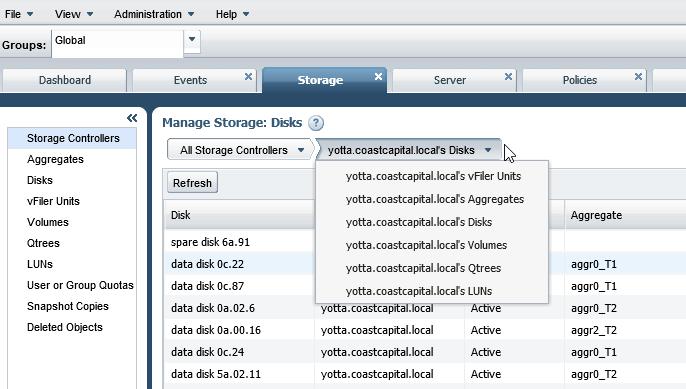
I think you can get it if you go to Storage tab, then pick your controller, from the drop down pick Disks.
All disks will be listed and the staus column most likely says "failed". I do not have any failed disks at the moment to confirm it, but I think it is the way to do it in OUM.
Hope it helps
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Many thanks KUDO..
I tried the same but no luck.
Though I have 3 failed disk in the selected controller(I can see it from CLI) but OUM does not show this value under more info tab under Storage section.
Kindly refer the snap shots for details.
Could you please let me know about the configuration which can give me the refelection of failed disk under more info tab.
Thanks in advance..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi VIM,
Thanks for your valuable response.
I looked on the same page you suggested but it does not show the failed disk status.
Yesterday I was trying to upload two sceen shots for others reference but it allows only one snap shot so I uploaded only one.
Please refer the below snap shot.

I have three failed disks in controller named Asimov but it does not show in OUM. Also it does not have status in all status catagories.
Please refer the CLI snap shot.

CLI has three failed disks but it does not appear in OUM.
Kindly correct me if I am wrong and not able to find the correct thing on GUI.
Thanks in advance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I just simply simulated failed drive in lab and what i figured out.
As you can see on CLI screenshot the drive 0a.17 has the status failed,
however in OUM the same disk has status Active. More over if you try to filter disks there is no filter Failed. (last screenshot).
I think it is by design and the way OUM report back to you.



- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks a ton VIM for your valuable response.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Everyone,
I have NetApp FAS3140 filer. It suddenly started rebooting. I tried to make it up and running but no luck. I checked on the diagnostic it seems either NVRAM is faulty or motherboard.
Could anyone suggest by referring the errors on the snap shot, what is the exact problem with the filer and what will be the resolution for it.

Many Thanks in advance.

{kind=link}
{kind=link}
{kind=link}