We are running ontap 7.3.3 and our vmware environment has a number of NFS datastores.
these volumes are no guarantee, 20 odd % snapshot reserve with dedupe enabled.
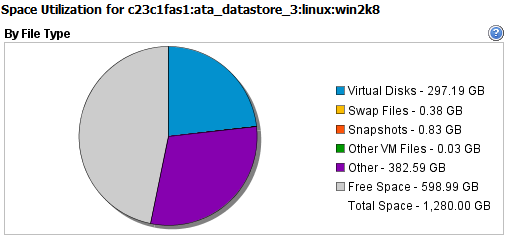
Here is the strange part - the space breakdown shows xGB virtual disks, xGB swap files, xGB snapshots, xGB other VM files, xGB other, xGB free space -- the weird thing is the xGB of other, what is other? I have browsed the datastore and there is nothing relating to this used space, which infact consumes a large amount of the datastore itself.
I have at one time seen this disappear completely within 1-5 minutes, this is a lot of data to be purged at in a small space of time, around 300GB or more.
The only thing I can see that occurred at that time was that I migrated a powered off vm to another datastore to free up some space on the datastore to allow other vms to continue operating.
I have attached a screenshot of this quirk to this thread.
If anyone can explain this it would be much appreciated.
cheers
Jurgen

{kind=link}