This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
ONTAP Discussions
- Home
- :
- ONTAP, AFF, and FAS
- :
- ONTAP Discussions
- :
- Re: Disk Busy 100% without much I/O activity
ONTAP Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello everybody,
Could someone help us diagnose root cause of the problem with our FAS3170? ONTAP 8.1.2 7-mode, we have a single 1TB SATA disk shelf, configured with one aggregate. Aggregate utilization is less than 45%, there are several thin provisioned volumes, volumes are less than 70% full as well.
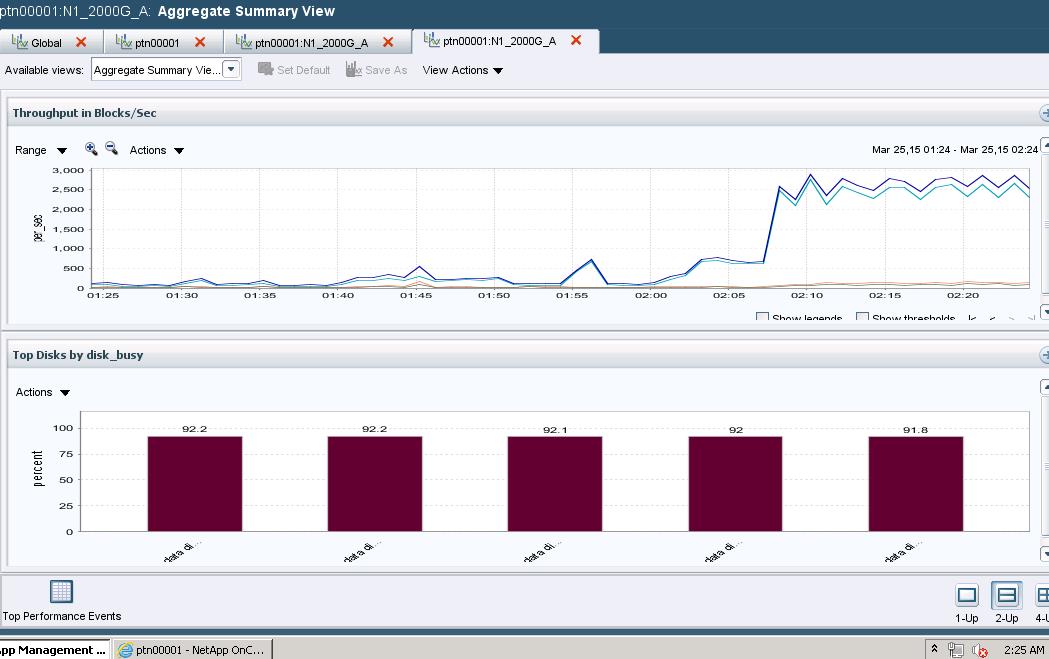
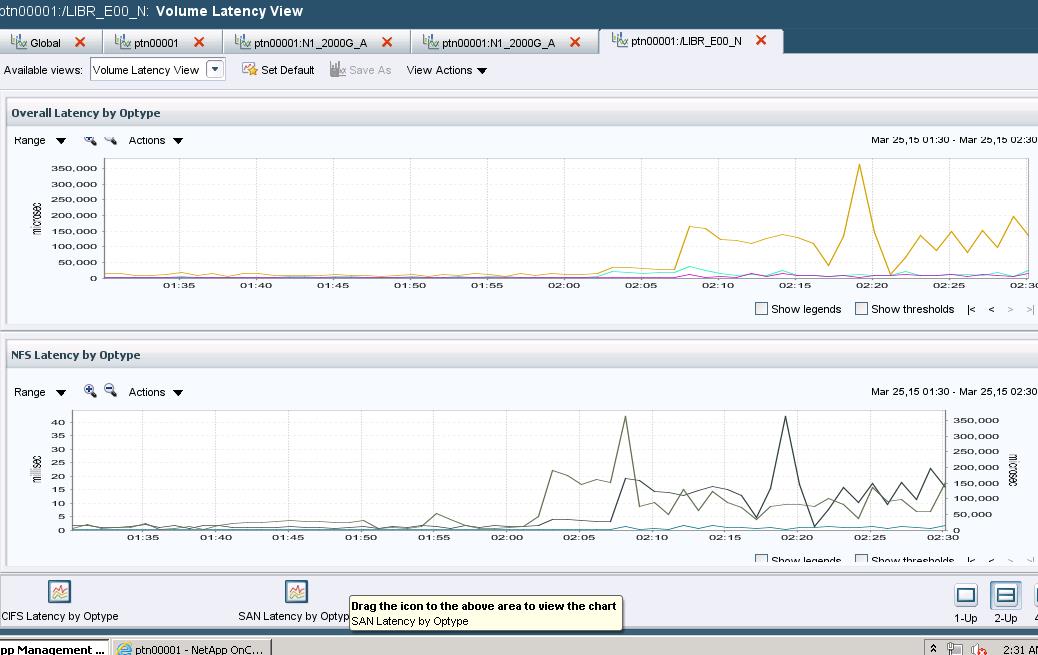
The problem is that from time to time, disks on the aggregate are busy 99-100% (see below) and access time is hitting 300-700ms (see attached screenshots), making all our VMs running from the volumes pretty much non-workable.
disk:50000C90:001D0E64:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:8%
disk:50000C90:001D2A34:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:11%
disk:50000C90:001D1F40:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001DD5DC:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001D0D84:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:99%
disk:50000C90:001D1E78:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001D1B9C:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001DE5F8:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:99%
disk:50000C90:001DFDCC:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:94%
disk:50000C90:001D0C98:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:97%
disk:50000C90:001DE004:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:94%
disk:50000C90:001DEF90:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001DD5A8:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001DE208:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001DDE1C:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:0%
disk:50000C90:001DD560:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:0%
disk:50000C90:001D29D0:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001D0CF8:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:100%
disk:50000C90:001D0E18:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:97%
disk:50000C90:001D1F60:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:99%
disk:50000C90:001D185C:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:99%
disk:50000C90:001D1FAC:00000000:00000000:00000000:00000000:00000000:00000000:00000000:00000000:disk_busy:97%
I need just one thing - find out what causes 100% disk busy using ONTAP's or third-party tools. I turned off dedup, there is no snapmirror activity, no WAFL scans, no realloc, there are no high IO/s from VMs or some other places - still have no f-ing idea why disks are so busy.
Any help? Tickets opened at netapp support were useless, they told us that the system is too old and it is expected to have such kind of behaviour with SATA shelves...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
if you are willing to collect and send me a perfstat file (while the disks are 100%) I might be able to help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sure, do you need them with some specific settings?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
just sent you a private message with the details
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Could you find a solution for this issue? We have the same issue with a FAS3250, 4TB Disk, OnTap 8.1.4P8 7-Mode. Disk utilizations runs really high each morning for approx. 5 hours.
Regards
SaPu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Are you checking it from sysstat ? It will give you the busiest disk as it only gives you the busiest CPU.
Go to advanced mode.
*> statit -b
Then wait for one minute
*>statit -e
To stop statit collection and dump data.
*>priv set
Now check the disk utilization in disk/aggregate section which will give the values for every disk.
Refer below document if you need help in running those stats.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well the best solution is to add more disks... In our case it was determined that we simply did not have enough disks. After we moved flash cache cards from another filer, situation got better.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
+1 for disk scrub. Default duration is 6 hours

{kind=link}
{kind=link}