Active IQ Unified Manager Discussions
- Home
- :
- Active IQ and AutoSupport
- :
- Active IQ Unified Manager Discussions
- :
- Clarification on using filters with finders...
Active IQ Unified Manager Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just started playing with WFA 1.1.1 and I am not sure how exactly one would combine a filter with a finder. or When one would use a filter over a finder?
Can someone explain this to me please...
Let's say that I want to limit the need to a user to choose a particular aggregate, but I also wanted to prevent certain aggregates from being used for certain workflows.
I see that I can create a query in the user inputs area to limit the aggregates displayed for the user to choose. However, if I wanted to simply allow the user to choose a controller and do something other than just find an aggregate by avalable capacity and overcommitment (an existing finder). Let's say that I wanted to use an aggregate that has the most available space but is in a particular group (all aggregates with a name like %_ORA or some other string of characters). I assum I would use a finder and a filter, but it is not clear how I would do that.
Similarly, if I wanted to use a particular group of controllers and not make the user input a controller choice, I would assume I could do something similar. With a c-mode system, It may be easier since could do things based on cluster and not node, but I have not yet played with a c-mode system.
Thanks.
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tom,
Finders are a collection of one or more filters. It is designed that way to keep the filters as simple as possible, then have the ability to roll multiple filters into one finder.
For your first example, "Let's say that I wanted to use an aggregate that has the most available space but is in a particular group (all aggregates with a name like %_ORA or some other string of characters)." I think I can do that with existing filters. Here's what it would look like:
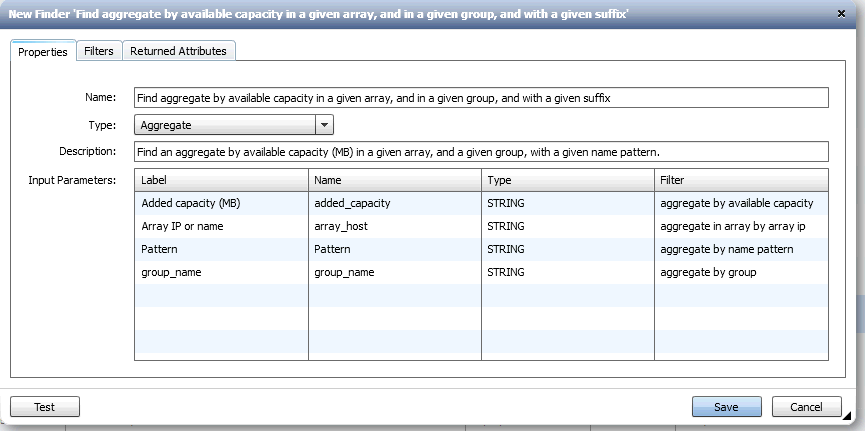


The big trick (above) is in moving the sort order on available capacity to the top and setting its order to DESCENDING. That makes the largest found volume returned. (You have to return at least the natural key attributes for the object you're identifying. You can return other attributes as well, especially useful if you want the finder to sort the results based on those attributes. For regular finders, only the top 1 item is used. For looping finders, the whole list is used.)
Then, testing is also important. Good thing that's built in... To test this, I created a group called gold_aggrs and put 'aggr0, Aggr01, and Aggr02' in there. something was up with my Aggr02 aggregate. It showed it was in a fault state and 'dfm details' showed it having zero free capacity. So, with Added capacity at 10MB, it filtered out Aggr02. I further tested by adding some aggregates from another array. Those were filtered out properly.
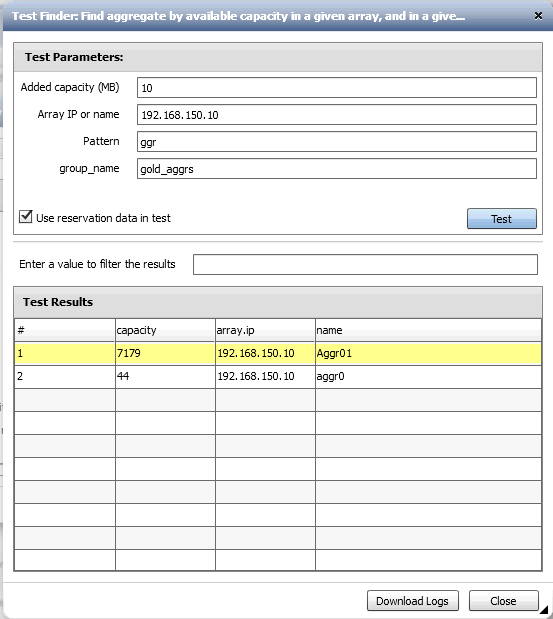
If you really wanted to have the finder work only for a suffix pattern, not just any pattern match, you could clone the "Aggregate by Name Pattern" filter, change the name to something more appropriate like "Aggregate by Name Suffix", and change the WHERE clause by removing the % at the end of the LIKE conditional. Then, add that filter to your finder instead of the "Aggregate by Name Pattern" so your workflow is more exact to your specifications than what I showed.
From some WFA concepts training slides:
¡ Finder
– A search operation for locating resources
– The finder looks for information on WFA Objects in the WFA cached repositories
– Comprised of several filtering rules that “filter out” irrelevant resources
– Includes a possible sorting order for the list of applicable results
– Populates a variable if a match was found
– Example: “Find Aggregate, Find Array, Find volume”
¡ A Finder’s result may populate a variable:
– Upon execution, the filters associated with the finder will narrow down the possible resources that correspond with the finder’s definition
– The finder will then sort the short list of still applicable resources based on available attributes as per filtration criteria
– The finder will either populate a variable with the information of the chosen WFA object or declare a match was not found
¡ Example: For locating an aggregate, we will:
– Input parameters for location and required capacity
– Select filters would run and filter out ill matching aggregates
– Sorting order will be employed based on selected aggregate attributes
– The result may be either a chosen aggregate or a decision that one was not available given the selected filtration criterias
Hope this helps,
Dave
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
You can create a resource pool in DFM, let's say, called "aggrs available for users". Then in your workflow you create a Finder called "Find aggr in a given resource pool" where you can pass the resource name as a parameter.
For instance I allow a DBA to create vol / LUN only in a mirrored aggr. If you have more than one mirrored aggr, then you can add more conditions to the Finder, eg "less than 85% space occupied" etc.
Vladimir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tom,
Finders are a collection of one or more filters. It is designed that way to keep the filters as simple as possible, then have the ability to roll multiple filters into one finder.
For your first example, "Let's say that I wanted to use an aggregate that has the most available space but is in a particular group (all aggregates with a name like %_ORA or some other string of characters)." I think I can do that with existing filters. Here's what it would look like:
The big trick (above) is in moving the sort order on available capacity to the top and setting its order to DESCENDING. That makes the largest found volume returned. (You have to return at least the natural key attributes for the object you're identifying. You can return other attributes as well, especially useful if you want the finder to sort the results based on those attributes. For regular finders, only the top 1 item is used. For looping finders, the whole list is used.)
Then, testing is also important. Good thing that's built in... To test this, I created a group called gold_aggrs and put 'aggr0, Aggr01, and Aggr02' in there. something was up with my Aggr02 aggregate. It showed it was in a fault state and 'dfm details' showed it having zero free capacity. So, with Added capacity at 10MB, it filtered out Aggr02. I further tested by adding some aggregates from another array. Those were filtered out properly.
If you really wanted to have the finder work only for a suffix pattern, not just any pattern match, you could clone the "Aggregate by Name Pattern" filter, change the name to something more appropriate like "Aggregate by Name Suffix", and change the WHERE clause by removing the % at the end of the LIKE conditional. Then, add that filter to your finder instead of the "Aggregate by Name Pattern" so your workflow is more exact to your specifications than what I showed.
From some WFA concepts training slides:
¡ Finder
– A search operation for locating resources
– The finder looks for information on WFA Objects in the WFA cached repositories
– Comprised of several filtering rules that “filter out” irrelevant resources
– Includes a possible sorting order for the list of applicable results
– Populates a variable if a match was found
– Example: “Find Aggregate, Find Array, Find volume”
¡ A Finder’s result may populate a variable:
– Upon execution, the filters associated with the finder will narrow down the possible resources that correspond with the finder’s definition
– The finder will then sort the short list of still applicable resources based on available attributes as per filtration criteria
– The finder will either populate a variable with the information of the chosen WFA object or declare a match was not found
¡ Example: For locating an aggregate, we will:
– Input parameters for location and required capacity
– Select filters would run and filter out ill matching aggregates
– Sorting order will be employed based on selected aggregate attributes
– The result may be either a chosen aggregate or a decision that one was not available given the selected filtration criterias
Hope this helps,
Dave
