Stay connected during the transition - Join our Discord community today.
VMware Solutions Discussions
- Home
- :
- Virtualization Environments
- :
- VMware Solutions Discussions
- :
- Re: Thin Provisioned LUN not showing true space usage
VMware Solutions Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi. I've implemented thin provisioing for a customer's VMWare VMFS datastore LUNS. Everything in the beginning was working as expected. The space that was actually being written to (i.e. add a 30GB VM to the datastore) was being reflected on the filer. I could see this through the following command:
aggr show_space -g
The allocated and used space would be identical - as expected. Now, let's say I created that thin provisioned LUN to be 350GB. ESX would think it's getting a 350GB LUN and my space used on the filer would state 0% used. It's only as I start adding VM's does this increase the %used space...fine.
Now, let's say I've added enough VM's that the entire 350GB is used up. When I run the aggr show_space command I see 350GB allocated, 350GB used - that's fine.
Now, I vmotion a bunch of VM's from that datastore to a different datastore, leaving 100GB of VM's on the original datastore. If I take a look at the ESX datastore I now see that out of the 350GB allocated, I have 100GB used and 250GB free - nice. BUT, when I take a look at the filer and run the aggr space_show -g, I still see 350GB allocated, 350GB used - even though from a VMFS perspective this is not the case.
I'm assuming this is the same issue that I've faced before with WAFL not knowing what's happening within VMFS when VMFS frees up space. WAFL doesn't own the VMFS so it can't reflect the changes that VMFS makes when it "deletes/moves" files.
The Space Reclaimer is a nice tool that is used within Snapdrive to reclaim blocks that have been "freed", essentially passing this information to WAFL so it knows how to update the space metrics. My question (and my client's question) is how do I reclaim that space on the filer AFTER the thin provisioinmed LUN has reached a certain size and then decreases - either because a VM was destroyed or a vmotion moved it to another datastore. It would be nice if there was some Space Reclaimer feature within ESX whereby I could either manually invoke or schedule it to run against a VMFS datastore.
I know that there is now the Virtual Storage Console - a vCenter snap-in. I wonder if space reclaimer could be added to that? Seems like the perfect place to put it.
Does anyone have any suggestions as to this dilema?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Interesting dilemma. Have you got snapshots by any chance? They might need to rotate out to decrease space utilisation first.
Eric
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi. This is an astute observation (IMHO). One thing to note is that there is more to the space reclamation process than simply space accounting w/in the controller. In any case, a space reclaimer for VMFS is an excellent feature request. Thank you for starting this discussion.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for those links to the Virtual Storage Guy articles. They were great. Here's to hoping that Space Reclaimer for datastores will be a reality in the next Virtual Storage Console release
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is there a place where we can vote for this possible feature? I am running into the same issue. My resolution is to create another lun off the original volume, create a new datastore (VMFS), move the files, then delete the orginal lun and datastore. Its a lot of work but I get alot of space back.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I also have a customer that's running into this issue, and frankly I'm surprised more folks aren't seeing this. I'm curious about anybody else that's seeing this and how they are dealing with it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm not sure if this is a result of the same issue or not, but I was wondering why VSC reports different volume % used than NetApp system manager.
See the tier1_sap_prod volume for example...350GB LUN. Under capacity it shows volume usage: 62%.
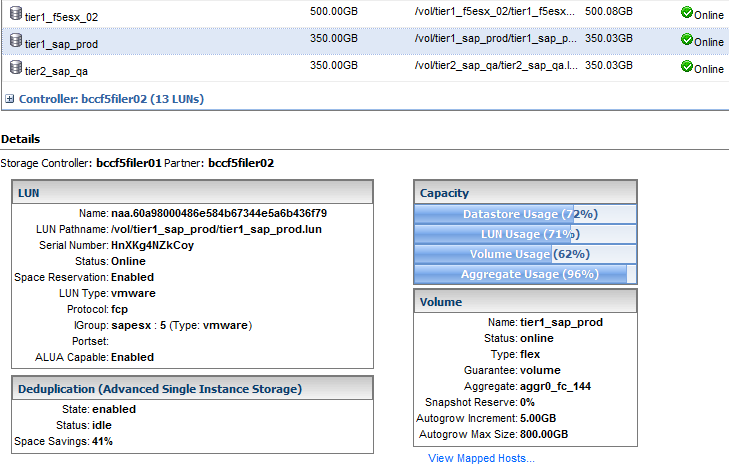
Now, in System Manager...it reports the same volume is 48% used.

Why? Shouldn't they report the same?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is it possible to write zeros to the empty space and dedupe it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Even if you write zero to free space you will not be able to use all the free space, AFAIK maximum share which dedupe can handle is in 255:1 block ratio. A lot but not as efficient as free space reclaimer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Have you a documentation link by chance to this 255:1 ratio?
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
FYI, as of Data ONTAP 8.1 the max dedupe ratio per block went to 32767:1. The Data ONTAP storage efficiency admin guide contains this information.
Regarding the original question, in ESX 5.0 VMware introduced the ability to "unmap" unused blocks in the VMFS filesystem. So if you were to storage vMotion a VM out of a VMFS datastore you can then run a command to ask ESX to inform the storage system that specific blocks on the LUN are no longer in use.
The steps to do this are here:
Keep in mind that when using deduplication, for any shared blocks the "unmap" will have no net effect on used physical capacity. Basically the reference count for the data block will get decremented but the block itself can't be freed up since some other logical block still depends on it. For unique data (i.e. a block that wasn't shared) the unmap will cause a decreased in used physical capacity as you'd expect.
Hope that helps!
Regards
Chris Madden
Storage Architect, NetApp EMEA
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes. I've had many customers point out this tool for windows:
