This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: Looking for feedback on my design
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good morning all, this is my first post here, and I'm hoping to seek a bit of guidance on my design.
I have, in my data center right now
4: HP DL370G7 hosts with two X5660's, 60gb of RAM and 12 NICS (8 being IntelVT)
1: FAS2040 loaded with 450gb 15k SAS disks (Windows software bundle if I remember correctly)
1: FAS2020 loaded with 2TB SATA disks (Everything needed to be a Snap* target)
4: Cisco 3750G switches
1: VMWare Enterprise licensing for the lot of it
My intention is to turn the above into what should essentially be a reference VMWare\NetApp infrastructure, with redundant everything.
For the network, I’ll be using 2 of the switches stacked for production\management traffic, and two stacked, set to jumbo frames, and used as an isolated storage network. I’ve drafted a design for the storage network based on the “VMWare on NetApp storage Best Practices***” guide, and thankfully I have some actual CC** types that are going to handle the config of those.
Three of the hosts will reside at our HQ, along with those switches and the FAS2040. One host and the FAS2020 will be at a remote office and will be used as a backup\DR infrastructure. I plan to establish it as a Snapmirror target, and replicate pretty much everything to it (it does have 24TB raw).
I know that’s a really brief description with a lot of detail left out, but it brings me to my questions. I’ve managed and been on the deployment of a few older FAS270 and R200 devices (~5-6 years ago), and I have a decent understanding of the concepts and admin of NetApp storage (when everything but filerview seemed to be CLI), but I haven’t actually set up or administered any modern NetApp device.
I would LOVE to set this infrastructure up myself, and I’m hoping that between the community and documentation on the NOW site I can do so. Everyone I’m talking to insists that you need to drop 10-20k on consulting to bring a few NetApp FAS' up, I’m hoping that isn’t the case.
What I want to configure on the 2040 is this:
2 Disks set to RAID4 to be used as the System Aggregate
10 Remaining disks set to RAID-DP as the Production-Storage Aggregate (all NFS FlexVOLs Deduped)
Out of this Prod-Storage Aggregate I would like to create the following:
NFS FlexVol for Production VM Datastore
NFS FlexVol for Development VM Datastore
NFS FlexVol for VM Pagefiles (No Snapshots)
NFS FlexVol for VSWAP files (No Snapshots)
CIFS FlexVol for File shares
iSCSI LUN for SQL DBs
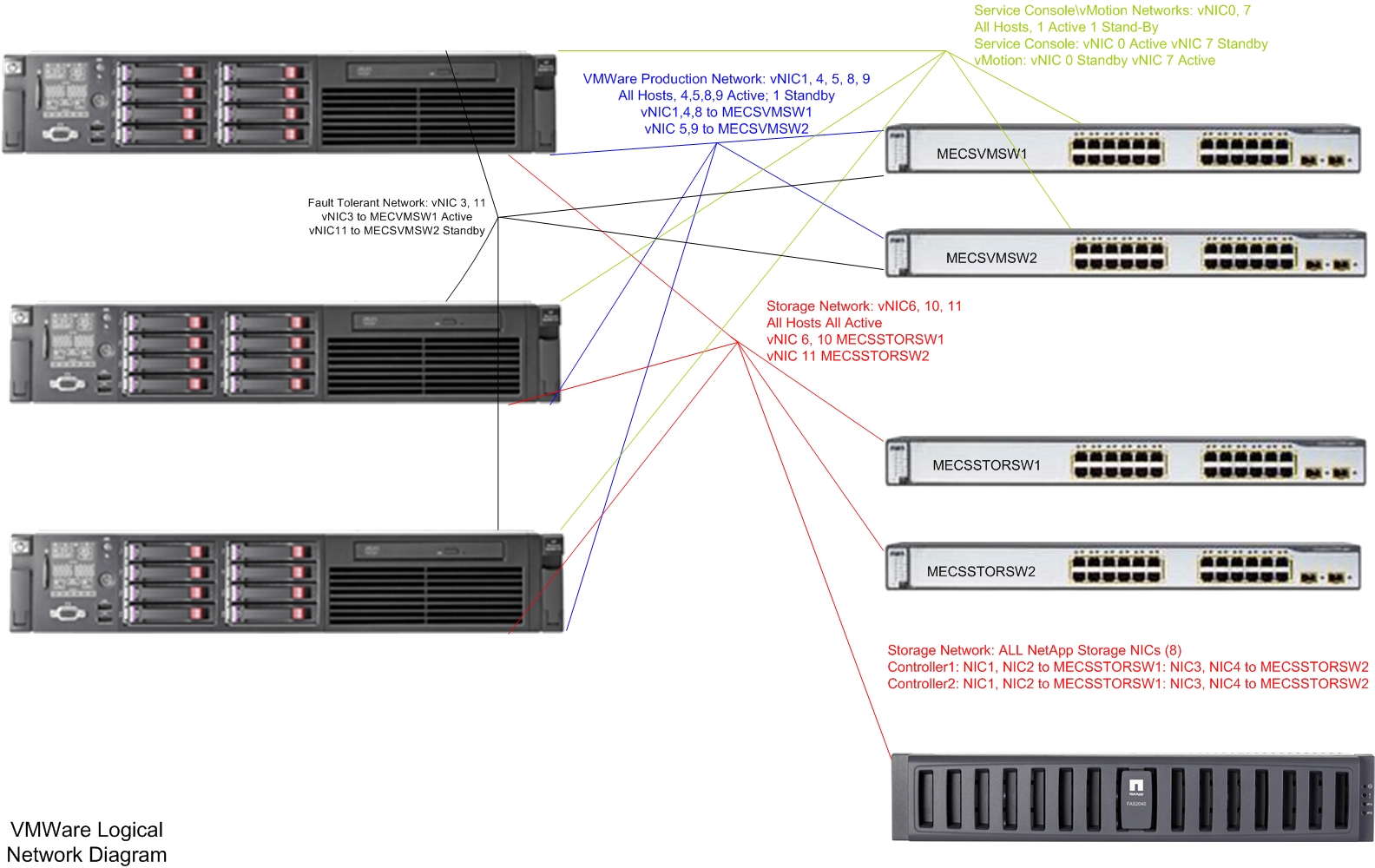
So, am I insane for attempting to create the above myself? Or has everything on the newer FAS' really become wizard and menu driven enough that I should be able to tackle it with a bit of guidance? The attached sketch is a bit simplistic but it gives a rough idea of how everything will be connected.
Sorry for the uber long winded post as my first, and thanks in advance for any feedback.
Peace
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> Good morning all, this is my first post here, and I'm hoping to seek a bit of guidance on my design.
Minus the DR stuff, your design is remarkably similar to one I rolled out at my company two years ago. 🙂
The specific models are different - e.g. we are using IBM servers, HP switches and a FAS2050 - but the "entry level fully redundant" concept, implementation of this idea, and selection of hardware to do it is almost identical.
I'm far from a NetApp expert, but based on my experience over the past few years, a couple of comments:
> I have, in my data center right now:
> 1: FAS2040 loaded with 450gb 15k SAS disks (Windows software bundle if I remember correctly)
Is your FAS2040 single or dual controller? If the former, that's one big weak spot in your design / goal of having redundant everything - single point of failure at the SAN.
Also, any idea how much disk I/O your VMware farm is going to produce? You don't get a lot of spindles in a base 2040, so you may run into performance issues. I'm not saying you will have issues - our 3 server / 30 VM farm runs just fine off 17 spindles in the 2050 - but you may, depending on the I/O that you generate.
> For the network, I’ll be using 2 of the switches stacked for production\management traffic, and two stacked, set to jumbo frames, and used as an isolated storage network. I’ve drafted a design for the storage network based on the “VMWare on NetApp storage Best Practices***” guide, and thankfully I have some actual CC** types that are going to handle the config of those.
Had a quick glance and the network design looks good to me - and again, pretty closely mimics what we implemented.
> 2 Disks set to RAID4 to be used as the System Aggregate
> 10 Remaining disks set to RAID-DP as the Production-Storage Aggregate (all NFS FlexVOLs Deduped)
I know it is technically best practice to have a dedicated system aggregate, but it wastes too much space on a very small system like your 2040 or our 2050. You only have 12 disks to work with, and with your current design you're losing four of them to parity and your system aggregate.
I'd scrap the system aggr and just create a single 12-disk RAID-DP aggr (or perhaps 11-disk + 1 spare), and use that to host both vol0 and your production vols. This is what we did with our 2050 (although we also had to dedicate some disks to the second controller, which is unavoidable).
> NFS FlexVol for Production VM Datastore
> NFS FlexVol for Development VM Datastore
> NFS FlexVol for VM Pagefiles (No Snapshots)
> NFS FlexVol for VSWAP files (No Snapshots)
Very similar to what we did - although instead of using Prod / Dev datastores, we created our datastores based around the type of data they store (OS, temp/transient, apps, data, etc).
Good choice going with NFS too, it is very flexible and simple.
> iSCSI LUN for SQL DBs
Any particular reason you're using iSCSI for SQL DBs and NFS for the rest? We just used NFS for the lot.
> I’ve managed and been on the deployment of a few older FAS270 and R200 devices (~5-6 years ago), and I have a decent understanding of the concepts and admin of NetApp storage (when everything but filerview seemed to be CLI), but I haven’t actually set up or administered any modern NetApp device.
> I would LOVE to set this infrastructure up myself, and I’m hoping that between the community and documentation on the NOW site I can do so. Everyone I’m talking to insists that you need to drop 10-20k on consulting to bring a few NetApp FAS' up, I’m hoping that isn’t the case.
...
> So, am I insane for attempting to create the above myself? Or has everything on the newer FAS' really become wizard and menu driven enough that I should be able to tackle it with a bit of guidance? The attached sketch is a bit simplistic but it gives a rough idea of how everything will be connected.
Insane? No 🙂 But whether it's a good idea of not does depend on how quickly the new infrastructure is needed, how much time you have, how interested your are, how quickly you pick up new concepts, your current level of experience, etc.
As I mentioned at the start of the post, I researched, designed and implemented a very similar setup on my own, from scratch, without any direct help or prior experience with VMware, NetApp, networking (beyond the basics), etc. This infrastructure has now been operating for ~2 years without a single issue, so it certainly is possible to do it on your own.
On the flipside, however, it was a very time consuming process, and I don't think it would have been possible if I didn't find the technology I was learning / working with fascinating. I spent months reading and learning before I even ordered the first part, and I had the luxury of a loose implementation timeframe and the available time for me to learn as I went along.
The whole process was a great experience - I found it very interesting / challenging, learnt a massive amount, etc - so if you feel that you're up to the challenge and have the time, inclination and interest, I say give it a go.
Good luck!
Cheers,
Matt
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Matt,
Which HP switches are you using and how do you have that particular piece of the puzzle set up? I can find all sorts of documentation on setting up Cisco switches for MPIO and redundancy, but not having quite as good of luck finding proper information about my HP ProCurve 3500yls.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> Which HP switches are you using and how do you have that particular piece of the puzzle set up?
We are using ProCurve 1800-24Gs for our dedicated storage network (a bit underpowered for the job, but they work), and ProCurve 2810-24Gs for our main network core.
In both cases the two switches are configured as an independant but redundant pair to provide "failover" redundancy - we're not using MPIO.
For each pair, we connect the switches together using a two-port LACP channel, connect a network port from each of our SAN controllers (and VMware hosts) to each of the two switches in the pair (so one connection from each controller / host to each switch), and configure Data ONTAP / ESXi / whatever to use fail-over redunancy between the two network ports.
In DOT this involved creating a single-mode VIF out of the two network ports connected to each of the switches, and in VMware it's a function of assigning the two pNICs to the right vSwitches, configuring the role of each pNIC, etc.
> I can find all sorts of documentation on setting up Cisco switches for MPIO and redundancy, but not having quite as good of luck finding proper information about my HP ProCurve 3500yls.
A lot of the info out there relates to Cisco EtherChannel and stacked Cisco switches, which let you do things like connecting multiple NICs from one device to the switches, and having the multiple network links act as a single, cross-switch, aggregated and redundant link. This is nifty, but not required - you can achieve the same goal without EtherChannel / switched switches, you just have to let the devices (SAN controller, host, etc) handle the redundancy rather than the switch.
Hope that helps, despite being a bit general - happy to answer more specific questions if you have any.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the feedback Matt, the way you describe your path to your current infrastructure closely matches what I've been doing this year. In January I was planning on buying an HP\LeftHand based solution, then I almost went with EqualLogic, but after relentless digging and scouring I realized that if I could go NetApp I should.
>Is your FAS2040 single or dual controller? If the former, that's one big weak spot in your design / goal of having redundant everything - single point of failure at the SAN.
>Also, any idea how much disk I/O your VMware farm is going to produce? You don't get a lot of spindles in a base 2040, so you may run into performance issues. I'm >not saying you will have issues - our 3 server / 30 VM farm runs just fine off 17 spindles in the 2050 - but you may, depending on the I/O that you generate.
The 2040 is a dual controller model. The 2020 was actually supposed to be, but a single controller model was slipped in. Architecturally it should still suffice, but I'm working on getting my second controller for it because I want the speed and redundancy for my backup environment as well.
As to I/O, it's actually pretty low. Between the VMWare capacity planner and some perfmon captures we determined that our current peak I\O is <2500 IOPS for ALL our physicals, and that's while running backups (no longer a concern once migrated to the new environment).
>I know it is technically best practice to have a dedicated system aggregate, but it wastes too much space on a very small system like your 2040 or our 2050. You only >have 12 disks to work with, and with your current design you're losing four of them to parity and your system aggregate.
>I'd scrap the system aggr and just create a single 12-disk RAID-DP aggr (or perhaps 11-disk + 1 spare), and use that to host both vol0 and your production vols. This is >what we did with our 2050 (although we also had to dedicate some disks to the second controller, which is unavoidable).
Honestly I didn't do the 2-disk system agg because of best practice, but more because I knew I had to give one controller a few disks so it seemed a logical way to accomplish that. I really wish I could just create one 12-spindle aggregate for speed, but my understanding is that I cannot.
>Any particular reason you're using iSCSI for SQL DBs and NFS for the rest? We just used NFS for the lot.
From my research I was lead to believe that you needed iSCSI for SQL databases in order to properly quiece SQL for snapshots, or something to that effect. If SQL will run just peachy on my NFS store with everything else, I'd much prefer the simplicity.
I suppose my best bet would be to ask the community just where I would find the guides\scripts\resources I need to plug a console cable into an unconfigured 2040\2020 controller and get it up and running. I've pulled countless design\best practices docs from the NOW site, but I've yet to locate the specific instructions for that task.
Thanks again for the feedback, really helpful stuff.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> Matt the way you describe your path to your current infrastructure closely matches what I've been doing this year. In January I was planning on buying an HP\LeftHand based solution, then I almost went with EqualLogic, but after relentless digging and scouring I realized that if I could go NetApp I should.
Yet another similarity between our respective paths / infrastructures 🙂 When researching SANs I rapidly narrowedthe choice down to EqualLogic, LeftHand and NetApp, and in the end chose NetApp.
> The 2040 is a dual controller model. The 2020 was actually supposed to be, but a single controller model was slipped in.
> Architecturally it should still suffice, but I'm working on getting my second controller for it because I want the speed and redundancy for my backup environment as well.
Ahh good (that the 2040 is dual controller) - sorry, wasn't clear from your post.
Personally I wouldn't spend the money on a second controller for the backup unit - it won't make a lick of difference to speed given it would just be acting as a "passive" backup controller (due to your low number of spindles), and given the speed / quality of NetApp's warranty I'd argue you don't need redundancy in what is already a backup SAN. Up to you though, of course!
One other thought: have you bought the 2040 and the 2020 yet? If not, you might want to consider upgrading the 2020 to another 2040 as well. Reason being, the 2020 (and our 2050) won't run anything higher than Data ONTAP 7.x, as DOT 8 is 64-bit (only) and the architecture of the 2020 and 2050 is 32-bit. This will limit your 2040 to only being able to run DOT 7.x as well, because you cannot SnapMirror between a filer running DOT 8.x and a filer running DOT 7.x. Not the end of the world - DOT 7.x is fine - but you won't be able to take advantage of any new features / performance improvements / etc that are introduced in DOT 8 (and later versions).
> As to I/O, it's actually pretty low. Between the VMWare capacity planner and some perfmon captures we determined that our current peak I\O is <2500 IOPS for ALL our physicals, and that's while running backups (no longer a concern once migrated to the new environment).
It still sounds like you're still going to be pretty "close to the line" performance-wise - you have to remember that with your dual controller 2040 you're only going to have, at most, 8 active spindles (more on this below). Any idea what your peak IOPs will be without the backups?
At the end of the day I guess it can't hurt to just "suck it and see", especially if you'll be gradually migrating load onto the SAN, but you might want to make sure you have the budget to add another shelf of disks if required (or possibly down-spec the 2040 to 300GB disks and buy another shelf up front).
>I know it is technically best practice to have a dedicated system aggregate, but it wastes too much space on a very small system like your 2040 or our 2050. You only have 12 disks to work with, and with your current design you're losing four of them to parity and your system aggregate.
>I'd scrap the system aggr and just create a single 12-disk RAID-DP aggr (or perhaps 11-disk + 1 spare), and use that to host both vol0 and your production vols. This is >what we did with our 2050 (although we also had to dedicate some disks to the second controller, which is unavoidable).
> Honestly I didn't do the 2-disk system agg because of best practice, but more because I knew I had to give one controller a few disks so it seemed a logical way to accomplish that. I really wish I could just create one 12-spindle aggregate for speed, but my understanding is that I cannot.
Right, I understand what you mean now - I think we just got our wires crossed on the terminology you used.
You're basically correct: in a NetApp dual controller setup each disk is assigned to only one controller, and each controller needs a minimum of two disks assigned to it to hold that controller's system aggregate and root volume. This unfortunately means you "lose" a high percentage of your disks in a low-disk setup like the base 2020, 2040 and 2050.
With your 2040, the highest performing and most space-efficient setup you can choose will be "active / passive":
- Assign 10 disks to controller #1, and create one RAID-DP aggregate out of these. This controller / aggregate is your production data-store. Best practice says you should have 2 spares, but that is a lot (more) disks to "waste" - with the low disk count you probably want one spare at most, or possibly even none.
- Assign the remaning two disks to controller #2, and create a two-disk RAID-4 aggregate out of these. This controller / aggregate will do nothing except sit around waiting to take-over from controller #1 in case of a problem - you could put some data on this two-disk RAID-4 aggregate, but it'll be slow and you don't have a lot of redundancy here. Given the lack of production data you would use no spares on this controller to save disks.
Unfortunately, even with this setup you'll be using only 6 - 8 of your disks to store and serve actual data, depending on how many spares you use: 12 - 2 (for controller #2) - 2 (for RAID-DP parity on controller #1) - (0 to 2) (for spares on controller #1). This would be another reason to consider reducing your disks to 300GB each and buying another DS14MK4 or DS4243 upfr-ton.
> From my research I was lead to believe that you needed iSCSI for SQL databases in order to properly quiece SQL for snapshots, or something to that effect. If SQL will run just peachy on my NFS store with everything else, I'd much prefer the simplicity.
Is this when using SnapManager for SQL? If so, that is possible, I don't know anything about SnapManager for SQL.
Otherwise, AFAIK quiescing works the same regardless of whether you're using NFS, iSCSI or FC. Additionally, you could just do what we do for an extra level of protection for our SQL databases, and continue to run SQL-based disk backups on a regular basis. Gives you better point-in-time SQL recovery options than VMware / NetApp snapshots too.
> I suppose my best bet would be to ask the community just where I would find the guides\scripts\resources I need to plug a console cable into an unconfigured 2040\2020 controller and get it up and running. I've pulled countless design\best practices docs from the NOW site, but I've yet to locate the specific instructions for that task.
Have you read the actual Data ONTAP manuals? It may not be in a "do this, then this, then this" format, but the manuals cover everything you need to know.
In our case a NetApp engineer came out and spent about an hour with us to get the system up and running and do some very basic config - this service was included with the purchase of the unit. After that, it was just a matter of reading manuals and experimenting - once you get your head around the core concepts it's not too hard, and the FilerView GUI is decent for basic admin / setup tasks.
Also, setup SSH / the BMC as soon as you can, so you can ditch the console cable 🙂
> Thanks again for the feedback, really helpful stuff.
My pleasure, happy to help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Wow, really fantastic discussion here. I can tell I'm going to dig the NetApp community.
Here are a few answers to a few questions to keep it going:
strattonfinance\Matt
>One other thought: have you bought the 2040 and the 2020 yet? If not, you might want to consider upgrading the 2020 to another 2040 as well. Reason being, the 2020 (and our 2050) won't run anything >higher than Data ONTAP 7.x, as DOT 8 is 64-bit (only) and the architecture of the 2020 and 2050 is 32-bit. This will limit your 2040 to only being able to run DOT 7.x as well, because you cannot >SnapMirror between a filer running DOT 8.x and a filer running DOT 7.x. Not the end of the world - DOT 7.x is fine - but you won't be able to take advantage of any new features / performance improvements >/ etc that are introduced in DOT 8 (and later versions).
Check out the pics, I'm working on setting up my rack with them right now. Here's the deal, I BARELY, and I mean BARELY was able to squeek out the funds to do all of this anyway. My justification for even buying the 2020 was, "If we go with EqualLogic we're going to need to spend ~20-30k on a backup infrastructure, so why not let me take that 30k and grab a device that will act as both a backup environment but also the foundation for a DR site as well." If the 2020 wasn't such a fantastic value right now this would have all come apart. I knew I was going to have to deal with being "stuck" at the 7.* DOT, but I'll take that functionality over anything from the main competitors.
>It still sounds like you're still going to be pretty "close to the line" performance-wise - you have to remember that with your dual controller 2040 you're only going to have, at most, 8 active spindles >(more on this below). Any idea what your peak IOPs will be without the backups?
>At the end of the day I guess it can't hurt to just "suck it and see", especially if you'll be gradually migrating load onto the SAN, but you might want to make sure you have the budget to add another >shelf of disks if required (or possibly down-spec the 2040 to 300GB disks and buy another shelf up front).
Aside from backups our total environment should require\generate <1000 IOPS for the most part. Again, I REALLY wanted to throw another shelf of 450gb 15k SAS on this, but I needed to ditch it to get this done. If it turns out that we need to drop another 30k for a shelf of them after we start to load it up that will be do-able.
>Right, I understand what you mean now - I think we just got our wires crossed on the terminology you used.
>You're basically correct: in a NetApp dual controller setup each disk is assigned to only one controller, and each controller needs a minimum of two disks assigned to it to hold that controller's system >aggregate and root volume. This unfortunately means you "lose" a high percentage of your disks in a low-disk setup like the base 2020, 2040 and 2050.
>With your 2040, the highest performing and most space-efficient setup you can choose will be "active / passive":
>- Assign 10 disks to controller #1, and create one RAID-DP aggregate out of these. This controller / aggregate is your production data-store. Best practice says you should have 2 spares, but that is a >lot (more) disks to "waste" - with the low disk count you probably want one spare at most, or possibly even none.
>- Assign the remaning two disks to controller #2, and create a two-disk RAID-4 aggregate out of these. This controller / aggregate will do nothing except sit around waiting to take-over from controller #1 >in case of a problem - you could put some data on this two-disk RAID-4 aggregate, but it'll be slow and you don't have a lot of redundancy here. Given the lack of production data you would use no >spares on this controller to save disks.
>Unfortunately, even with this setup you'll be using only 6 - 8 of your disks to store and serve actual data, depending on how many spares you use: 12 - 2 (for controller #2) - 2 (for RAID-DP parity on >controller #1) - (0 to 2) (for spares on controller #1). This would be another reason to consider reducing your disks to 300GB each and buying another DS14MK4 or DS4243 upfr-ton.
Booya, this is what I was looking for. That's exactly how I drew up the mix before, contr1 controlling 10 disks set to raid-DP, all one agg, and contr2 controlling 2 disks set to RAID4. I guess it would be prudent to use at least one spare. Again, I'm going to do my best to get it rolling like this and then go back for another shelf if need be.
>Otherwise, AFAIK quiescing works the same regardless of whether you're using NFS, iSCSI or FC. Additionally, you could just do what we do for an extra level of protection for our SQL databases, and >continue to run SQL-based disk backups on a regular basis. Gives you better point-in-time SQL recovery options than VMware / NetApp snapshots too.
We will be using SnapManager for SQL. I just attended the "Database Bootcamp" training session yesterday, and our instructor mentioned that NetApp just released (I believe an update to SMFSQL) which will allow everything to work correctly with SQL databases mounted on VMDKs on NFS. Being able to stick everything on NFS makes it all simpler.
>Also, setup SSH / the BMC as soon as you can, so you can ditch the console cable 🙂
If I do that then how do I justify the $1200 Digi server I bought 😉
Thanks for the feedback. I'm sure I'm going to have a period of tweaking and tuning the SnapMirror schedule\throttling\etc. I'm also not entirely sure that we won't have to upgrade our WAN link to handle the traffic. I'm really really hoping that the 2020 has enough grunt to get this done. It won't be doing much of anything other being a huge backup brick. As I mentioned above, the only reason I was able to go NetApp was because of the low cost of the 2020 (and the fact that you still need to build a backup infrastructure with EqualLogic).
Thanks again everyone for your help. I'm going through the Data OnTAP Software Setup guide now.
I included a couple of pictures of this thing as it's coming together. You'll notice the worlds most ridiculously gadgety power strips (er PDUs). They even have an Ethernet connection with a web interface where you can remotely power cycle any outlet, they can be scripted and take input from UPS' to shut down devices in order, connect to environment sensors, pretty cool stuff. I got one of the switches (the bottom two switches are the storage network, 3 connections per host to that stack). 13 total NICS (including iLO) per Host (huge pain to cable)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> Check out the pics, I'm working on setting up my rack with them right now.
Looking good. I assume you're putting the 2020 on your local LAN to getting everything config'ed right, and will then move it to your DR site later?
> Here's the deal, I BARELY, and I mean BARELY was able to squeek out the funds to do all of this anyway. My justification for even buying the 2020 was, "If we go with EqualLogic we're going to need to spend ~20-30k on a backup infrastructure, so why not let me take that 30k and grab a device that will act as both a backup environment but also the foundation for a DR site as well." If the 2020 wasn't such a fantastic value right now this would have all come apart. I knew I was going to have to deal with being "stuck" at the 7.* DOT, but I'll take that functionality over anything from the main competitors.
OK, fair enough then - completely agree that being "stuck" at DOT 7.* isn't exactly an awful situation to be in 🙂 Just wanted to make sure you were aware of 2020's limitation and that you weren't going into it "blind".
> Aside from backups our total environment should require\generate <1000 IOPS for the most part.
Goodo - I'd estimate you'll be fine then.
> Booya, this is what I was looking for. That's exactly how I drew up the mix before, contr1 controlling 10 disks set to raid-DP, all one agg, and contr2 controlling 2 disks set to RAID4.
Yeah, I had trouble getting my head around how to best utilise our disks when we first installed our 2050 too... happy I could help 🙂
> I guess it would be prudent to use at least one spare. Again, I'm going to do my best to get it rolling like this and then go back for another shelf if need be.
It depends on your data / business, but I reckon I'd be inclined to skip the spare for now and get the most possible disks into "production". If/when you add another shelf you can then use one of those disks as a spare (or ideally two, as this enables the filer to put disks into the "maintenance centre" if required - read up on this in the manuals for more info).
With the combo of low disk count, RAID-DP, fast NetApp warranty replacements AND your backup 2020, the chance of data loss, even without a spare, is very, very small.
> We will be using SnapManager for SQL. I just attended the "Database Bootcamp" training session yesterday, and our instructor mentioned that NetApp just released (I believe an update to SMFSQL) which will allow everything to work correctly with SQL databases mounted on VMDKs on NFS. Being able to stick everything on NFS makes it all simpler.
Ahh, that's excellent news for you then - as you say, NFS is incredibly simple, and from our benchmarks it performs just as well as iSCSI (with NetApp filers anyway).
Have you read about / checked our SnapManager for Virtual Infrastructure (SMVI)? Great idea for Netapp+VMware farms.
> I'm also not entirely sure that we won't have to upgrade our WAN link to handle the traffic
Just FYI, this thread I started a while back may be helpful: http://communities.netapp.com/thread/7320
> 13 total NICS (including iLO) per Host (huge pain to cable)
Our network design is a little different to yours, but I feel your pain. 11 NICs per host here :-S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>> I'm also not entirely sure that we won't have to upgrade our WAN link to handle the traffic
>Just FYI, this thread I started a while back may be helpful: http://communities.netapp.com/thread/7320
I posted in that thread with more details, but if you are sketchy on your WAN link, check into Riverbed Steelheads. I can post some data reduction screenshots for SnapMirror traffic a bit later. It's pretty amazing what it can do to your replication traffic.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> I posted in that thread with more details, but if you are sketchy on your WAN link, check into Riverbed Steelheads. I can post some data reduction screenshots for SnapMirror traffic a bit later. It's pretty amazing what it can do to your replication traffic.
Interesting info, thanks for contributing.
Have you compared how the Steelheads perform vs native DOT compression of SnapMirror transfer sets?
Would be very interested to the see the data reduction info you referred to if you don't mind posting them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
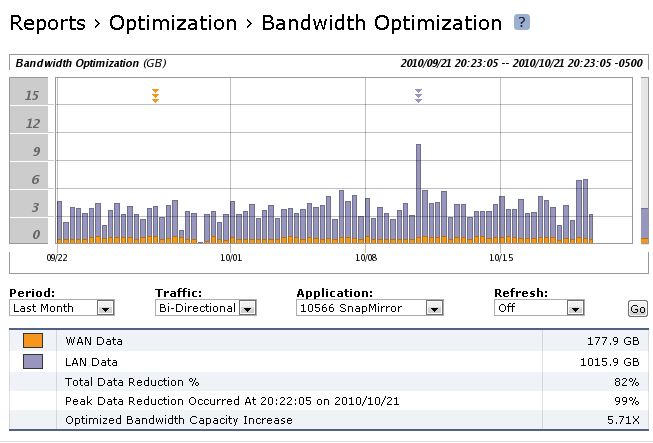
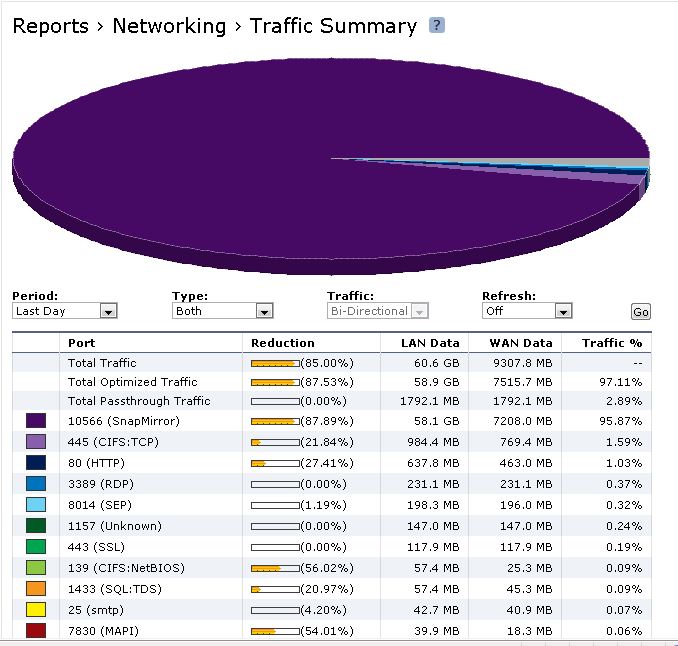
I have had the Steelheads in place since I started using SnapMirror replication, and I've only just started upgrading to DOT 7.3.3 where compression is enabled. So I haven't tested native DOT compression with my scenario and I won't be enabling it as the DOT compression will interfere with the Steelhead's ability to do data reduction on the SnapMirror stream, or so Riverbed says.
Some screen shots from my Riverbed are attached. It's pretty easy to see the reduction I'm getting from this both today and over time. Looking at the last 2 screenshots you can see that the vast majority of my WAN traffic is SnapMirror. Keep in mind that I have a total of 6 sites interconnected with this MPLS, all sites are 1.5mb/s currently, and only 2 of the sites have Steelheads and NetApps. The CIFS optimization you see applies in part to the NetApp also. The Steelheads also do a great job on Outlook traffic and JetDirect (port 9100) printing. The SnapMirror traffic is flowing over the same WAN as our regular traffic, but is on a separate VLAN and I use the QoS built into Steelheads to keep the SnapMirror traffic from flooding the WAN during the day.
All this being said, as great as the Steelheads are at optimizing SnapMirror traffic I'm reaching the limits of what 1.5mb/s can do and plan to upgrade a couple of WAN links and move some Steelheads around soon so that I have 3mb/s at both sites that have NetApps and put Steelheads at 4 out of my 6 locations.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You have two bottlenecks you might run into with the current setup:
1. CPU Redline
2. Disk utilization
3. Disk RPM for DR
From my experience the FAS2050/FAS2020 can serve data well as long as it doesn't have to doing anything else. These are single CPU storage controllers and red line CPU easily when additional tasks are given to them. The FAS2040 is more powerful so I'm not sure of performance when having to handle multiple tasks.
A full shelf of 15k drives can produce the IO you are looking for. However, the DR site could have issues keeping up with SnapMirror traffic because of the high load from snapshot clean up. This is depends on the number and size of volumes you snapmirror and the frequency you update. Everytime you update a snapmirror relationships you kick off a back ground processes to update the inodes.
I had problems with the following until I upgraded
FAS2050 with two shelves of 300 FC - Production
FAS2050 with 14 1TB SATA - DR
We deployed 40 Virtual Machines on 4 Volumes runing on Hyper-V
Exchange CCR Volumes
Multiple SQL DB Volumes
We were updating snapmirror hourly for databaes and daily for Virtual Machines volumes
We were also deduping virtual machine data daily
The result was 75% CPU utilization for production and 90% disk utlization for DR.
-Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> From my experience the FAS2050/FAS2020 can serve data well as long as it doesn't have to doing anything else. These are single CPU storage controllers and red line CPU easily when additional tasks are given to them.
I can certainly attest to that as well - very easy to max the CPU on our 2050.
> The FAS2040 is more powerful so I'm not sure of performance when having to handle multiple tasks.
I'm pretty sure the 2040 is dual-core, so it should handle multiple concurrent tasks much better. One of the many reasons I wish it was around when we bought our 2050 :-S
> I had problems with the following until I upgraded
>
> FAS2050 with two shelves of 300 FC - Production
> FAS2050 with 14 1TB SATA - DR
>
> We deployed 40 Virtual Machines on 4 Volumes runing on Hyper-V
> Exchange CCR Volumes
> Multiple SQL DB Volumes
>
> We were updating snapmirror hourly for databaes and daily for Virtual Machines volumes
> We were also deduping virtual machine data daily
>
> The result was 75% CPU utilization for production and 90% disk utlization for DR.
Wow, SnapMirror must produce a massive amount CPU and disk load then. Our current environment is vaguely similar the one you describe (2050, 40-odd VMs, SQL DBs, daily dedupe, etc) except we don't use SnapMirror, and our 2050's average CPU load wouldn't be any higher than 20%.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}