This site will enter Read Only mode on July 23 as we prepare to move to a new platform. You will still be able to view content, but posting and replying will be temporarily disabled.
We're excited to launch our new Community experience on July 30 and more information will follow soon.
Stay connected during the transition - Join our Discord community today.
VMware Solutions Discussions
- Home
- :
- Virtualization Environments
- :
- VMware Solutions Discussions
- :
- How to determine which VM's (NFS files) are contributing the most to snapshot deltas?
VMware Solutions Discussions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to determine which VM's (NFS files) are contributing the most to snapshot deltas?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi - we have a 3.5Tb NFS datastore running about 30 vmware virtual machines.
We try to maintain 21 days of daily netapp snapshots, but lately the daily deltas are > 100gb/day and its becoming challenging to keep 21 days without growing the volume.
(the data:snapshot space ratio is about 1:2 - the snapshots take twice as much space as the actual VM images - and this is with dedup ON)
How can we best determine which set of the VMs is contributing the most to the daily snapshot delta (that 100Gb)?
Armed with this information we can then make decisions about potentially storage vMotioning VMs to other datastores to meet the 21day retention SLA.
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just curious, are you doing the snapshots after the dedupe? Ideally you dedupe then take the daily snapshots. That will keep any of the duplicate blocks out of the snaps.
Usually when this happens it is a DB server doing a dump to a local disk or some sort of defrag running in a VM. Any of those?
Keith
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We're doing nightly snapshots which by default (can you change the timing of nightly snaps?) happen at midnight.
Dedup for this volume was schduled for midnight as well
I've moved the dedup to 10pm and we'll see if this helps
There has to be a way to tell which files (VMs) are contributing the most to snap deltas - if Netapp is serious about being a cloud storage solution they need a tool for guaging this
I don't have an obvious VM like DB or defrag
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm not sure how to determine the growth per VM in the datastore but did have a couple other things come to mind. First you said the datastore was 3.5TB and had 30 VMs. How much of the 3.5TB is the VMs themselves? I'm just wondering what the average VM size is.
Also do you know if any of the VMs are swaping to disk? That is, what is the memory utilization on your ESX hosts like?
Are you doing any storage VMotion activity?
Keith
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Keith brings up some really key questions that make me wonder if there may be a better way to optimize your use of the storage. So from what has been said so far, I understand it that you have a 3.5TB single-datastore backed by a roughly 10.5TB volume. That is 3.5TB + (datastore size * 2 for snapshot reserve) = ~10.5TB volume.
So dedupe has some limitations based on the controller model you are using and the version of DOT you are running. I would look to be sure that your config is not exceeding any limitations.
Secondly, dedupe for virtual environments is typically best acheived where lots of the same OS, and only the OS disks, is stored on the same datastore. While it sounds like you may in fact have that going for you here, you are also mixing the data the VM's are responsible for on the same datastore as the OS's. Perhaps if you were to migrate the OS vmdk's to their own datastore with dedupe enabled you could save some space there. Then, depending on the data types and applications you are using on the various VM's, you could create multiple datastores to house the similar data types keeping the fundamental capabilities of the dedupe feature and your needs for recovery of the data in mind all the while.
Using more than one datastore in VMware is one of those things that sounds and looks uglier than it is. In many cases it is a necessity for data protection and performance. Especially when you start talking virtualized Oracle DB's.
So circling back to the math we did earlier. Let's say you are running Windows 2008 R2 across the board (wouldn't we all love things to be that simple!). That could mean that you have 30 VM's with an average of 30GB's or so per OS instance in just the OS disks; that is ~900GB in full non-deduplicated storage. If all of the vmdk's for the OS's that add up to this amount are stored in one datastore with dedupe enabled, you stand to experience a *substantial* dedupe rate. I will defer you to TR-3505 for estimations on the rate though. Let's just say for the fun of it that you score an 80% dedupe rate...I believe that is actually fair. At that rate, you stand to save 720GB right there.
So you can start to see how layout of the storage you use can have a substantial effect on how much savings you glean from the enhanced technologies in the array. Let us know what you decide to do and how this all pans out. We are rooting for you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Keith, thanks for the tip on scheduling the dedup BEFORE the nightly snapshots - I moved the dedup job up 2 hours before the midnight snapshots:
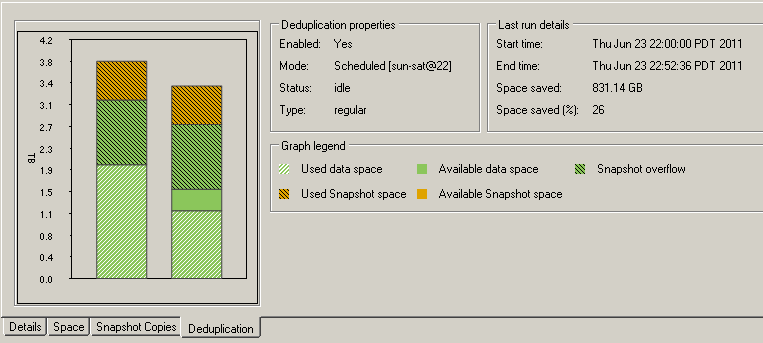
Its too early to tell for sure, but last night's snapdelta 47.48Gb (as reported by filerview) was less than half the pre-schedule change deltas:
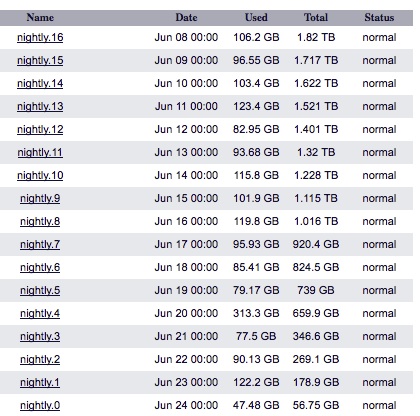
On this volume we have 94 VM images with an average of 22Gb per VM used:
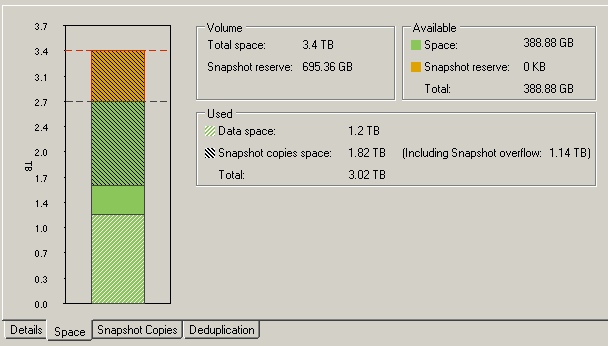
I moved the dedup job up for our 2nd biggest VM volume to see if the snap delta reduction is realized there too
Our goal is to be able to retain more daily snaps in the same space
thanks!
