This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
VMware Solutions Discussions
- Home
- :
- Virtualization Environments
- :
- VMware Solutions Discussions
- :
- Using e0M as Cluster Management Interface port ?
VMware Solutions Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
We are configuring a FAS6280 in cluster mode. When we created the cluster on first node, we choosed e0M as cluster management interface port. It works well. In case of HA failover, the cluster_mgmt is linked to a0a, a data ifgrp and not e0M on the second node. We can't do a migrate to node2/e0M. But it works with node2/a0a which is not connected to network admin switch...
stor-dc1-c105::*> network interface show -failover
Logical Home Failover Failover
Vserver Interface Node:Port Group Usage Group
-------- --------------- --------------------- --------------- ---------------
SVshared
SVshared_lif1 stor-dc1-c105-01:a0a system-defined
Failover Targets: stor-dc1-c105-01:a0a,
stor-dc1-c105-01:e0M,
stor-dc1-c105-01:e0c,
stor-dc1-c105-01:e0f,
stor-dc1-c105-01:e5a,
stor-dc1-c105-01:e5b,
stor-dc1-c105-01:e7a,
stor-dc1-c105-01:e7b,
stor-dc1-c105-02:a0a,
stor-dc1-c105-02:e0c,
stor-dc1-c105-02:e0e,
stor-dc1-c105-02:e0f,
stor-dc1-c105-02:e5a,
stor-dc1-c105-02:e5b,
stor-dc1-c105-02:e7a,
stor-dc1-c105-02:e7b
stor-dc1-c105
cluster_mgmt stor-dc1-c105-01:e0M enabled clusterwide
Failover Targets: stor-dc1-c105-01:e0M,
stor-dc1-c105-02:a0a
stor-dc1-c105-01
clus1 stor-dc1-c105-01:e0d system-defined
mgmt1 stor-dc1-c105-01:e0M disabled
Failover Targets: stor-dc1-c105-01:e0M
stor-dc1-c105-02
clus1 stor-dc1-c105-02:e0d system-defined
mgmt1 stor-dc1-c105-02:e0M disabled
Failover Targets: stor-dc1-c105-02:e0M
the command to migrate the port to node2/e0M fails :
stor-dc1-c105::*> network interface migrate -vserver stor-dc1-c105 -lif cluster_mgmt -source-node stor-dc1-c105-01 -dest-node stor-dc1-c105-02 -dest-port e0M
Error: command failed: Failed to migrate interface stor-dc1-c105;cluster_mgmt.
migrate: invalid port.
stor-dc1-c105::*> network interface show
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
SVshared
SVshared_lif1
up/up 10.1.4.61/22 stor-dc1-c105-02
a0a false
stor-dc1-c105
cluster_mgmt up/up 10.1.0.70/22 stor-dc1-c105-01
e0M true
stor-dc1-c105-01
clus1 up/up 192.168.192.101/24 stor-dc1-c105-01
e0d true
mgmt1 up/up 10.1.0.68/22 stor-dc1-c105-01
e0M true
stor-dc1-c105-02
clus1 up/up 192.168.192.102/24 stor-dc1-c105-02
e0d true
mgmt1 up/up 10.1.0.69/22 stor-dc1-c105-02
e0M true
We find that e0M on node1 has data role whereas node2 has node-mgmt role
stor-dc1-c105::*> network port show
Auto-Negot Duplex Speed (Mbps)
Node Port Role Link MTU Admin/Oper Admin/Oper Admin/Oper
------ ------ ------------ ---- ----- ----------- ---------- ------------
stor-dc1-c105-01
a0a data up 1500 true/- auto/full auto/1000
e0M data up 1500 true/true full/full auto/100
e0a data up 1500 true/true full/full auto/1000
e0b data up 1500 true/true full/full auto/1000
e0c data down 1500 true/true full/half auto/10
e0d cluster up 9000 true/true full/full auto/10000
e0e cluster down 9000 true/true full/full auto/10000
e0f data down 1500 true/true full/half auto/10
e5a data down 1500 true/true full/half auto/10
e5b data down 1500 true/true full/half auto/10
e7a data down 1500 true/true full/half auto/10
e7b data down 1500 true/true full/half auto/10
stor-dc1-c105-02
a0a data up 1500 true/- auto/full auto/1000
e0M node-mgmt up 1500 true/true full/full auto/100
e0a data up 1500 true/true full/full auto/1000
e0b data up 1500 true/true full/full auto/1000
e0c data down 1500 true/true full/half auto/10
e0d cluster up 9000 true/true full/full auto/10000
e0e data up 1500 true/true full/full auto/10000
e0f data down 1500 true/true full/half auto/10
e5a data down 1500 true/true full/half auto/10
e5b data down 1500 true/true full/half auto/10
e7a data down 1500 true/true full/half auto/10
e7b data down 1500 true/true full/half auto/10
Is there a solution ? Does someone else use e0M as cluster management interface port ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Should be no problem, though usually I prefer to use one of the onboard 1gb ethernet ports (e.g. e0a) for the management traffic (it's faster), and have e0M as a failover target. Can you try 'net port modify -node stor-dc1-c105-02 -port e0M -role data' ?
Don't forget to create a failover group for SVshared
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your answer. I already tried this. You can see the return below :
stor-dc1-c105::> net port modify -node stor-dc1-c105-02 -port e0M -role data
(network port modify)
Error: command failed: Can't change the role of a port that is assigned to a
lif.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Then it's a bit more complicated. You should move the node management lif (mgmt1) on stor-dc1-c105-02 to another interface, then you should be able to change the role...
But I strongly suggest that you have two ports in a failover group for the node management. Node management is not just for connections from management console or ssh. For sure it is responsible for sending the autosupports, and I know that in previous versions it was used for some other tasks like NTP time synchronization and AD lookups (that may have been changed in recent versions, I am not sure). 62xx is a serious system for serious people, don't make it less reliable than it could be.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
It's not already in production. We will receive 2 x 10GbE switches in 3 weeks. We try to configure it to learn C-mode. We will decide in 3 weeks if we continue with 7-mode in our datacenter or if we change for C-mode.
So, for my test, i have only e0M/SP (100Mb/s) connected to an admin switch and i created an ifgrp in single mode with e0a and e0b for "data" link. All is fine, exept the fact that i loose cluster management when i do an HA/takeover. Data failover on the good ifgrp even if, as you said, i should create a failover group. I use an ESXi with a VM to test client side.
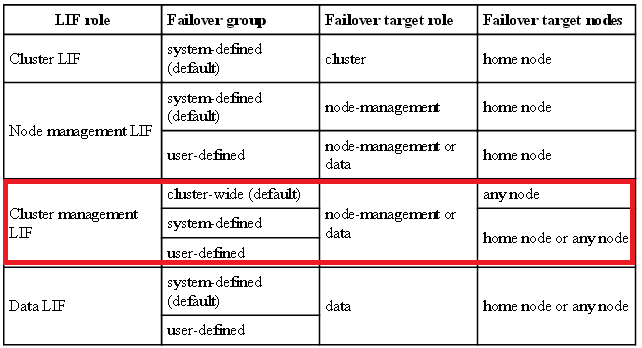
So i'm going to try to add another port to node-management to see if i can change role of e0M. It's just strange that the documentation shows that the cluster management LIF could have a failover target role of node-management or data. If it was true, it should work even if it's not the best setup.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your output in the original post is a little bit odd. The clusterwide failover group is supposed to contain all data lifs. Not sure why it is different on your system, I would check with NetApp support on that.
Anyway, I usually create a failover group for every function, so that I have full control of where the lif could migrate. That includes one failover group for each node management lif, one of cluster management, and one or more for data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree with Mikhail. I try to never use e0M and only use the physical port for SP. The good news on 6200 is that the e0M is now gigabit as well but it doesn't support VLAN tags.. ideally I use the gigabit ports e0a/e0b or a VLAN on the 10GbE NICs. We can also have secondary cluster and node management interfaces so additional lifs if a customer wants to keep e0M then you can also use the other interfaces as well...one other good reason to not use e0M or to use secondary management is NDMP over the network and since FAS3200 e0M are 100Mbit good to have gigabit or 10 gigabit.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
At this moment, we can only use e0M for cluster management. My question is why node1/e0M has data role and node2/e0M has a node-mgmt role. In data ontap c-mode documentation, cluster_mgmt could failover on data or node-mgmt role lif.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Scott,
Are you sure that e0M is now gigabit? I think it still was 100Mbit/s on 6280, don't know about 6250...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Last 6200 I installed was GbE…but depends on when manufactured. It wasn’t advertised but found out trying it out. It may vary but in any new systems you get 6250/6290 it is gigabit. The 6280s I installed mid/late last year also had GbE for e0M. Not listed as GbE but worked at gigabit when plugged in. SP is still 100MBIT though behind that prot.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Scott. Good to know.
