Stay connected during the transition - Join our Discord community today.
General Discussion
- Home
- :
- General Discussion & Community Support
- :
- General Discussion
- :
- Best practice aggr
General Discussion
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just bought A700,
I have total of 48 disks ssd.
What is the best way to use it?
Its configure with 12 disks adpv2 and 36 no-paeriotioned.
Do i need to adp all 48 disks??
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Maryuma -
Basic principle of the AFF systems - maximum performance potential for each node will be achieved when each node has as many "disks" available to it as possible. The takeaway is that Root-Data-Data is a good idea for as many disks as you can use it for, up to a point. Some examples will help.
I have a customer who deployed AFF A700's in various sites. To start, two sites had 1.5 shelves (36 disks), the remaining had two full shelves. Disks were the 3.8TB variety. Because of the differences in the systems as well as who deployed at each site, the customer ended up with 3 different disk configurations.
All sites had Root-Data-Data partitioning enabled. In site 1, though, the 36 disks were assigned such that only one node of the HA pair owned both data partitions. This in effect simulates Root-Data style partitioning. Each node effectively, had 18 disks from which to grab data (ignoring parity just for convenience). Each node had 35 data partitions (one disk spare).
Site 2 was configured where each node had one data partition from every disk. Hence each node had 35 disk targets for the data and the aggregate size was the same as for site 1.
Site 3 where there were two full shelves was like site two but spread over all 48 disks. So each node has 47 disk targets and 47 data partitions.
Here's the fun part of the analysis. Using NetApp toolsets (NSLM in particular, which uses SPM for "reverse" performance capability), Site 1 was only half the rated performance of Site 2. The implication - the number of physical disks that a node can use very much impacts performance potential. Stated another way - using R-D2 fully spread out doubled the expected performance potential of the same hardware configured only using R-D.
In the same comparison, site 3's rated performance rating was 1.5x better than site 2 with only 1.3x the number of disks.
Recommendation: use RD2 up to the full two shelf potential. As you add disks after the first two shelves, create new raid groups in your existing aggregates and expand as you might normally.
Hope this helps.
Bob Greenwald
Senior System Engineer | cStor
NCIE SAN ONTAP, Data Protection; Flexpod Design Specialist
Kudos and accepted solutions are always appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
With root data partitions (not RD2).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Maryuma -
Basic principle of the AFF systems - maximum performance potential for each node will be achieved when each node has as many "disks" available to it as possible. The takeaway is that Root-Data-Data is a good idea for as many disks as you can use it for, up to a point. Some examples will help.
I have a customer who deployed AFF A700's in various sites. To start, two sites had 1.5 shelves (36 disks), the remaining had two full shelves. Disks were the 3.8TB variety. Because of the differences in the systems as well as who deployed at each site, the customer ended up with 3 different disk configurations.
All sites had Root-Data-Data partitioning enabled. In site 1, though, the 36 disks were assigned such that only one node of the HA pair owned both data partitions. This in effect simulates Root-Data style partitioning. Each node effectively, had 18 disks from which to grab data (ignoring parity just for convenience). Each node had 35 data partitions (one disk spare).
Site 2 was configured where each node had one data partition from every disk. Hence each node had 35 disk targets for the data and the aggregate size was the same as for site 1.
Site 3 where there were two full shelves was like site two but spread over all 48 disks. So each node has 47 disk targets and 47 data partitions.
Here's the fun part of the analysis. Using NetApp toolsets (NSLM in particular, which uses SPM for "reverse" performance capability), Site 1 was only half the rated performance of Site 2. The implication - the number of physical disks that a node can use very much impacts performance potential. Stated another way - using R-D2 fully spread out doubled the expected performance potential of the same hardware configured only using R-D.
In the same comparison, site 3's rated performance rating was 1.5x better than site 2 with only 1.3x the number of disks.
Recommendation: use RD2 up to the full two shelf potential. As you add disks after the first two shelves, create new raid groups in your existing aggregates and expand as you might normally.
Hope this helps.
Bob Greenwald
Senior System Engineer | cStor
NCIE SAN ONTAP, Data Protection; Flexpod Design Specialist
Kudos and accepted solutions are always appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
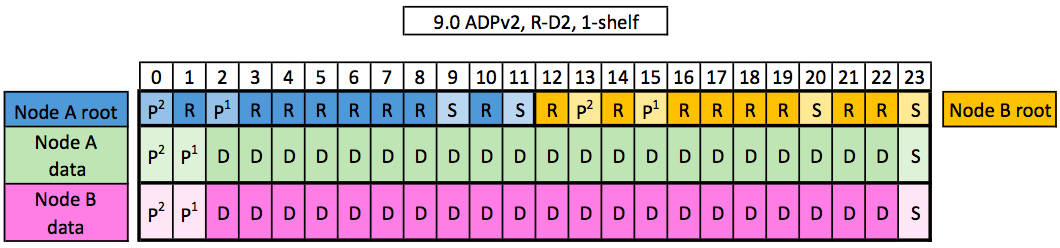
in 9.5... Is there way with ADPv2 to create one large AGGR on one controller, and just use the 2nd controller for failover. We don't need a second aggregate, we only have a 1 volume and want as must as space on a single controller as possible.
Tried creating a single aggr via system manager, but it wants to create 2 raid groups using 4 disk.
We want something like the below, however no PINK... Wanting all D's owned by Node A