This site will enter Read Only mode on July 23 as we prepare to move to a new platform.
You will still be able to view content, but posting and replying will be temporarily disabled.
To learn more, please review the information in this blog post.
VMware Solutions Discussions
- Home
- :
- Virtualization Environments
- :
- VMware Solutions Discussions
- :
- sis status - searched amount more than vol size
VMware Solutions Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was noticing something today when running a dedupe job on one of our volumes and it was that the Progress column showed "xxxxGB Searched" where the size of the amount searched far exceeded the size of the volume. The volume is about 2.5TB but the search value got all the way up over 6000GB. I've included a screen cap to show. I'm just wondering if anyone can explain why this is?
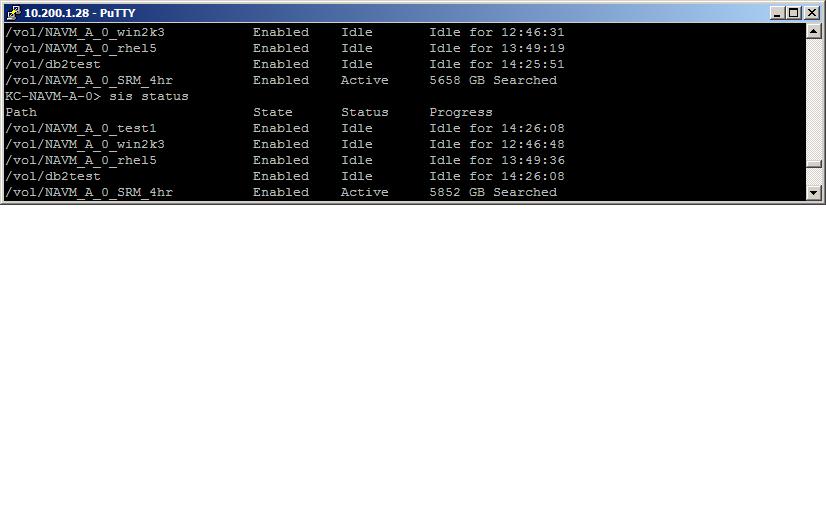
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am having the exact same issue. It is causing my dedupe jobs to run during the day instead of finishing overnight. Did you get this resolved?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm probably going to open a case up with support tomorrow and see if they have any idea why it's doing this. We recently upgraded from 8.0.2 to 8.1.2 and I know there were some pretty big changes made in the dedupe processing so I'm wondering if something changed somewhere. I'll update when I hear something back.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We have the same problem, did you solved this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Has anyone seen this, or heard that it still exists in 8.1.3? Is there a bug number that we can reference with support as we work our issue that seems similar?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you include a df and df -s for the volume?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am seeing the same thing when running a dedupe on a volume. Did anyone from NetApp answer your question?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry for abandoning this for so long and not updating our experiences...
Supposedly there is a internal bug for this issue. The only thing Support has recommended doing was to run a "sis start -s" command on the volume so that rescans and re-initializing all of the thumbprint information. We've done that a few times to some of the volumes experiencing this problem and it's provided a temporary reprieve for at least a while. One of the volumes is now experiencing ridiculously long dedupe times and we aren't sure why. All of these problems have surfaced after we upgraded from 8.0.x to 8.1.x.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the quick response. I’m seeing similar symptoms. I started out trying to fix a “sis.changelog.full:warning” and that has led me here.
PT
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is good info. I'm having similar issues. Did you happen to get a bug number for this issue?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi.
"sis start -s" has helped me.
I had seen some larger than expected disk space usage on a 6280 and have seen the issue that the OP mentioned. Our disk space usage have been going up much faster than expected and in retrospect I had noticed that deduplication efficiency on vmWare datastores was less than impressive on this filer.
So I tried to stop SIS on all the volumes and started with the -s.
When I restarted them about 24 hours ago, we had 15TB free disk space from a total of 83TB on that filer.
Now it is up to 24TB free and it is not done yet with scanning. I am looking forward to see the end result after the weekend.
(I have looked at wafl scan status and didn't see any container block reclamations or the likes)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Interesting. I also had space recover during the "scanning" phase when I finally decided to run "sis start -s". On a 14TB volume it went from 88% used to 68%, and on a 8.4TB volume it went from 86% used to 78%.
I'm curious to hear what your results are after sis finishes. For us, the percent saved from dedup reported didn't change more than a percent or two. (This is on a 3240 running 8.1.1 in 7-mode).
In the meantime, I have an open case related to this issue, and I've asked the engineer to take a look at this thread and see if it rings any bells with him regarding any open issues. I'll report back anything of use that comes from that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
After the weekend I now can see that all all sis status are idle, with the exception of one that has run amok. So I will reset that one again.
I gained quite a lot more free space. Our aggregate was 80% full(which was the reason that prompted me to look into it into it). During the weekend we have gained another 7TB of free space so the aggregate are now only 62% full.
Accoring to sysstat we had a disk utilization of up to 80-90% with up to 1 gigabyte read pr. second and I could see that only 200 megabytes of that went to CIFS/NFS/FC IO so the rest must have been internal from SIS jobs, now we are down to 30%-50% utilization which makes sense since only one SIS job are running. I seems to have almost halved the number of IOPS from 38.000 to 20.000.
It has been a long time since I last saw that all SIS jobs had a idle status on that filer.
Now I guess I have to go though the other filers as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So after talking to the engineer on my case, it would appear that this bug is the cause of the behaviour I've seen and sounds a lot like what martinrudjakobsen saw: http://support.netapp.com/cgi-bin/bol?Type=Detail&Display=657692
There's also another SIS related bug that I don't think I've hit, but sounds like it may relate to some of the other folks in this thread: http://support.netapp.com/NOW/cgi-bin/bol?Type=Detail&Display=681095
Hope this helps.
