Stay connected during the transition - Join our Discord community today.
ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: SSD Scrubbing on Netapp AFF systems
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello. I'd like to understand deeper about SSD scrubbing. Tried to read up online. Understand the concept and stuff but couldn't find enough information about how exactly Netapp handles it.
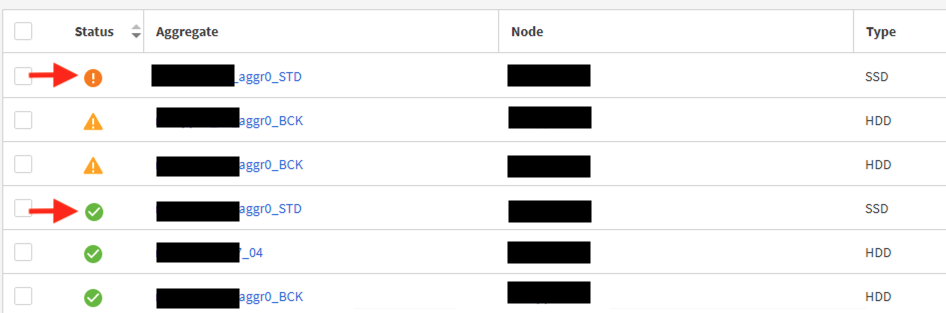
We have a netapp with two aggregates that are fully flash. The one with more volume count, more IO load seems to be not complaining on the AIQUM. It shows up as green but the other aggregate with more free space, lesser volumes compared to the former and less IO overall seems to show up with a warning symbol that its performance level is over loaded.
This looked strange and the only difference I could see is that the later had its scrubbing schedule run more than 6 months ago, the former ran last month. Nothing else seem different. Any help advice on how to navigate and find the problem would be much appreciated. Thanks!
Solved! See The Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So the "other" aggregate is named aggr0. I can safely assume that is likely your root aggregate. RAID scrubs are simply a read of every block from A-Z that cycles and runs daily. https://kb.netapp.com/Advice_and_Troubleshooting/Data_Storage_Software/ONTAP_OS/What_are_the_important_changes_to_RAID_scrub_in_Data_ONTAP_8.3.x_or_la...
UM is just saying "your disk performance is terrible and overloaded" but it apparently isn't being smart enough to know it's raid scrubs. This should be an informational alert at best. Nothing is wrong here.
Please open a case against UM so we can file a bug. If you want, link this thread with it. I can't find a bug right off.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So the "other" aggregate is named aggr0. I can safely assume that is likely your root aggregate. RAID scrubs are simply a read of every block from A-Z that cycles and runs daily. https://kb.netapp.com/Advice_and_Troubleshooting/Data_Storage_Software/ONTAP_OS/What_are_the_important_changes_to_RAID_scrub_in_Data_ONTAP_8.3.x_or_la...
UM is just saying "your disk performance is terrible and overloaded" but it apparently isn't being smart enough to know it's raid scrubs. This should be an informational alert at best. Nothing is wrong here.
Please open a case against UM so we can file a bug. If you want, link this thread with it. I can't find a bug right off.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I didn't know if it was ok to share the aggregate and netapp names. That is why I hid them. But the aggregates in concern here aren't root aggregates. They are standard aggregates serving data to customers consisting of only SSD disks. But I hear your opinion. I can open a case and ask if it can be registered as a bug. Will reference this page and also will post the ticket number here for your reference. Thanks!.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Case number 2008611448 . For your reference
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you. I see your case. You've got 4 nodes (3-6), which nodes have the aggregates with the alert?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
netapp06_04_aggr0_STD and netapp06_03_aggr0_STD. Both SSD aggregates serving data.

{kind=link}