ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: CFOD not initiated, but why?
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm just running some final test with TB 2.1.1 and OCUM 5.2, but can't figure out what went wrong. I shutdown ProblemFiler2 and after some timeouts TB says that ProblemFiler1 has been too long in degraded status and disables itself. I have another MC/TB configuration where everyting is done right on same kind of hardware fail.
2013-08-27 16:19:10,180 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:19:10,180 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:19:10,180 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:19:10,190 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status CONNECTED, Enabled: true, IC: true
2013-08-27 16:19:10,190 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:19:10,210 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler2: cf-status CONNECTED, Enabled: true, IC: true
2013-08-27 16:19:10,210 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking interconnects
2013-08-27 16:19:10,210 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:19:10,210 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:19:10,240 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:19:10,240 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:19:10,240 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirrored
2013-08-27 16:19:10,240 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirrored
2013-08-27 16:19:10,240 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:19:10,240 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:19:10,270 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler2 loading aggregate mirror status
2013-08-27 16:19:10,270 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirrored
2013-08-27 16:19:10,270 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas2: mirrored
2013-08-27 16:19:10,270 [ProblemFiler1-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.10:80
2013-08-27 16:19:10,270 [ProblemFiler1-conn-3] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.10:445
2013-08-27 16:19:10,270 [ProblemFiler1-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.10:80
2013-08-27 16:19:10,270 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:19:10,290 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler2: vol0
2013-08-27 16:19:10,290 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:19:10,310 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:19:10,320 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler2: aggr0
2013-08-27 16:19:10,320 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler1
2013-08-27 16:19:10,320 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:19:10,320 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: CONNECTED
2013-08-27 16:19:10,320 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: true
2013-08-27 16:19:10,320 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: false
2013-08-27 16:19:10,330 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:19:10,330 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:19:10,330 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:19:10,340 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:19:10,340 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:19:10,360 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: CONNECTED
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: true
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: false
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:19:10,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler2
2013-08-27 16:19:20,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:19:20,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:19:20,370 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:19:20,380 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status TAKEOVER_STARTED, Enabled: true, IC: false
2013-08-27 16:19:20,380 [MetroCluster1-monitor] WARN com.netapp.rre.anegada.Monitor - ProblemFiler1 in a take-over state, skipping remaining checks.
2013-08-27 16:19:30,390 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:19:30,390 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:19:30,390 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:19:30,400 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status TAKEOVER_STARTED, Enabled: true, IC: false
2013-08-27 16:19:30,400 [MetroCluster1-monitor] WARN com.netapp.rre.anegada.Monitor - ProblemFiler1 in a take-over state, skipping remaining checks.
2013-08-27 16:19:40,399 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:19:40,399 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:19:40,399 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:19:40,409 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status TAKEOVER_STARTED, Enabled: true, IC: false
2013-08-27 16:19:40,409 [MetroCluster1-monitor] WARN com.netapp.rre.anegada.Monitor - ProblemFiler1 in a take-over state, skipping remaining checks.
2013-08-27 16:19:50,409 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:19:50,409 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:19:50,409 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:19:50,419 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:19:50,419 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:19:55,439 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:19:55,439 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:19:55,439 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:19:55,489 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:19:55,489 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:19:55,489 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:19:55,489 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:19:55,489 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:19:55,489 [ProblemFiler2-conn-3] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:445
2013-08-27 16:19:55,489 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:19:55,489 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:19:55,509 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:19:55,509 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:19:55,529 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:19:55,539 [MetroCluster1-monitor] WARN com.netapp.rre.bautils.DfmCommand - DFM_EVENT MetroCluster-TieBreaker:Degradation-Event:Mirror-Degradation, source: ProblemFiler1: Mirror degradations have been detected on filer ProblemFiler1
2013-08-27 16:19:55,539 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.DfmCommand - Executing: dfm event generate MetroCluster-TieBreaker:Degradation-Event:Mirror-Degradation ProblemFiler1 Mirror degradations have been detected on filer ProblemFiler1
2013-08-27 16:20:06,558 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:20:06,558 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:20:06,558 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:06,568 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:20:06,568 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:11,568 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:20:11,568 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:20:11,568 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:20:11,588 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:20:11,588 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:20:11,588 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:20:11,588 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:20:11,588 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:20:11,588 [ProblemFiler2-conn-3] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:445
2013-08-27 16:20:11,598 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:20:11,598 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:20:11,608 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:20:11,608 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:20:11,628 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:20:11,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:20:21,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:20:21,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:20:21,648 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:21,658 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:20:21,658 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:26,667 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:20:26,667 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:20:26,667 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:20:26,687 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:20:26,697 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:20:26,697 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:20:26,697 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:20:26,697 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:20:26,697 [ProblemFiler2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:2049
2013-08-27 16:20:26,697 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:20:26,697 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:20:26,717 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:20:26,717 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:20:26,737 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:20:26,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:20:36,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:20:36,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:20:36,757 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:36,767 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:20:36,767 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:41,767 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:20:41,767 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:20:41,767 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:20:41,787 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:20:41,787 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:20:41,787 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:20:41,787 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:20:41,797 [ProblemFiler2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:2049
2013-08-27 16:20:41,797 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:20:41,797 [ProblemFiler2-conn-3] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:445
2013-08-27 16:20:41,797 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:20:41,797 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:20:41,807 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:20:41,807 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:20:41,827 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:20:41,847 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:20:51,846 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:20:51,846 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:20:51,846 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:51,856 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:20:51,856 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:20:56,866 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:20:56,866 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:20:56,866 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:20:56,896 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:20:56,896 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:20:56,896 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:20:56,896 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:20:56,896 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:20:56,896 [ProblemFiler2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:2049
2013-08-27 16:20:56,896 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:20:56,896 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:20:56,916 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:20:56,916 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:20:56,936 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:20:56,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:21:06,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:21:06,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:21:06,946 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:21:06,956 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:21:06,956 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:21:11,966 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:21:11,966 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:21:11,966 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:21:11,986 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:21:11,996 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:21:11,996 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:21:11,996 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:21:11,996 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:21:11,996 [ProblemFiler2-conn-3] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:445
2013-08-27 16:21:11,996 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:21:11,996 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:21:12,006 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:21:12,006 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:21:12,026 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:21:12,046 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:21:22,045 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:21:22,045 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:21:22,045 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:21:22,055 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:21:22,055 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:21:27,065 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:21:27,065 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:21:27,065 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:21:27,085 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:21:27,085 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:21:27,085 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:21:27,085 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:21:27,085 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:21:27,085 [ProblemFiler2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:2049
2013-08-27 16:21:27,095 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:21:27,095 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:21:27,105 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:21:27,105 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:21:27,125 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:21:27,145 [MetroCluster1-monitor] WARN com.netapp.rre.bautils.DfmCommand - DFM_EVENT MetroCluster-TieBreaker:Degradation-Event:Threshold-Exceeded, source: ProblemFiler1: Automatic CFOD disabled due to mirror degredation threshold (cfodAbortTimeout: 90000) exceeded on filer ProblemFiler1
2013-08-27 16:21:27,145 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.DfmCommand - Executing: dfm event generate MetroCluster-TieBreaker:Degradation-Event:Threshold-Exceeded ProblemFiler1 Automatic CFOD disabled due to mirror degredation threshold (cfodAbortTimeout: 90000) exceeded on filer ProblemFiler1
2013-08-27 16:21:38,014 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:21:38,014 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:21:38,014 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:21:38,024 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:21:38,024 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:21:43,024 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
2013-08-27 16:21:43,024 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Getting aggr status for ProblemFiler1
2013-08-27 16:21:43,024 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.aggr.AggrListInfoRequest
2013-08-27 16:21:43,054 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 loading aggregate mirror status
2013-08-27 16:21:43,054 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sata1: unmirrored (ignored)
2013-08-27 16:21:43,054 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-08-27 16:21:43,054 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr_sas1: mirror degraded
2013-08-27 16:21:43,054 [ProblemFiler2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:2049
2013-08-27 16:21:43,054 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:21:43,054 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
2013-08-27 16:21:43,054 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
2013-08-27 16:21:43,074 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root volume for ProblemFiler1: vol0
2013-08-27 16:21:43,074 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeListInfoRequest
2013-08-27 16:21:43,084 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeContainerRequest
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - Found root aggr for ProblemFiler1: aggr0
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking CFOD for filer ProblemFiler2
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - reachable: true
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - survivor CF state: ERROR
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Survivor IC: false
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Root Aggr Mirror Degraded: true
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking mirror degradation on filer ProblemFiler1
2013-08-27 16:21:43,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1 aggregate aggr_sas1 mirror degraded
2013-08-27 16:21:53,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Checking site reachability
2013-08-27 16:21:53,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Monitor - Updating filer status
2013-08-27 16:21:53,104 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
2013-08-27 16:21:53,114 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - ProblemFiler1: cf-status ERROR, Enabled: true, IC: false
2013-08-27 16:21:53,114 [MetroCluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.cf.CfStatusRequest
//KK
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi KK,
It's not possible to share the source code. However, I can explain the algorithm, if that will help.
- Each of the 3 ports configured is handled in separate thread tasks in such a way that if any of the threads successfully connects to the target and completes, the other threads are canceled (this is handled by java.util.concurrent.ExecutorService.invokeAny()).
- Each thread task invokes java.nio.channels.SocketChannel.open() to create a channel, calls channel.configureBlocking(true), then calls channel.connect(new InetSocketAddress(addr, port));. In blocking mode, connect() will either succeed or throw an exception. If the call succeeds, the connection test completes successfully. If any exception is thrown, it is reported and the connection test fails
- Immediately before the SocketChannel.open() call is the following debug line, which produces the log message you are seeing: debug("Opening connection to: " + addr.getHostAddress() + ":" + port);
- Immediately after the connect() call, and only reachable if there is no exception, is the following line, which also produces the log message you are seeing: debug("Successful connect to: " + addr.getHostAddress() + ":" + port);
The only way the the "Successful connect to: ..." message you are seeing in the logs can be produced is if the SocketChannel connect() call succeeds. You can see the same InetAddress (addr) and port number (port) are used in the connect call and are reported by the logging statements.
This code has been thoroughly tested, and is running successfully in many installations all over the world. Many of those have experienced successful MCTB initiated CFOD events.
Have you tried using Wireshark or another network packet tracer, installed on the MCTB host, and looked at the actual connection attempts? Also, what OS is MCTB running on?
Brian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi KK,
Do you have a "mctb.properties" file in the MCTB installation or configuration directory? If so, can you report what it contains? Also, does the log file, or any past log file contain the most recent startup log entries (I'm looking for the initial connection to the controllers, which has a log entry that begins with "Connected to").
The reason MCTB never issued the CFOD was because ProblemFiler2 continued to be reachable via TCP connect all the way until cfodAbortTimeout was exceeded (see the cfodAbortTimeout configuration parameter description in the Admin Guide):
2013-08-27 16:21:27,085 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:80
2013-08-27 16:21:27,085 [ProblemFiler2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.11:2049
2013-08-27 16:21:27,095 [ProblemFiler2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.11:80
Is it possible that the two controller IP addresses are switched in the MCTB configuration file? I've done that before and had similar behaviors.
Another log entry shows an extremely small timeout for API communications:
2013-08-27 16:21:27,065 [MetroCluster1-monitor] ERROR com.netapp.rre.anegada.Filer - ProblemFiler2: ApiTimeoutException on com.netapp.ontap.api.cf.CfStatusRequest: ZAPI call cf-status to 10.10.10.11 timed out after 0:00:05.000
The API timeout should be on the order of 90 seconds, not 5, so I'm curious about that (although this wouldn't have caused MCTB to fail to issue a CFOD).
Thanks,
Brian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
There is not "mctb.properties" file. What this file should contain?
I have double checked IP addresses and everything seems to be in order. We where wondering if there is some router, intruder dectection system or some other network equipment to fool MCTB to think that TCP port is answering. We can't be sure, but it's unlikely.
Also I'm wondering why MCTB documentation doesn't mention anything about connection tests into TCP ports 80,445 and 2049.
I don't know how to set timeout for API calls. I try to adjust all other timeouts in my test MCTB, but without any effect. It's stays on 10 sec, not in 5 sec like in production MCTB. So I don't have any clue why production MCTB is using 5 sec timeout.
I can create new TB by myself using Python, but first I have to completly test if Netapp MCTB is usable or not
Thanks for you help,
KK
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just downloaded the 2.1.1 installation package and installed it from scratch, and it indeed had the incorrect timeout values. I'm not sure what happened, but I think a previous revision somehow became current. I have uploaded the correct installation packages for both Windows and Linux. I downloaded and installed the new package and confirmed that it has the correct timeout values. I recommend you download a fresh copy from the Community and reinstall to get the correct API timeout values. I apologize for the inconvenience. The values in the Connected to log message should confirm timeout values of 60000 and 60000:
2013-08-29 13:16:41,597 [MetroCluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - MCController1: Connecting using 10.61.166.216, connTimeout: 60000, readTimeout: 60000
The mctb.properties file is optional, and provides a way to override some internal configuration values. including the API read and connect timeouts.
I apologize for the lack of detail in the documentation on the TCP connect test. As you can see in the log file, the controller reachability test is performed by attempting to connect, in parallel, on the TCP ports for HTTP (80), CIFS (445) and NFS (2049). If any one of those TCP ports responds, the controller is considered reachable (and CFOD will not be issued).
I don't know why the port on that address continued to be reachable even after the controller was halted.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I did fresh install with fixed version and now TB is working as expected. Great!!!
But there is still one problem after server reboot. MCTB service is set for Delayed Start and I can see that service is running after reboot, but MCTB doesn't start to insert any entrys into log file. I have now been waiting about 10 minutes for automatic start but nothing happened. Documentation actually doesn't say that MCTB is able to start automaticly after server reboot. Is it planned to start automatically?
I also rebooted server two times and every time MCTB logs proper lines like "Stop called, terminating", but nothing about starting.
---edit---
I did more reboot tests and MCTB is not starting propelly. I even did script whitch run command "c:\<path to bins>\dfm.exe script job start -p start -j autostart 450" after server reboot, but only MCTB service is started, but nothing is logged. 450 is object id of TieBreaker script. Also job status appears in DFM job status list with Success status.
But... If run Stop command while service is running (but not nothing shown in log file) and after that rerun start job MCTB may start..or not
//KK
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Make sure to rerun the "install" script command. Even though the service exists, it appears to be stale if you download and install the plugin again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm testing MCTB with my test environmenr and here is steps I did:
- Run UNINSTALL command and removed old broken MCTB. Also I checked that all files are deleted from script-plugin directory.
- Installed new version. Run INSTALL and RUN commands. MCTB starts to enter entrys into log. Everything ok.
- 1st server reboot. Everything ok.
- 2nd server reboot. Service running, but not new entrys in log. Running START results "An instance of the service is already running.". After STOP and RUN commands MCTB starts to enter entrys into log.
- 3rd to 9th server reboot. Everyting ok.
- 10th server reboot. Service running, but no entrys in log. Running STATUS results "STATE RUNNING". Running START results "An instance of the service is already running.". After STOP and RUN commands MCTB starts to enter entrys into log.
- 10th server reboot. Everything ok.
- 11th to 15th server reboot. Everything ok.
- 15th server reboot. Service running. Restarting MCTB service starts MCTB to enter entrys into log.
- 16th to 18th server reboot.
- 19th server reboot. Same procedure like on step 4.
So I rebooted server 20 times and MCTB won't start 4 times. Not so good
Is there anyway to get more debug data from MCTB?
//KK
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi KK,
If you are using Windows, make sure the MCTB service startup is set to "Automatic (Delayed)". Apparently, Windows has some internal dependencies (networking, I believe), that require delayed start for some services.
Brian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I have used delayed start all in my tests. Do you know any way get more debug information for this problem?
//KK
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There should be stdin and stdout logfiles from the service wrapper that runs MCTB (mctb-stdin-yyyy-mm-dd.log, etc.). There might be some information there. I'm not sure if there is a way to get more detailed logging on service startup from Windows, You might check the various Windows event logs and see if anything is being reported.
The service wrapper (mctb.exe) is the Apache Daemon wrapper that Tomcat uses (http://commons.apache.org/proper/commons-daemon/procrun.html), which is very stable. I did find this http://stackoverflow.com/questions/11632275/apache-procrun-fails-to-start-service, but the version of log4j being used in MCTB is 1.2.15, and has been that version for over a year now. None of the other jars mentioned in that article are in use by MCTB, so I don't think that is the same issue.
You might try manually uninstalling and reinstalling the Windows service (remember to manually reset startup to "Automatic (Delayed)"). The instserv.bat script can do this from the command line:
.\instserv.bat uninstall
.\instserv.bat install
Unfortunately, if the mctb.exe process is running and has opened the log file, but isn't producing any log entries, something has probably happened during service startup. The only time I've seen this behavior is when startup is set to Automatic without the delayed start.
Sorry I don't have a better answer for you. Of course, let me know if you find anything in the logs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I run more tests at customer site and find out that tiebreaker is not working as expected. Here is short version what happened:
- 12:47:xx,xxx filer2 is shutdown
- 12:46:50,640 First time when tiebreaker notices that filer2 is not ok
- 12:47:32,932 filer1 is ok and all aggregates are in degraded mode as expected
- 12:47:32,932 How tiebreaker can connect to port 80 on filer2 even it's shutdown?
- 12:47:32,963 Tiebreaker sends event to OCUM about filer1 aggregate degration
- 12:48:27,157 Tiebreaker can't connect to filer2
- 12:48:27,391 Tiebreaker is still connecting to filer2 port 80
- 12:49:19,542 Tiebreaker says that filer1's aggregates have been too long in degraded mode and disables Tiebreaker
So tiebreaker should start CFO between 12:46:50,640 and 12:49:19,542, but nothing happened. Config.xml, full tiebreaker log and filer1 console log as attachments.
I have only these explanations:
- Filer1 have to settle down and tiebreaker's CFODABORTTIMEOUT value 90 sec is not long enought.
- Filer ip addresses can't be mixed because in config file filer2's ip is 10.10.10.202. Also from tiebreaker log I can found api call error for filer2 and same time filer1 is functioning ok. One possible reason is bug in tiebreaker and it some how mixes IP-addresses internaly. Second possible reason is some kind of network device that replies to tiebreaker when it's trying to connect port 80, but according admins there is not any.
How I can see why tiebreakers doesn't start CFO?
Should I increase value of CFODABORTTIMEOUT to 150 sec?
Can I disable port 80 test from tiebreaker?
Thanks in advance.
//KK
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi KK,
As long as MCTB can connect to a port on a storage system, it will not issue CFOD, so the core of the problem is that 10.10.10.202 is still responding to connect requests on port 80. As long as that happens, MCTB will not take action. I did notice some strange logging in the filer1 console output. Apparently, filer1 is attempting to take over filer2 at the same time that takeover is disabled because of the IC failure:
Wed Oct 30 12:46:50 EET [filer1:cf.fsm.takeoverByPartnerDisabled:notice]: Failover monitor: takeover of filer1 by filer2 disabled (interconnect error).
Wed Oct 30 12:46:50 EET [filer1:cf.fsm.stateTransit:info]: Failover monitor: UP --> TAKEOVER
Wed Oct 30 12:46:50 EET [filer1:cf.fm.takeoverStarted:notice]: Failover monitor: takeover started
I've never seen that behavior before, but I believe that could be the issue. If filer1 has started servicing requests on 10.10.10.202 due to a takeover attempt, that would explain why port 80 is accepting connections (it's actually filer1 responding on filer2's address). I don't know how ONTAP handles the situation above, so I don't know whether this is indeed the case or not.
There is further evidence that the takeover was attempted later in the log:
Wed Oct 30 12:47:21 EET [filer1:cf.fm.takeoverFailed:error]: Failover monitor: takeover failed 'filer1_11:53:54_2013:09:19'
Wed Oct 30 12:47:21 EET [filer1:cf.fm.givebackStarted:notice]: Failover monitor: giveback started.
It would seem likely that after the giveback completed and filer1 reports CF status ERROR (at 12:47:45 in the mctb log), it would no longer be responding on 10.10.10.202:80 (if that was indeed what was happening). Yet, MCTB was able to connect at 12:48:27 (also in the mctb log). I can't really explain why MCTB is able to connect on 10.10.10.202:80, but as long as it can it will refuse to issue CFOD.
It doesn't really matter how long cfodAbortTimeout is set to; as long as MCTB can connect to filer2 it will not issue the CFOD, and eventually cfodAbortTimeout will be exceeded. We can see connections succeeding through out the log, as late as 12:51:57.
The core problem is that 10.10.10.202 is still responding to TCP connect requests on port 80. I can't explain why that is happening. But, all other behaviors you are seeing in MCTB are as expected given that the TCP connects are succeeding. I don't know whether it has anything to do with the other behaviors you are seeing on filer1 or not.
It is very important that both the storage systems in the MetroCluster and the MCTB host be time synchronized to the same NTP server. This will ensure that the timestamps in the logs on the controller and in MCTB are accurate. It can be very confusing when the times are not synchronized. I don't believe that is an issue here, but it's something I wanted to point out.
All I can suggest is shutting down filer2 again and trying TCP connects to it's address (using the telnet command or even a browser), and trying to isolate where the responses are coming from.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I visited customer once again and we did more tests. First we checked that all filers and servers are using same time server. 10:27 I shutdown filer2 and once again tiebreaker started logging that connection to filer2 port 80 was successful. This time we had monitoring software monitoring filer's ICMP ja HTTP ports every 10 seconds.
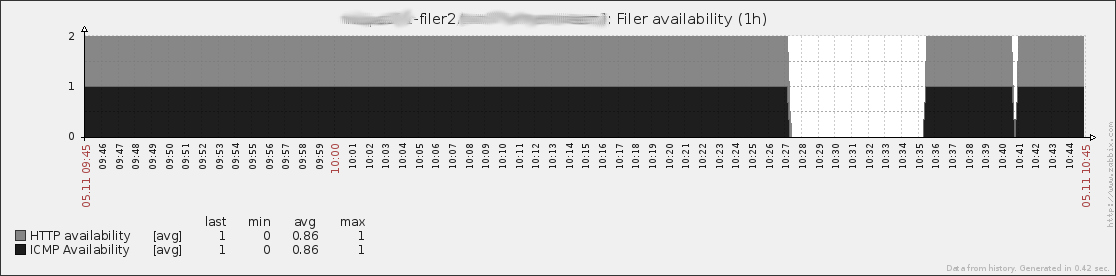
From picture you can see that port HTTP/80 is not responding after shutdown. Do you have new suggestions? If there is any way to disable port 80 test I will be very happy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Was the TCP port 80 monitoring done from the same host MCTB is running on? During the filer down time, can you connect on port 80 from the host running MCTB? I cannot reproduce this behavior in my lab,and none of our other customers have reported this (and many have had successful failovers initiated by MCTB).
You can't disable the port tests, but you can change the port they use. Create a file named "mctb.properties" in the MetroCluster-TieBreaker directory under script-plugins with the following line:
WEB_PORT=11111
Choose a number for WEB_PORT that you know is not available on the filer. That will cause that connection attempt to fail with Connection Refused (although that error may not be logged if one of the other ports responses quickly enough).
Here are example log messages, with all three test ports set to 11111 (the other ports are CIFS_PORT and NFS_PORT):
2013-11-06 07:43:54,370 [2050rreAlpha2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.61.166
.217:11111
2013-11-06 07:43:54,370 [2050rreAlpha2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.61.166
.217:11111
2013-11-06 07:43:54,370 [2050rreAlpha2-conn-3] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.61.166
.217:11111
2013-11-06 07:43:55,399 [2050rreAlpha2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Connection refused: connect atte
mpting to connect to 10.61.166.217:11111
2013-11-06 07:43:55,399 [2050rreAlpha2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Connection refused: connect atte
mpting to connect to 10.61.166.217:11111
2013-11-06 07:43:55,399 [2050rreAlpha2-conn-3] DEBUG com.netapp.rre.bautils.NetUtils - Connection refused: connect atte
mpting to connect to 10.61.166.217:11111
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
During downtime I used telnet and ping to test connectivity from same machine where OCUM and Tiebreaker are running. Filer1 answered to ping and filer2 not. Using telnet to port 80 filer1 answered with http protocol messages. When connecting to filer2's port 80 screen whent black with no any kind of answer.
I don't know technical detail about monitoring server's network location, but I can trust that test was configured properly.
Hmmm. I didn't see "Connection refused" messages at all. I can only see two "Opening connection" messages and one "Successful connect" for port 80. Not "Connection refused" messages newer shown.
2013-10-30 12:51:57,102 [filer-metrocluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - filer1 loading aggregate mirror status
2013-10-30 12:51:57,102 [filer-metrocluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr1: mirror degraded
2013-10-30 12:51:57,102 [filer-metrocluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr2: unmirrored (ignored)
2013-10-30 12:51:57,102 [filer-metrocluster1-monitor] DEBUG com.netapp.rre.anegada.Filer - aggr0: mirror degraded
2013-10-30 12:51:57,102 [filer2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.202:80
2013-10-30 12:51:57,102 [filer2-conn-2] DEBUG com.netapp.rre.bautils.NetUtils - Opening connection to: 10.10.10.202:2049
2013-10-30 12:51:57,102 [filer2-conn-1] DEBUG com.netapp.rre.bautils.NetUtils - Successful connect to: 10.10.10.202:80
2013-10-30 12:51:57,102 [filer-metrocluster1-monitor] DEBUG com.netapp.rre.bautils.ZapiExecutor - Executing ZAPI: com.netapp.ontap.api.volume.VolumeGetRootNameRequest
Is it still possible that my copy of tiebreaker is faulty?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is possible you are not running the latest version of MCTB. Make sure you are running version 2.1.1. You can download and install the new version from the Community site. Save a copy of "config.xml" before you do the installation to save you having to enter the configuration again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is it possible to see source code?
//KK
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi KK,
It's not possible to share the source code. However, I can explain the algorithm, if that will help.
- Each of the 3 ports configured is handled in separate thread tasks in such a way that if any of the threads successfully connects to the target and completes, the other threads are canceled (this is handled by java.util.concurrent.ExecutorService.invokeAny()).
- Each thread task invokes java.nio.channels.SocketChannel.open() to create a channel, calls channel.configureBlocking(true), then calls channel.connect(new InetSocketAddress(addr, port));. In blocking mode, connect() will either succeed or throw an exception. If the call succeeds, the connection test completes successfully. If any exception is thrown, it is reported and the connection test fails
- Immediately before the SocketChannel.open() call is the following debug line, which produces the log message you are seeing: debug("Opening connection to: " + addr.getHostAddress() + ":" + port);
- Immediately after the connect() call, and only reachable if there is no exception, is the following line, which also produces the log message you are seeing: debug("Successful connect to: " + addr.getHostAddress() + ":" + port);
The only way the the "Successful connect to: ..." message you are seeing in the logs can be produced is if the SocketChannel connect() call succeeds. You can see the same InetAddress (addr) and port number (port) are used in the connect call and are reported by the logging statements.
This code has been thoroughly tested, and is running successfully in many installations all over the world. Many of those have experienced successful MCTB initiated CFOD events.
Have you tried using Wireshark or another network packet tracer, installed on the MCTB host, and looked at the actual connection attempts? Also, what OS is MCTB running on?
Brian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
We found finally a root cause for his problem. All this hassle was caused by TrendMicro OfficeScan. It's filtering URL's and acts as some kind of HTTP proxy in our OCUM server. I don't know what OfficeScan admins did, but now filering rules are disabled and all tiebreakers are working.
http://esupport.trendmicro.com/solution/en-us/1058127.aspx
I only litle bit worryed worried when OCUM server is rebootted. Some times MCTB service is running, but not adding anything to logs. Running stop and start commands will fix problem.
//KK
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi KK,
That's excellent news! I'm glad this very puzzling problem has been resolved. I have not seen any problems with MCTB starting when the service start up is "Automatic (Delayed)". You might try uninstalling and reinstalling the service (or all of MCTB) to see if that cleans up the service definition. Also check that the account the MCTB service is using has all the necessary privileges. You might try administrator, even if just temporarily, to see if that helps.
Brian
