This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
Tech ONTAP Articles
- Home
- :
- Tech ONTAP Podcast and Blogs
- :
- Tech ONTAP Articles
- :
- Back to Basics: Deduplication
Tech ONTAP Articles
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Mark as New
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
 |  | ||||||||||||||||||
This month, Tech OnTap is pleased to bring you the second installment of Back to Basics, a series of articles that discuss the fundamentals of popular NetApp technologies to help you understand and get started using them. In 2007, NetApp introduced deduplication technology that significantly decreases storage capacity requirements. NetApp deduplication improves efficiency by locating identical blocks of data and replacing them with references to a single shared block after performing a byte-level verification check. This technique reduces storage capacity requirements by eliminating redundant blocks of data that reside in the same volume or LUN. NetApp deduplication is an integral part of the NetApp Data ONTAP® operating environment and the WAFL® file system, which manages all data on NetApp storage systems. Deduplication works "behind the scenes," regardless of what applications you run or how you access data, and its overhead is low. A common question is, "How much space can you save?" We'll come back to this question in more detail later, but, in general, it depends on the dataset and the amount of duplication it contains. As an example, the value of NetApp deduplication in a mixed environment with both business and engineering data is illustrated by Atlanta-based Polysius Corporation, which designs and enhances new and existing cement plants. Polysius was experiencing up to 30% annual increases in its production storage requirements. By applying deduplication to its mix of AutoCAD files, Microsoft® Office documents, and other unstructured data, Polysius was able to recover 47% of its storage space. Some volumes showed reductions as high as 70%. As a result, the company was able to defer new storage purchases and has been able to double the time period it retains backup data on disk. Read the Polysius success story for more details. There are some significant advantages to NetApp deduplication:
This chapter of Back to Basics explores how NetApp deduplication is implemented, the most common use cases, practices for implementing deduplication, and more. How Deduplication Is Implemented in Data ONTAP
At its heart, NetApp deduplication relies on the time-honored computer science technique of reference counting. Previously, Data ONTAP kept track only of whether a block was free or in use. With deduplication, it also keeps track of how many uses there are. Using deduplication, a single block can be referenced up to 255 times for both NAS and SAN configurations. Files don't "know" that they are using shared blocks—bookkeeping within WAFL takes care of the details invisibly.
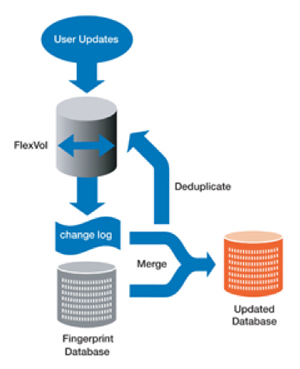
Figure 1) How NetApp deduplication works. How does Data ONTAP decide that two blocks can be shared? The answer is that, for each block, it computes a "fingerprint," which is a hash of the block's data. Two blocks that have the same fingerprint are candidates for sharing. When NetApp deduplication is enabled, it computes a database of fingerprints for all of the in-use blocks in the volume (a process known as "gathering"). Once this initial setup is finished, the data is ready for deduplication. To avoid slowing down ordinary operations, the search for duplicates is done as a separate batch process. As data is written during normal use, WAFL creates a catalog of fingerprints for this data. This catalog accumulates until dedupe is triggered by one of the following events, as determined by the storage system administrator:
Once the deduplication process is started, a sorting operation begins, using the fingerprints of the changed blocks as a key. This sorted list merges with the fingerprint database file. Whenever the same fingerprint appears in both lists, there are possibly identical blocks that can be collapsed into one. In this case, Data ONTAP can discard one of the blocks and replace it with a reference to the other block. Since the file system is changing all the time, we of course can take this step only if both blocks are really still in use and contain the same data. To make sure that two blocks are really identical, we do a byte-by-byte comparison after the candidate blocks are identified. The implementation of NetApp deduplication takes advantage of some special features of WAFL to minimize the cost of deduplication. For instance, every block of data on disk is protected with a checksum. NetApp uses this checksum as the basis for the fingerprint. Since we were going to compute it anyway, we get it "for free"—there is no additional load on the system. And since WAFL never overwrites a block of data that is in use, fingerprints remain valid until a block gets freed. The tight integration of NetApp deduplication with WAFL also means that change logging is an efficient operation. The upshot is that deduplication can be used with a wide range of workloads, not just for backups, as has been the case with other deduplication implementations. Use Cases
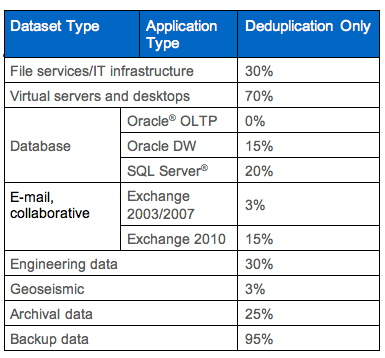
NetApp has been measuring the benefits of deduplication in real-world environments since deduplication was introduced. The most popular use cases are VMware® and VDI, home directory data, and file services. Microsoft SharePoint® and Exchange 2010 are also rapidly gaining traction. Many Tech OnTap articles have focused on the particular benefits of deduplication in VMware and VDI environments, which have an inherently high level of file duplication owing to the nearly identical operating system environments used by each virtual machine. The following table summarizes typical results for a variety of environments. Table 1) Typical deduplication space savings.
In a typical VMware or VDI environment you may have numerous virtual machines (VMs) that are all installed with more or less the same operating system and applications, resulting in a lot of duplication. If you have 100 VMs running the same OS and each virtual machine requires 10GB to 20GB of storage, that's 1TB to 2TB of storage dedicated to almost identical copies. Applying NetApp deduplication can eliminate much of the inherent redundancy. In general terms, if you have X virtual machines assigned to a storage volume, after deduplication you will need approximately 1/X the amount of operating system storage you would require in a nondeduplicated environment. Obviously, the actual results you achieve will depend on how many VMs you have in a volume and how similar they are. In practice, customers typically see space savings of 50% or more in ESX VI3 environments, with some obtaining storage savings as high as 90%. This is for deduplication of the entire VMware storage environment, including application data—not just operating systems. In VDI environments, customers typically see space savings of up to 90%. NetApp has also been investigating the benefits of deduplication on the repositories of unstructured file data created by some popular engineering and scientific applications, including Siemens Teamcenter PLM software, IBM Rational ClearCase SCM software, and Schlumberger Petrel software for seismic data analysis. Teamcenter utilizes a relatively small metadata database combined with a large "vault," where engineering design files are stored. Every time an engineer saves a design within Teamcenter, a complete copy of that design file is saved in the vault, even if the change made to the design is minor. NetApp worked closely with Siemens PLM to assess the value of deduplication in a Teamcenter environment using Siemens's performance and scalability benchmarking tool, which simulates the creation of multiple revisions of many design files, as would occur during normal use. Deduplication of the resulting vault yielded a 57% space savings. Results in the real world might be even higher than this since in many cases the number of file revisions is likely to be higher than that which we simulated. (Of course, in general you have to be careful when using simulators to measure the potential savings of deduplication. Simulated data in many cases will create artificially high amounts of duplicate data, since the focus is typically performance, not data patterns.) Similar to Teamcenter, IBM Rational ClearCase—a leading software configuration management solution—consists of a metadata database in combination with a large "versioned object base," or VOB, in which files are stored. Deduplication is most useful with ClearCase in situations in which a copy of a VOB needs to be made. In addition, preliminary results in a laboratory environment suggest space savings of 40% or more using deduplication in a ClearCase environment when whole files are stored. Schlumberger Petrel is used for seismic data interpretation, reservoir visualization, and simulation workflows. It creates project directories that contain huge numbers of files. As users create, distribute, and archive data, duplicate data objects are stored across multiple storage devices. NetApp observed space savings of approximately 48% by applying deduplication to such project directories. Using NetApp Deduplication
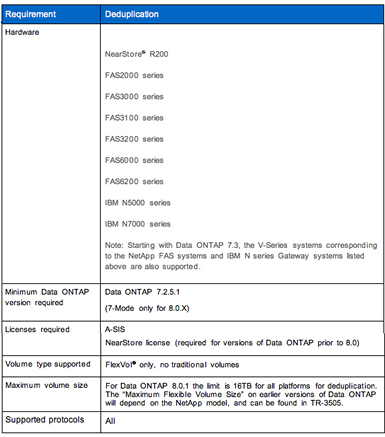
The basic requirements for running NetApp deduplication are summarized in Table 2. Table 2) Basic requirements for NetApp deduplication.
In addition to these requirements, attention to a few best practices can help enable success with deduplication. Some of the important best practices are summarized in this section along with information about using deduplication in conjunction with other popular NetApp technologies. For full details, refer to TR-3505: NetApp Deduplication Deployment and Implementation Guide.
Deduplication and Other NetApp Technologies Deduplication is designed to work with other NetApp technologies. In many cases, those technologies get an additional benefit:
Conclusion
Deduplication is an important storage efficiency tool that can be used alone or in conjunction with other storage efficiency solutions such as NetApp thin provisioning, FlexClone, and others. To learn more about deduplication, be sure to refer to TR-3505: NetApp Deduplication for FAS and V-Series Deployment and Implementation Guide. This frequently updated guide covers a broad range of topics including:
Ask questions, exchange ideas, and share your thoughts online in NetApp Communities.
| Deduplication in Tech OnTap Want to know more about deduplication? You may be interested in reading these previous articles from Tech OnTap:
More Back to Basics The first Back to Basics article focused on NetApp® thin provisioning. Check out the article to learn how it's implemented, best practices, and more. | ||||||||||||||||||
| |||||||||||||||||||


Please Note:
All content posted on the NetApp Community is publicly searchable and viewable. Participation in the NetApp Community is voluntary.
In accordance with our Code of Conduct and Community Terms of Use, DO NOT post or attach the following:
- Software files (compressed or uncompressed)
- Files that require an End User License Agreement (EULA)
- Confidential information
- Personal data you do not want publicly available
- Another’s personally identifiable information (PII)
- Copyrighted materials without the permission of the copyright owner
Continued non-compliance may result in NetApp Community account restrictions or termination.
Hi Carlos,
Thanks for the great article...
Could you please guide me that how to findout a acual used space of a volume in the case of deduplicaion enabled.
Regards
Anil
