Microsoft Virtualization Discussions
- Home
- :
- Virtualization Environments
- :
- Microsoft Virtualization Discussions
- :
- Re: netapp lun created as type windows for vmware.
Microsoft Virtualization Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
RDMs in VMWare are special in that the ESX kernel essentially passes through all I/O to the underlying LUN. That's good if you need to use a capability like SnapDrive/SnapManager within a Windows VM. Because the RDM is a "Windows" disk rather than a VMWare disk, the LUN type is properly set to Windows.
However, like any other "datastore" the RDM disk must be physically accessible by all the ESX hosts on which the Windows virtual machine might run. When you create a normal datastore, you map the LUN to all the ESX instances within an ESX cluster so that all the ESX instance can see all the data. With RDM's it's really easy to forget that you have to do the same type of mapping. RDM's act as if they "belong" to the Vm guest - but in actuality they still belong to the ESX instances hosting the guest. If you don't make the RDM available by standard LUN map commands to all the ESX hosts in the cluster, you woin't be able to vMotion the Guest VM anywhere since it can't access all the storage everywhere.
My particular preference is to have an initiator group for each ESX host (especially in case of boot from SAN if you do that kind of thing) but then also have an initiator group for all the hosts in the ESX cluster together. Storage (normal VMFS LUNs as well as RDMs) are all mapped through the cluster initiator group.
It's also easy to accidentally not create the right LUN mappings - with SnapDrive installed on a Windows VM, for instance, you can create an RDM LUN through the SD interface. But without great care and manual intervention, SD will not map the RDM to every host in the cluster. Best to do this kind of thing the old fashioned (read "manual" way). Similarly SD/SMgr products that use snapshots for clones, remote operations, etc., will also not map by default to the cluster in my experience - the cloned, snapshotted (etc.) LUN is only made accessible on the single ESX host that mounts the LUN in question.
Here is an additional resource for you on vMotion and RDMs - this comes from VMWare, as the whole question of RDMs and vMotion is properly an ESX issue: http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1005241
Bob Greenwald
Lead Storage Engineer, Huron Legal
Huron Consulting Group
NCDA, NCIE-SAN Clustered Data OnTap
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just adding to what what BOBSHOUSEOFCARDS said, in NetApp specific terminology, you would want to use a "windows" LUN type if the GOS is using it as a Windows 2003 MBR disk while maintaining a "vmware" igroup type becuase, as was said, the VMware host is what controls the actual IO.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bingen -
Thanks for that addition as it's an important clarification between LUN type and iGroup type.
Bob Greenwald
Lead Storage Engineer, Huron Legal
Huron Consulting Group
NCDA | NCIE-SAN Clustered Data OnTap
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Lets say that you have a LUN called /vol/vol1/lun1
And you have a four node ESX cluster with nodeA, nodeB, nodeC, and nodeD. And each node has two initiators.
The LUN /vol/vol1/lun1 should have the same LUN ID on all 8 initiators.
Like this.
initiatorA1 --> LUN 1
initiatorA2 --> LUN 1
initiatorB1 --> LUN 1
initiatorB2 --> LUN 1
initiatorC1 --> LUN 1
initiatorC2 --> LUN 1
initiatorD1 --> LUN 1
initiatorD2 --> LUN 1
That's the main reason that you commonly see all initiators from an ESX cluster in the same igroup. The downside to that, of course, is that you lose some flexability in your LUN mappings.
Also, as a bit of old time VMware advice, I try to not use LUN ID # 0, as ESX tends to use that as a gateway device for special control functions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ok got it. but now I am finding out that not all the luns are using same initiator ID. could this be a problem down the road? Is it ok to change the Lun Id on those intiators while the lune is online?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Administratively having one LUN with different mapped IDs across ESX hosts within a cluster *could* cause issues when dealing with troubleshooting, diagnostics, etc.
For instance, since each ESX host can independently access the LUN, when I've had issues in the past such as locking and we had to dig into the low level logs from multiple hosts, it tended to get very confusing, especially for supporting parties, to keep straight which entry was important on which host. Similarly the most common "mistake" when mistakes occured during unmapping LUNs for whatever reason was to unmap the wrong one from a host. Tools like VSC make this a less likely item to occur when you can use them. Back in the day (think ESX 3) the LUN id was the common mechanism of identifying newly added disks, so creating data stores in the cluster got tricky if the IDs didn't match across the cluster.
Operationally, the LUN id isn't a low level identifier in ESX itself. So long as every ESX host can see all the LUNs needed, ESX is just fine.
My personal preference when using LUNs was to keep primary data stores mapped to the "cluster" igroup so that LUN ids were common across the cluster. Typically these were in the 1-99 range. Special purpose but regularly created LUNs would be set in the 100-199 range - might be mapped to just one or a couple of ESX hosts and generally used for a defined but transient purpose, but were still common across the hosts that had the same LUN. This was manual through individual ESX host igroups. LUN clones were typical in this group.
Then 200-248 were for any other one-off LUN that didn't fit in either of the first two categories and were typically just for one ESX host - snapshots for data recovery, testing, etc.
It was common for me to have 75-125 LUNs mounted across a cluster at any given time, so administratively we needed a system. If you're dealing with a handful, it might be less important administratively.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
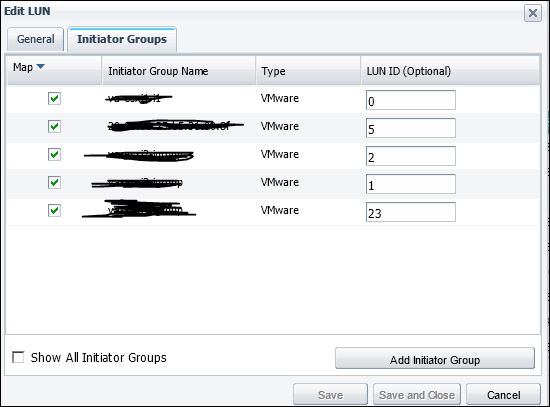
The igroup name from your screenshot can be whatever you want. That's for your tracking purposes. The initiator in the igroup is what's important.
I would not try to change LUN#s without scheduling maintenance. The host will have I/O inflight to that particular I_T_L nexus (that's the SCSI relationship between the initiator/target/LUN).
With ESX, and really most host OSes, you'll want to rescan the affected initiator HBA between each change.
Honestly, it may be easier (and certainly less disruptive) to create new LUNs with consistent mappings and just storage vMotion your VMs onto the new LUN. Once there are no more VMs on your old LUNs, you can follow normal proceedures to decom them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I should say, the requirements for matching LUN IDs may vary based on your software version, which I don't see in the thread. Theoretically it shouldn't matter if you are on ESXi 5.5 or higher.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am on 5.1 U2.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Still a bit confused. If an RDM is to be mapped to Windows VM (2008R2). I am not using snapdrive.
should i use vmware or windows protocol?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So, yeah. 5.1x does require all RDMs to be mapped to the same LUN # on all hosts in the VMware cluster. Otherwise vmotion and failover won't work.
My advice: Do what Bob said. Create one new igroup for all initiators in the ESXi cluster.
Now, the question becomes, how do you get there from here?
There's a million ways to do it, but for RDMs you basically are going to have to schedule maintenance so that you can unmap and remap the LUNs if you want to keep them.
The other problem is that you have the wrong multiprotocol type for your LUN. Since this is Windows 2008 you need to use the Windows_2008 LUN type, not the Windows type (confusing, I know).
So... Maybe you need to look at creating a new LUN of the correct type, mapping it to your ESXi cluster, adding it to your Windows VM, and then copying the data from your old LUN to your new LUN using the guest OS (robocopy?).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ok thanks. but still if its RDM, is there a big different in using say vmware vs windows 2008 vs windows protocol if I do not plan to use snapdrive inside the GOS.
why not use vmware instead?
thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Terminology first. You are concerned about the LUN "ostype", not protocol. Protocol for block is either iSCSI or Fibre Channel. I mention this for clarity for everyone reading.
Both LUNs and igroups have a "ostype". The "ostype" value is tied to the controlling Operating System and adjusts certain behaviors and settings that are unique to the Operating System. That's why the "ostype" exists.
For igroups, the "ostype" controls behaviors associated with how the controlling OS talks over the wire - either iSCSI or Fibre Channel - using the SCSI-2/3 command set. For LUNs, the ostype controls behaviors associated with how the controlling OS reads and writes data to the logical "disk". For instance, a LUN with an "ostype" of "windows" will trigger the NetApp controller to fake the starting offset to get better partition alignment for better performance, whereas an "ostype" of "windows_2008" won't do that because W2k8 changed the default alignment. So the LUN "ostype" is all about the contents, while the igroup "ostype" is about the wire protocol. In general of course.
Typically, the "ostype" for both LUN and igroup are essentially the same or within the same family - for instance an igroup of ostype "windows" and a LUN of ostype "windows_2008" are within the same family. Natural of course because typically the controlling server is the same for both the igroup and the LUN.
In virtualization, you introduce the possibility that the controlling server is different between the igroup and the LUN. With RDMs, ESX acts as a pass through. That is, the ESX host takes the read/write request from the Guest OS and puts it out on the wire essentially as is (there are a couple of exceptions, of course). So - what you have is ESX (VMWare) controlling the "wire" (igroup) while the Guest OS controls the contents of the disk (LUN). So for an RDM that is mounted to a Windows guest, the igroup should be of ostype "vmware" and the LUN should be of ostype "windows" (or one of the other ostypes in the windows family as appropriate like "windows_2008").
Bonus question - if you are not using SnapDrive, why use an RDM at all in this example? Do you have some other need to snapshot this LUN independently of ESX control at the NetApp level? Need to take NetApp FlexClones for some reason? If not, why RDM at all? It does introduce a level of complexity but shouldn't be done just because. If it was done for "performance" I'll say it is a common misconception that RDMs are, in general, faster. In most cases you can't get a difference in performance, since you still go through both the guest OS kernel and the ESX kernel to process any disk request. Of course there are rare exceptions, but RDMs are primarily for when you need advanced "native" storage capabilities.
Bob Greenwald
Lead Storage Engineer, Huron Legal
Huron Consulting Group
NCDA | NCIE-SAN Clustered Data OnTap


{kind=link}
{kind=link}